






学号15
numpy基础用法
基本函数介绍:
数组创建(如numpy.array(), numpy.zeros(), numpy.ones()等)。
数组索引和切片。
数组运算(元素级、广播等)。
线性代数操作(如矩阵乘法、特征值和特征向量等)。
具体问题解决:
示例:使用numpy解决线性方程组。
import numpy as np
from numpy.linalg import solve # 解线性方程
a = np.mat([[2, 3], [1, 3]])#系数矩阵
b = np.mat([5, 3]).T #常数项列矩阵
x = solve(a, b) #方程组的解
print(x)
示例:计算数组中的最大值、最小值、平均值等统计量。
import numpy as np
a = np.array([[1,2,3,3],[4,5,6,2],[0,8,4,9]])
print(a.max()) #获取整个矩阵的最大值 结果:9
print(a.min()) #获取整个矩阵的最小值 结果: 0
# 可以指定关键字参数axis来获得行最大(小)值或列最大(小)值
# axis=0 行方向最大(小)值,即获得每列的最大(小)值
# axis=1 列方向最大(小)值,即获得每行的最大(小)值
# 例如
print(a.max(axis=0)) #[4 8 6 9]
print(a.max(axis=1))#[3 6 9]
#返回的是位置(索引)
print(a.argmax(axis=0)) #[1 2 1 2]
scipy高级功能
基本函数介绍:
scipy中的特殊函数(如积分、优化、插值等)。
scipy.stats中的统计函数和分布。
scipy.signal中的信号处理功能。
具体问题解决:
示例:使用scipy.optimize求解非线性优化问题。
from scipy.optimize import differential_evolution, basinhopping
def fun_nonconvex(x):
if x<0:
return ( x + 2 ) ** 2 + 1
else:
return ( x - 2 ) ** 2 + 2
res_differential_evolution = differential_evolution(func=fun_nonconvex, bounds=[(-10,10)])
print('differential_evolution()的结果为:\n', res_differential_evolution)
res_basinhopping = basinhopping(func=fun_nonconvex, x0=0, niter=1000)
print('\n basinhopping()的结果为:\n', res_basinhopping)
示例:使用scipy.stats进行对统计量与拟合的概率分布进行可视化对比。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm, expon, poisson, kstest
# 示例数据
data_normal = np.random.normal(loc=0, scale=1, size=1000)
data_expon = np.random.exponential(scale=1, size=1000)
data_poisson = np.random.poisson(lam=5, size=1000)
params_normal = norm.fit(data_normal)
params_expon = expon.fit(data_expon, floc=0)
params_poisson = (np.mean(data_poisson),)
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.hist(data_normal, bins=30, density=True, alpha=0.6, color='g')
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, *params_normal)
plt.plot(x, p, 'k', linewidth=2)
title = "Fit results: mean = {:.2f}, std = {:.2f}".format(*params_normal)
plt.title(title)
plt.subplot(1, 3, 2)
plt.hist(data_expon, bins=30, density=True, alpha=0.6, color='g')
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax*3, 100)
p = expon.pdf(x, *params_expon)
plt.plot(x, p, 'k', linewidth=2)
title = "Fit results: scale = {:.2f}".format(params_expon[1])
plt.title(title)
plt.legend()
plt.show()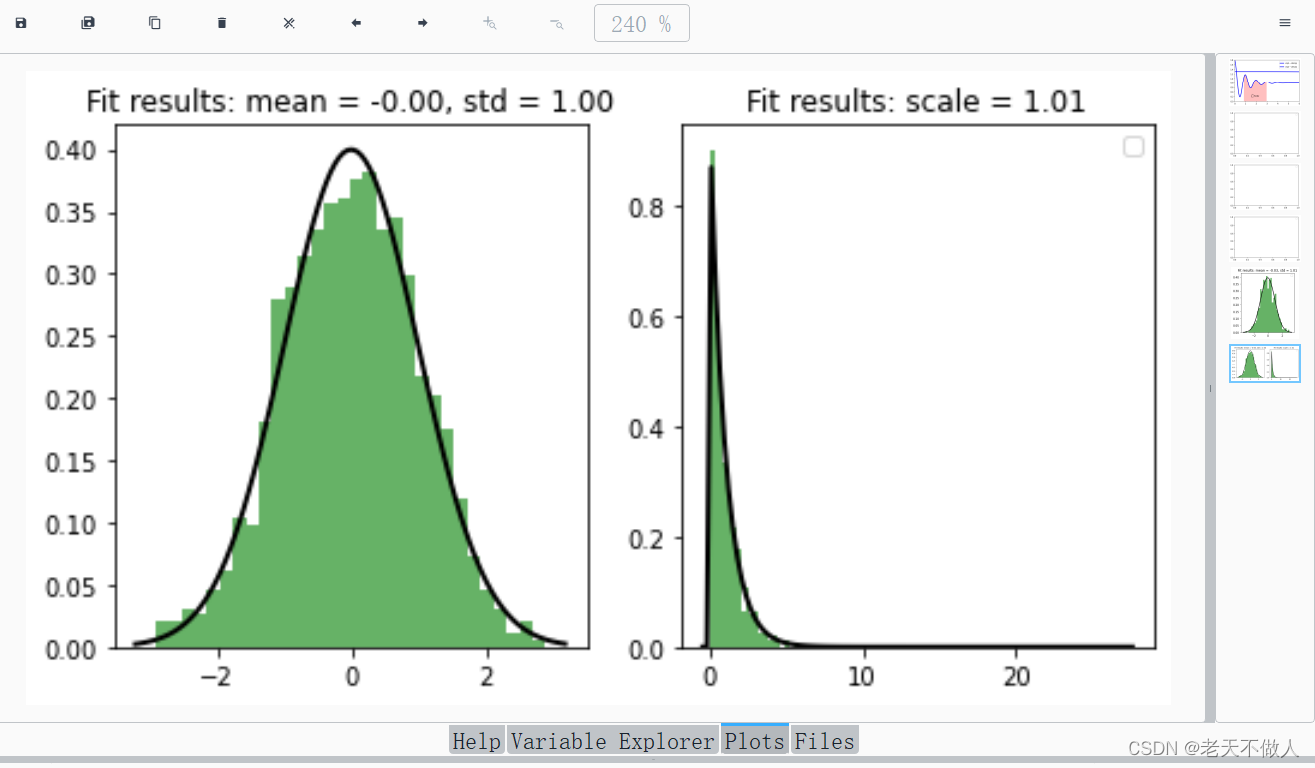
pandas数据处理
基本函数介绍:
DataFrame和Series的创建。
数据选择、排序和过滤。
数据清洗和转换。
数据聚合和分组操作。
具体问题解决:
示例:使用pandas处理CSV文件,并进行数据分析。
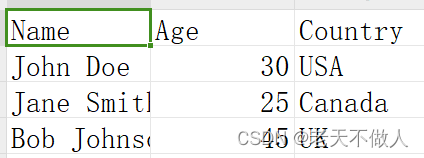
import pandas as pd
# 读取CSV文件
df = pd.read_csv('people.csv')
# 显示数据的前几行
print(df.head())
# 基本的描述性统计(虽然Age是数字列,但这里只会显示计数,因为Name和Country是非数值列)
print(df.describe()) # 注意:describe()通常只用于数值列
# 对Age列进行描述性统计
print(df['Age'].describe())
# 按照Country列进行分组,并计算每个国家的平均年龄
average_age_by_country = df.groupby('Country')['Age'].mean()
print(average_age_by_country)
# 如果你想看到每个国家的所有统计信息(例如,计数、平均值、标准差等)
country_stats = df.groupby('Country')['Age'].agg(['count', 'mean', 'std'])
print(country_stats)
# 绘制每个国家的平均年龄柱状图
average_age_by_country.plot(kind='bar')
plt.title('Average Age by Country')
plt.xlabel('Country')
plt.ylabel('Average Age')
plt.show()
# 注意:在上面的代码中,我们还没有导入matplotlib.pyplot,所以现在我们需要导入它
import matplotlib.pyplot as plt
# 如果你想看到数据的更多细节,比如数据透视表
pivot_table = df.pivot_table(values='Age', index=['Name'], columns=['Country'], aggfunc='mean')
print(pivot_table) # 注意:在这个例子中,每个人只有一个记录,所以透视表可能不是很有用
# 在实际情况下,您可能想根据多个列进行分组或透视
# ...
# 保存修改后的DataFrame到新的CSV文件(如果需要的话)
# df.to_csv('modified_people.csv', index=False) # index=False避免将索引保存到文件中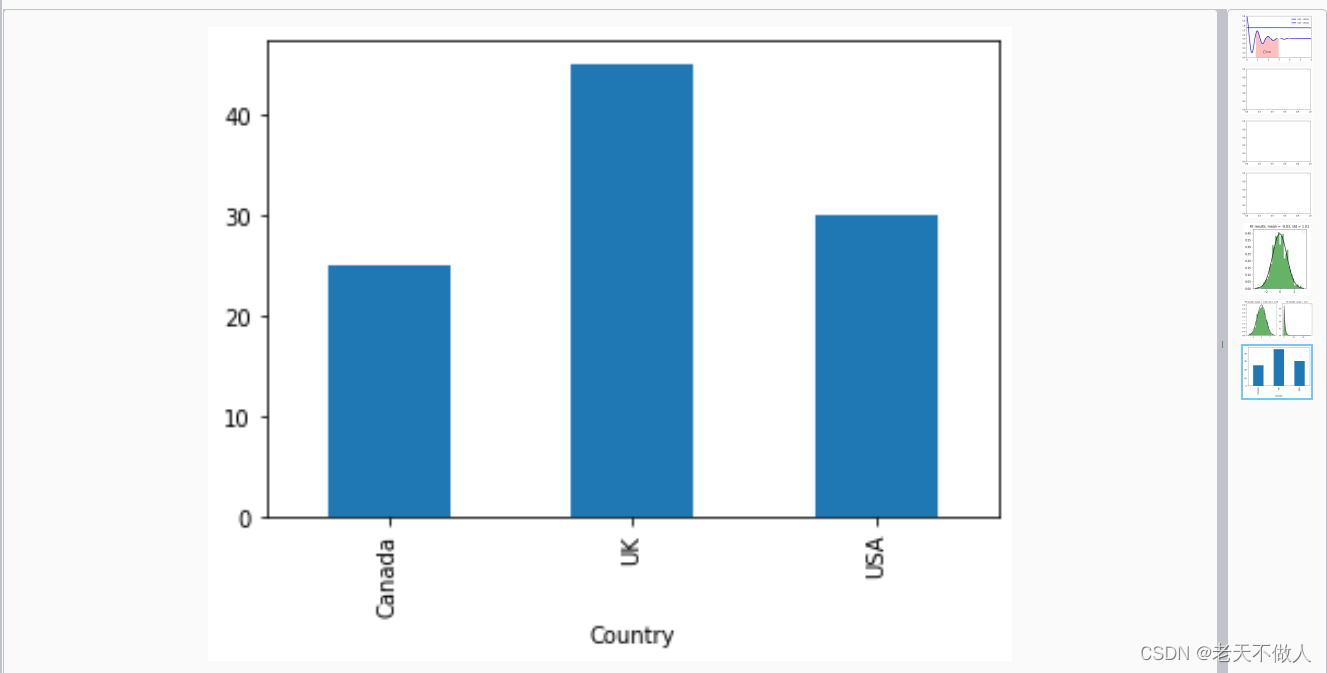
示例:使用pandas进行数据合并和连接。
import pandas as pd
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'ID': [1, 2, 3], 'A': ['A0', 'A1', 'A2']})
df2 = pd.DataFrame({'ID': [1, 2, 4], 'B': ['B0', 'B1', 'B2']})
# 使用 merge() 方法合并两个 DataFrame
# 默认是内连接(inner join),即只保留两个 DataFrame 中都有的 ID
merged_inner = pd.merge(df1, df2, on='ID')
print(merged_inner)
# 使用外连接(outer join),保留所有 ID,即使某个 DataFrame 中没有对应的记录
merged_outer = pd.merge(df1, df2, on='ID', how='outer')
print(merged_outer)
# 也可以使用左连接(left join)或右连接(right join)
merged_left = pd.merge(df1, df2, on='ID', how='left')
print(merged_left)
merged_right = pd.merge(df1, df2, on='ID', how='right')
print(merged_right)
matplotlib数据可视化
基本函数介绍:
绘制线图、散点图、柱状图等。
自定义图形属性(如颜色、标签、图例等)。
使用子图(subplots)进行多图展示。
图像处理:
示例:使用matplotlib绘制基本的三角函数。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 6, 100)
y = np.cos(2*np.pi*x)*np.exp(-x)+0.8
z = 0.5*np.cos(x**2)+0.8
plt.plot(x, y,'k',color='blue', linewidth=3, label="$exp-decay$")
plt.legend()
plt.show()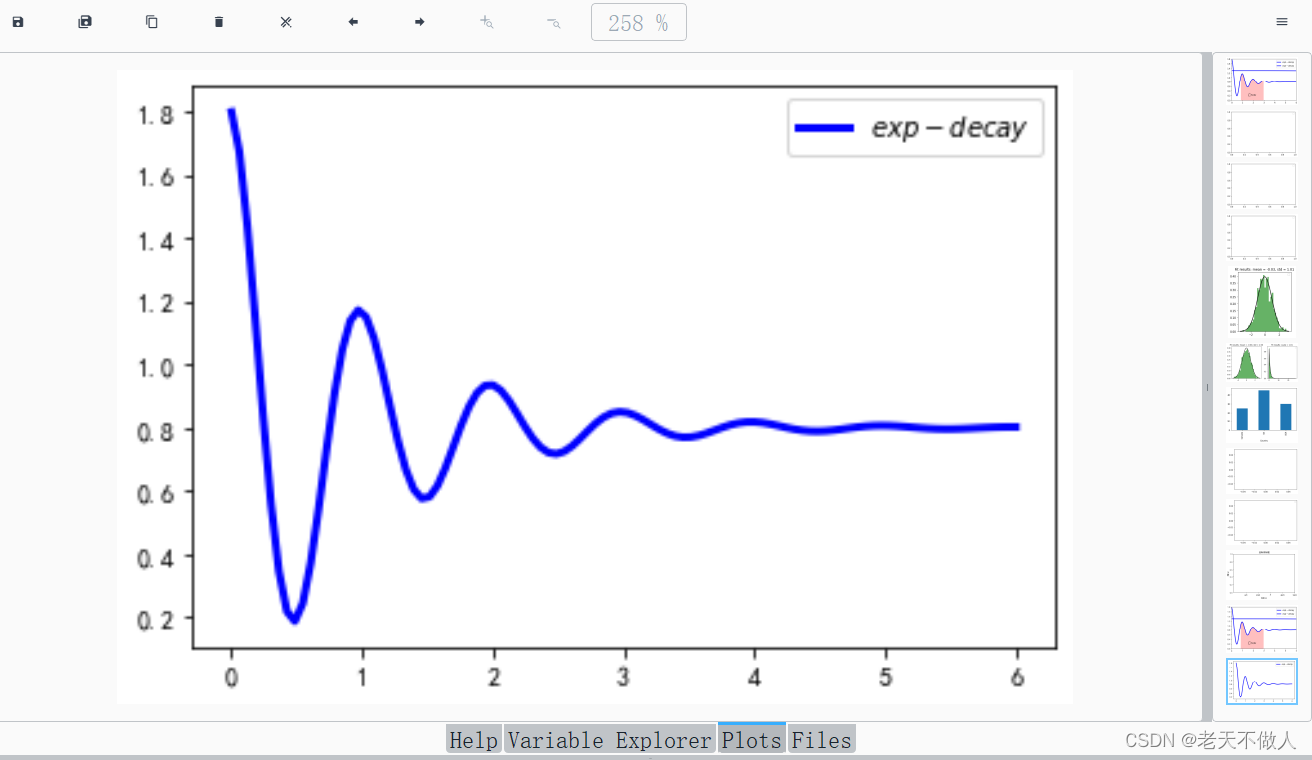
示例:使用matplotlib对图像进行简单的处理和变换(如灰度化、直方图均衡化等)。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0.0, 6.0, 100)
y = np.cos(2*np.pi*x)*np.exp(-x)+0.8
z = 0.5*np.cos(x**2)+0.8
plt.plot(x, y, z,'k',color='blue', linewidth=3, label="$exp-decay$")
plt.axis([0,6,0,1.8])
ix=(x>0.8)&(x<3)
plt.fill_between(x,y,0,where=ix,\
facecolor='r',alpha=0.25)
plt.text(0.5*(0.8+3), 0.2, r"$\int_a^b f(x)\mathrm{d}x$",\
horizontalalignment='center')
plt.legend()
plt.show()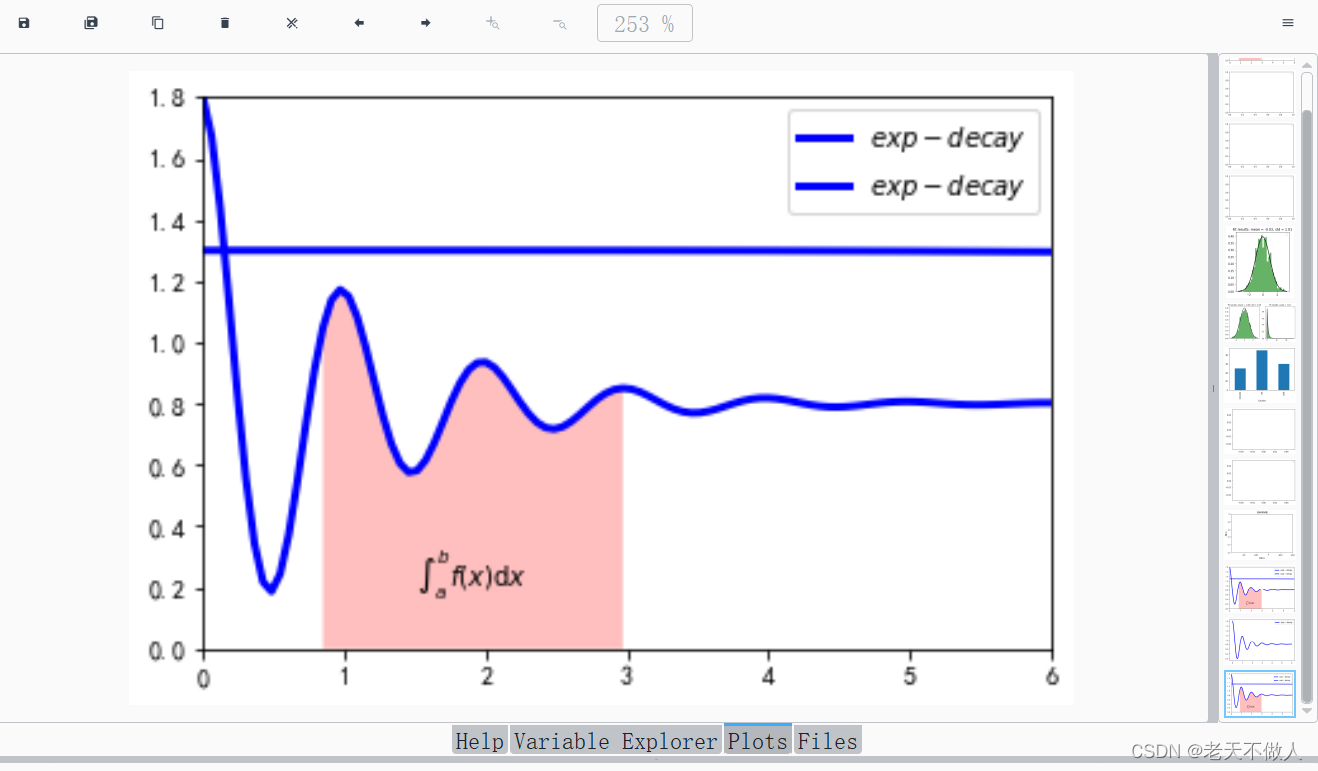
具体问题解决:
结论
总结numpy、scipy、pandas、matplotlib在学习和实践中的体会,强调这些库在数据处理和科学计算中的重要性,并展望未来的应用和发展方向。















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









