






点击左上方蓝字关注我们

课程简介
“手把手带你学NLP”是基于飞桨PaddleNLP的系列实战项目。本系列由百度多位资深工程师精心打造,提供了从词向量、预训练语言模型,到信息抽取、情感分析、文本问答、结构化数据问答、文本翻译、机器同传、对话系统等实践项目的全流程讲解,旨在帮助开发者更全面清晰地掌握百度飞桨框架在NLP领域的用法,并能够举一反三、灵活使用飞桨框架和PaddleNLP进行NLP深度学习实践。

从6月7日起,百度飞桨 & 自然语言处理部携手推出了12节NLP精品课,课程中会介绍到这里的实践项目。
课程报名请戳:
https://aistudio.baidu.com/aistudio/course/introduce/24177
欢迎来课程QQ群(群号:758287592)交流吧~~
词向量(Word embedding),即把词语表示成实数向量。“好”的词向量能体现词语直接的相近关系。词向量已经被证明可以提高NLP任务的性能,例如语法分析和情感分析。
PaddleNLP已预置多个公开的预训练Embedding,您可以通过使用paddlenlp.embeddings.TokenEmbedding接口加载预训练Embedding,从而提升训练效果。
接下来将依次介绍paddlenlp.embeddings.TokenEmbedding,展示词与词之间的语义距离,并结合词袋模型获取句子的语义表示。
本次课程项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/1535355
!pip install --upgrade paddlenlp -i https://pypi.org/simple
加载WordEmbedding
TokenEmbedding()参数
embedding_name 将模型名称以参数形式传入TokenEmbedding,加载对应的模型。默认为w2v.baidu_encyclopedia.target.word-word.dim300的词向量。
unknown_token 未知token的表示,默认为[UNK]。
unknown_token_vector 未知token的向量表示,默认生成和embedding维数一致,数值均值为0的正态分布向量。
extended_vocab_path 扩展词汇列表文件路径,词表格式为一行一个词。如引入扩展词汇列表,trainable=True。
trainable Embedding层是否可被训练。True表示Embedding可以更新参数,False为不可更新。默认为True。
from paddlenlp.embeddings import TokenEmbedding
# 初始化TokenEmbedding, 预训练embedding未下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 查看token_embedding详情
print(token_embedding)
Parameter containing:
Tensor(shape=[635965, 300], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[-0.24200200, 0.13931701, 0.07378800, ..., 0.14103900, 0.05592300, -0.08004800],
[-0.08671700, 0.07770800, 0.09515300, ..., 0.11196400, 0.03082200, -0.12893000],
[-0.11436500, 0.12201900, 0.02833000, ..., 0.11068700, 0.03607300, -0.13763499],
...,
[ 0.02628800, -0.00008300, -0.00393500, ..., 0.00654000, 0.00024600, -0.00662600],
[ 0.00274005, 0.02501113, 0.03349263, ..., 0.04212213, -0.00800593, -0.00184806],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ]])
1.1 认识一下Embedding
TokenEmbedding.search获得指定词汇的词向量。
test_token_embedding = token_embedding.search("中国")
print(test_token_embedding)
[[ 0.260801 0.1047 0.129453 -0.257317 -0.16152 0.19567 -0.074868
0.361168 0.245882 -0.219141 -0.388083 0.235189 0.029316 0.154215
……
0.289043 -0.284084 0.205076 0.059885 0.055871 0.159309 0.062181
0.123634 0.282932 0.140399 -0.076253 -0.087103 0.07262 ]]
TokenEmbedding.cosine_sim计算词向量间余弦相似度,语义相近的词语余弦相似度更高,说明预训练好的词向量空间有很好的语义表示能力。
score1 = token_embedding.cosine_sim("女孩", "女人")
score2 = token_embedding.cosine_sim("女孩", "书籍")
print('score1:', score1)
print('score2:', score2)
score1: 0.7017183
score2: 0.19189896
1.2 词向量映射到低维空间
使用深度学习可视化工具VisualDL的High Dimensional组件可以对embedding结果进行可视化展示,便于对其直观分析,步骤如下:
由于AI Studio当前支持的是VisualDL 2.1版本,因此需要升级到2.2版本体验最新的数据降维功能
创建LogWriter并将记录词向量
点击左侧面板中的可视化tab,选择‘hidi’作为文件并启动VisualDL可视化
!pip install --upgrade visualdl
# 获取词表中前1000个单词
labels = token_embedding.vocab.to_tokens(list(range(0, 1000)))
# 取出这1000个单词对应的Embedding
test_token_embedding = token_embedding.search(labels)
# 引入VisualDL的LogWriter记录日志
from visualdl import LogWriter
with LogWriter(logdir='./hidi') as writer:
#writer.add_embeddings(tag='test', mat=test_token_embedding, metadata=labels)
writer.add_embeddings(tag='test', mat=[i for i in test_token_embedding], metadata=labels)
启动VisualDL查看词向量降维效果
启动步骤:
切换到「可视化」指定可视化日志
日志文件选择 'hidi'
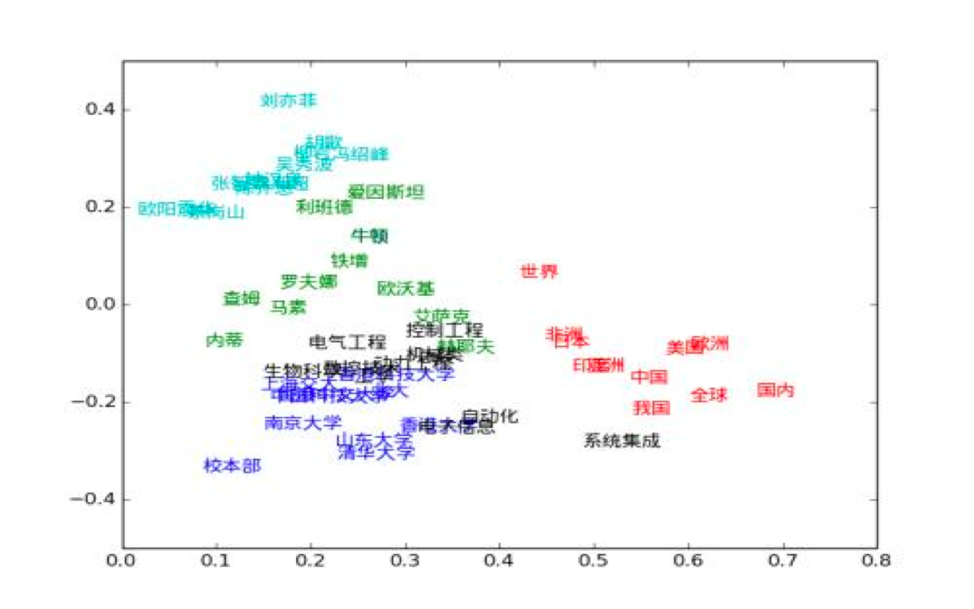
点击「启动VisualDL」后点击「打开VisualDL」,选择「高维数据映射」,即可查看词表中前1000词UMAP方法下映射到三维空间的可视化结果:
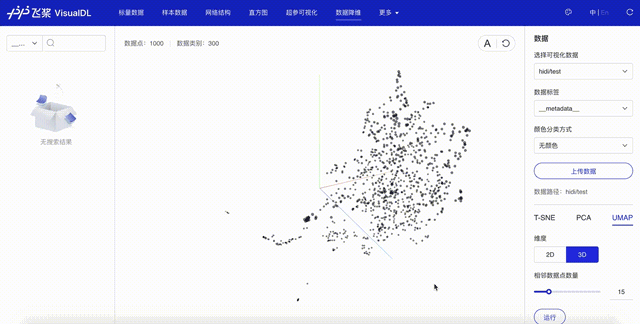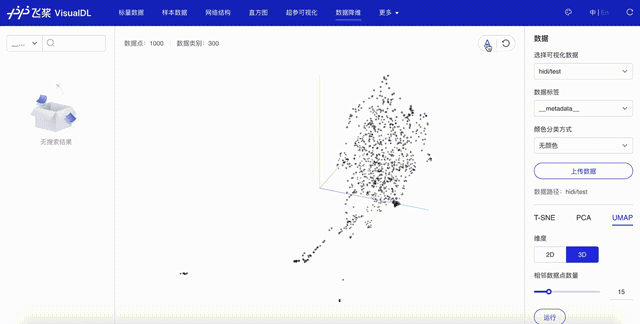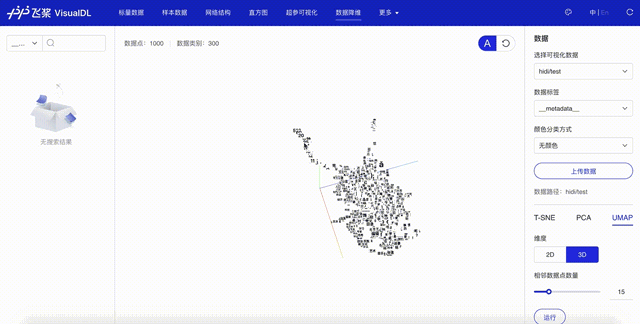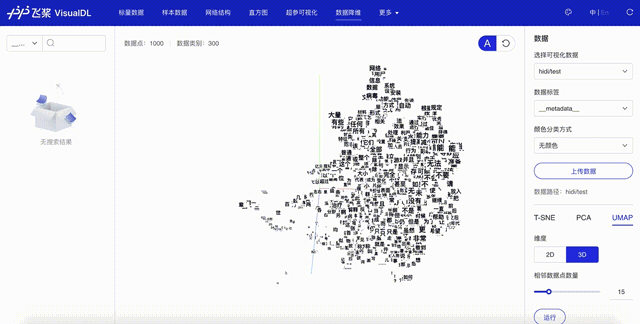
可以看出,语义相近的词在词向量空间中聚集(如数字、章节等),说明预训练好的词向量有很好的文本表示能力。
使用VisualDL除可视化embedding结果外,还可以对标量、图片、音频等进行可视化,有效提升训练调参效率。关于VisualDL更多功能和详细介绍,可参考VisualDL使用文档。
基于TokenEmbedding
衡量句子语义相似度
在许多实际应用场景(如文档检索系统)中, 需要衡量两个句子的语义相似程度。此时我们可以使用词袋模型(Bag of Words,简称BoW)计算句子的语义向量。
首先,将两个句子分别进行切词,并在TokenEmbedding中查找相应的单词词向量(word embdding)。
然后,根据词袋模型,将句子的word embedding叠加作为句子向量(sentence embedding)。
最后,计算两个句子向量的余弦相似度。
2.1 基于TokenEmbedding的词袋模型
使用BoWEncoder搭建一个BoW模型用于计算句子语义。
paddlenlp.TokenEmbedding组建word-embedding层
paddlenlp.seq2vec.BoWEncoder组建句子建模层
import paddleimport paddle.nn as nnimport paddlenlp
class BoWModel(nn.Layer):
def __init__(self, embedder):
super().__init__()
self.embedder = embedder
emb_dim = self.embedder.embedding_dim
self.encoder = paddlenlp.seq2vec.BoWEncoder(emb_dim)
self.cos_sim_func = nn.CosineSimilarity(axis=-1)
def get_cos_sim(self, text_a, text_b):
text_a_embedding = self.forward(text_a)
text_b_embedding = self.forward(text_b)
cos_sim = self.cos_sim_func(text_a_embedding, text_b_embedding)
return cos_sim
def forward(self, text):
# Shape: (batch_size, num_tokens, embedding_dim)
embedded_text = self.embedder(text)
# Shape: (batch_size, embedding_dim)
summed = self.encoder(embedded_text)
return summed
model = BoWModel(embedder=token_embedding)
2.2 构造Tokenizer
使用TokenEmbedding词表构造Tokenizer。
from data import Tokenizer
tokenizer = Tokenizer()
tokenizer.set_vocab(token_embedding.vocab)2.3 相似句对数据读取
以提供的样例数据text_pair.txt为例,该数据文件每行包含两个句子。
text_pairs = {}with open("text_pair.txt", "r", encoding="utf8") as f:
for line in f:
text_a, text_b = line.strip().split("\t")
if text_a not in text_pairs:
text_pairs[text_a] = []
text_pairs[text_a].append(text_b)
2.4 查看相似语句相关度
for text_a, text_b_list in text_pairs.items():
text_a_ids = paddle.to_tensor([tokenizer.text_to_ids(text_a)])
for text_b in text_b_list:
text_b_ids = paddle.to_tensor([tokenizer.text_to_ids(text_b)])
print("text_a: {}".format(text_a))
print("text_b: {}".format(text_b))
print("cosine_sim: {}".format(model.get_cos_sim(text_a_ids, text_b_ids).numpy()[0]))
print()
text_a: 多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解
text_b: 多项式矩阵的左共轭积及其应用
cosine_sim: 0.8861939311027527
text_a: 多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解
text_b: 退化阻尼对高维可压缩欧拉方程组经典解的影响
cosine_sim: 0.7975841760635376
2.5 使用VisualDL查看句子向量
# 引入VisualDL的LogWriter记录日志import numpy as npfrom visualdl import LogWriter # 获取句子以及其对应的向量
label_list = []
embedding_list = []
for text_a, text_b_list in text_pairs.items():
text_a_ids = paddle.to_tensor([tokenizer.text_to_ids(text_a)])
embedding_list.append(model(text_a_ids).numpy())
label_list.append(text_a)
for text_b in text_b_list:
text_b_ids = paddle.to_tensor([tokenizer.text_to_ids(text_b)])
embedding_list.append(model(text_b_ids).numpy())
label_list.append(text_b)
embedding_list = np.concatenate(embedding_list, axis=0)
with LogWriter(logdir='./hidi') as writer:
writer.add_embeddings(tag='test', mat=[i for i in embedding_list], metadata=label_list)
2.6 启动VisualDL观察句子向量降维效果
步骤如上述观察词向量降维效果一样。
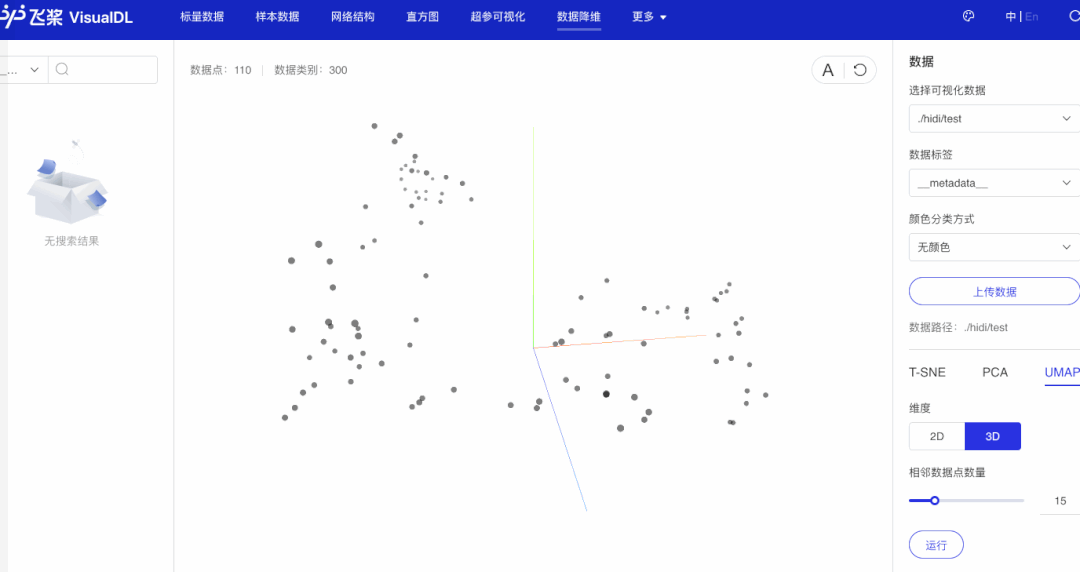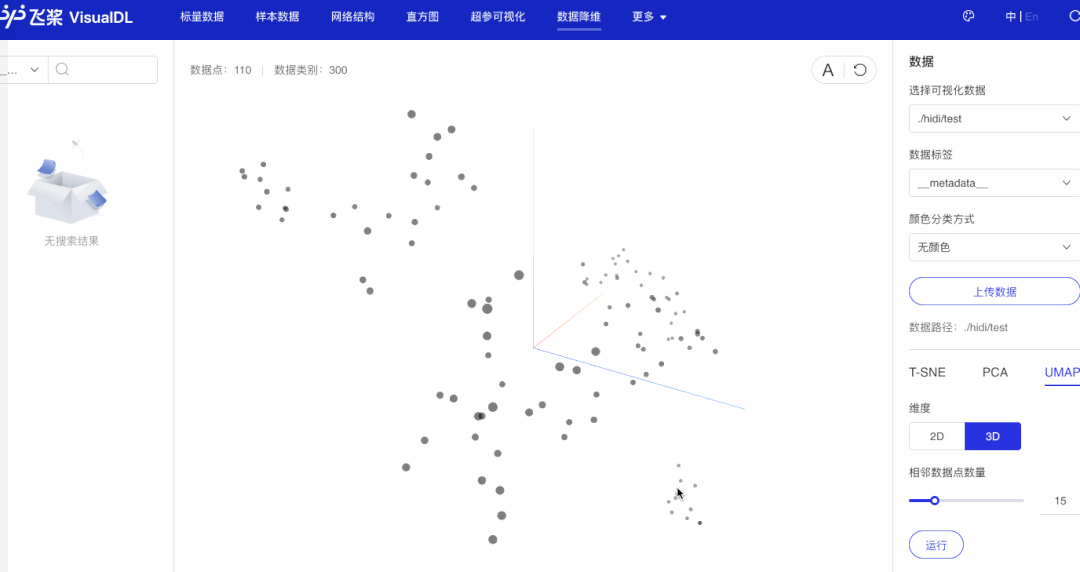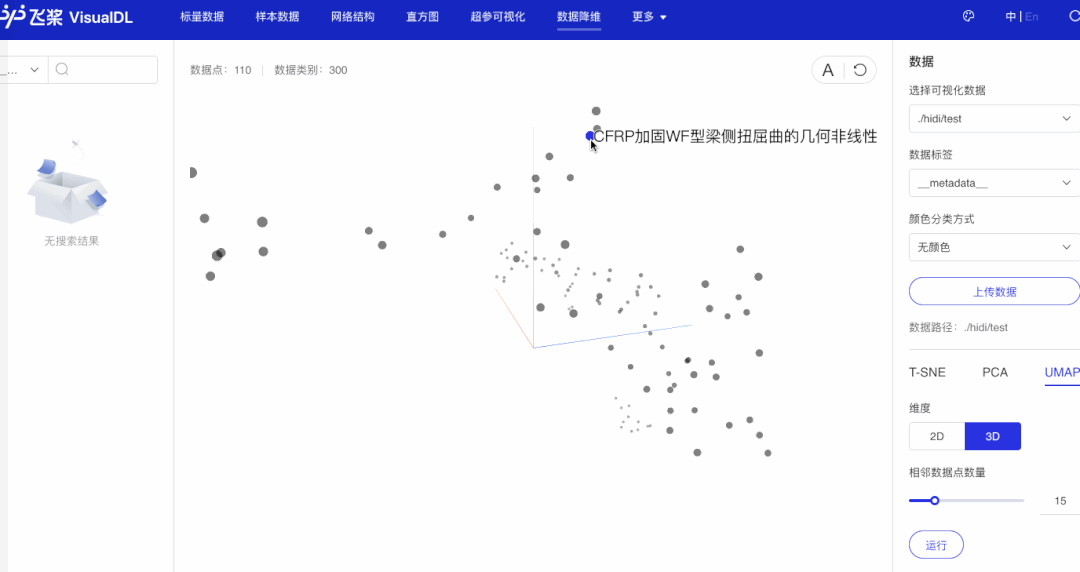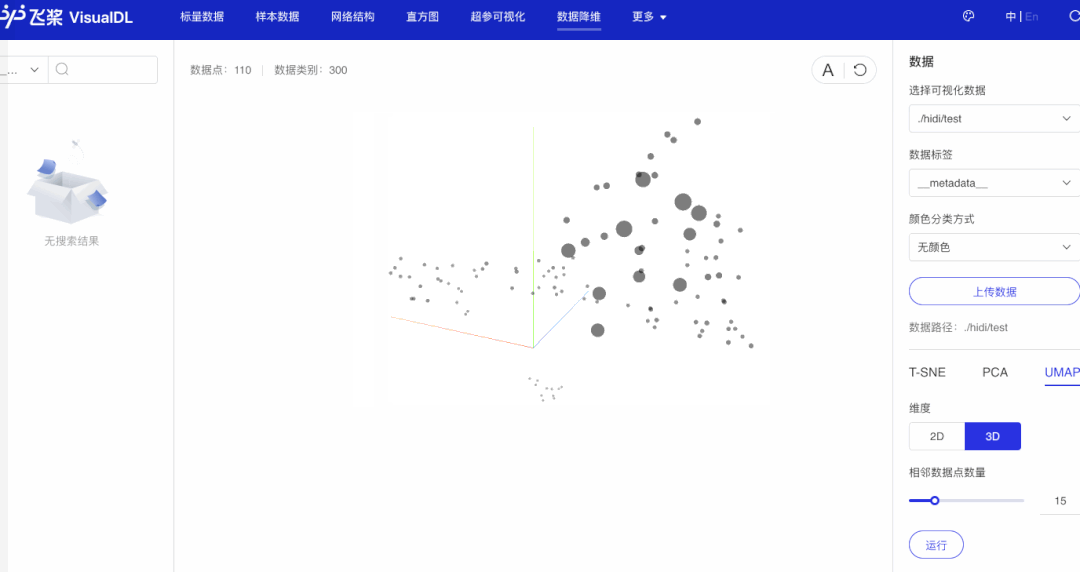
可以看出,语义相近的句子在句子向量空间中聚集(如有关课堂的句子、有关化学描述句子等)。
动手试一试
看完上面的详细教程,是不是也想动手体验一下呀。小编也强烈建议初学者参考上面的代码亲手敲一遍,因为只有这样才能加深你对代码的理解呦!
本次课程对应的代码:
https://aistudio.baidu.com/aistudio/projectdetail/1535355
除此之外,还可以更换一下TokenEmbedding预训练模型,使用VisualDL查看相应的TokenEmbedding可视化效果,并尝试使用更换后的TokenEmbedding计算句对语义相似度,进一步加深理解哈!
加入交流群,一起学习吧
如果你在学习过程中遇到任何问题或疑问,欢迎加入PaddleNLP的QQ技术交流群!

关于PaddleNLP更多预训练词向量
PaddleNLP提供61种可直接加载的预训练词向量,训练自多领域中英文语料、如百度百科、新闻语料、微博等,覆盖多种经典词向量模型(word2vec、glove、fastText)、涵盖不同维度、不同语料库大小,详情请参考:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/model_zoo/embeddings.md
更多PaddleNLP信息,欢迎访问GitHub点star后体验:
https://github.com/PaddlePaddle/PaddleNLP/
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









