






点击左上方蓝字关注我们

课程简介
“手把手带你学NLP”是基于飞桨PaddleNLP的系列实战项目。本系列由百度多位资深工程师精心打造,提供了从词向量、预训练语言模型,到信息抽取、情感分析、文本问答、结构化数据问答、文本翻译、机器同传、对话系统等实践项目的全流程讲解,旨在帮助开发者更全面清晰地掌握百度飞桨框架在NLP领域的用法,并能够举一反三、灵活使用飞桨框架和PaddleNLP进行NLP深度学习实践。

从6月7日起,百度飞桨 & 自然语言处理部携手推出了12节NLP精品课,课程中会介绍到这里的实践项目。
课程报名请戳:
https://aistudio.baidu.com/aistudio/course/introduce/24177
欢迎来课程QQ群(群号:758287592)交流吧~~
1. 背景介绍
信息抽取旨在从非结构化自然语言文本中提取结构化知识,如实体、关系、事件等。对于给定的自然语言句子,根据预先定义的schema集合,抽取出所有满足schema约束的SPO三元组。
例如,「妻子」关系的schema定义为:
{
S_TYPE: 人物,
P: 妻子,
O_TYPE: {
@value: 人物
}
}
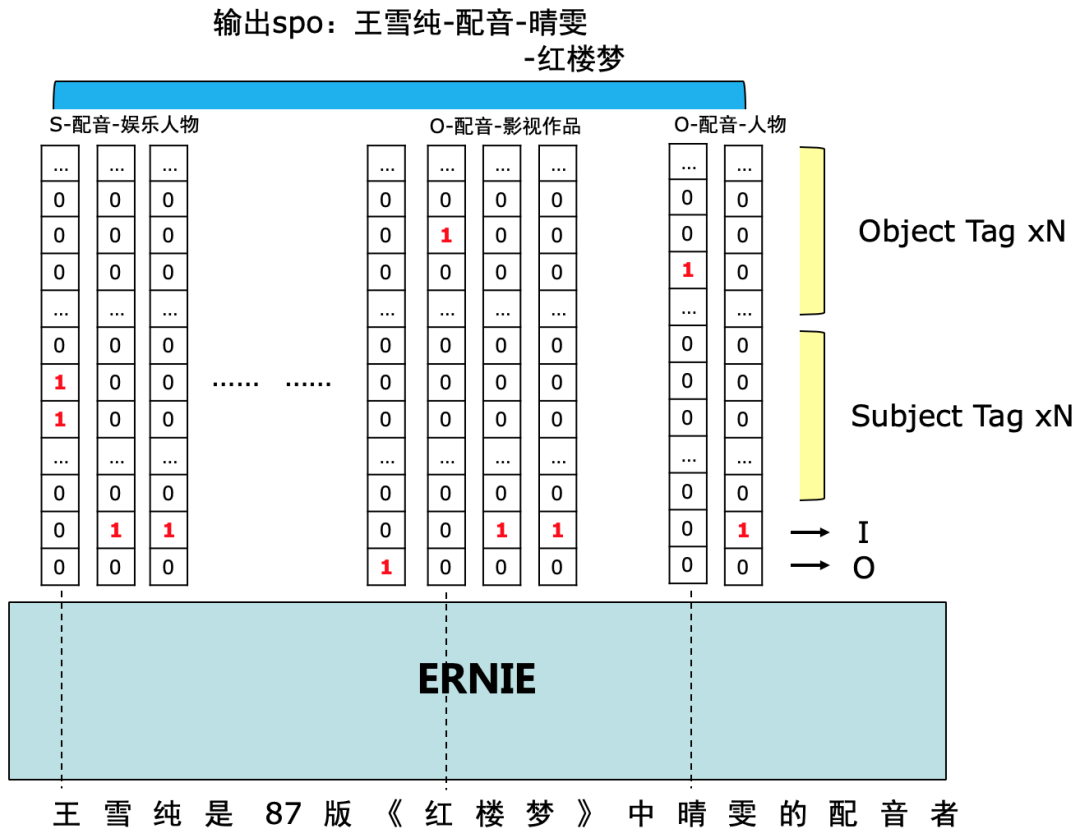
针对 DuIE2.0 任务中多条、交叠SPO这一抽取目标,比赛对标准的 'BIO' 标注进行了扩展。对于每个 token,根据其在实体span中的位置(包括B、I、O三种),我们为其打上三类标签,并且根据其所参与构建的predicate种类,将 B 标签进一步区分。给定 schema 集合,对于 N 种不同 predicate,以及头实体/尾实体两种情况,我们设计对应的共 2N 种 B 标签,再合并 I 和 O 标签,故每个 token 一共有 (2N+2) 个标签,如下图所示。
评价方法
对测试集上参评系统输出的SPO结果和人工标注的SPO结果进行精准匹配,采用F1值作为评价指标。注意,对于复杂O值类型的SPO,必须所有槽位都精确匹配才认为该SPO抽取正确。针对部分文本中存在实体别名的问题,使用百度知识图谱的别名词典来辅助评测。F1值的计算方式如下:
F1 = (2 * P * R) / (P + R),其中:
P = 测试集所有句子中预测正确的SPO个数 / 测试集所有句子中预测出的SPO个数
R = 测试集所有句子中预测正确的SPO个数 / 测试集所有句子中人工标注的SPO个数
本示例展示了以ERNIE(Enhanced Representation through Knowledge Integration)为代表的预训练模型如何Finetune完成关系抽取任务。
记得给PaddleNLP点个小小的Star⭐
开源不易,希望大家多多支持~
GitHub地址:
https://github.com/PaddlePaddle/PaddleNLP

AI Studio平台后续会默认安装PaddleNLP最新版,在此之前可使用如下命令更新安装。
!pip install --upgrade paddlenlp -i https://pypi.org/simple
2. 快速实践
2.1 构建模型
该任务可以看作一个序列标注任务,所以基线模型采用的是ERNIE序列标注模型。
PaddleNLP提供了ERNIE预训练模型常用序列标注模型,可以通过指定模型名字完成一键加载。PaddleNLP为了方便用户处理数据,内置了对于各个预训练模型对应的Tokenizer,可以完成文本token化,转token ID,文本长度截断等操作。
文本数据处理直接调用tokenizer即可得到模型所需输入数据。
import os
import json
from paddlenlp.transformers import ErnieForTokenClassification, ErnieTokenizer
label_map_path = os.path.join('data', "predicate2id.json")
if not (os.path.exists(label_map_path) and os.path.isfile(label_map_path)):
sys.exit("{} dose not exists or is not a file.".format(label_map_path))
with open(label_map_path, 'r', encoding='utf8') as fp:
label_map = json.load(fp)
num_classes = (len(label_map.keys()) - 2) * 2 + 2
model=ErnieForTokenClassification.from_pretrained("ernie-1.0",num_classes=(len(label_map) - 2) * 2 + 2)
tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
inputs = tokenizer(text="请输入测试样例", max_seq_len=20)
2.2加载并处理数据
从比赛官网下载数据集,解压存放于data/目录下并重命名为train_data.json, dev_data.json, test_data.json。
我们可以加载自定义数据集。通过继承paddle.io.Dataset,自定义实现__getitem__和__len__两个方法。
from typing import Optional, List, Union, Dict
import numpy as npimport paddlefrom tqdm import tqdmfrom paddlenlp.utils.log import logger
from data_loader import parse_label, DataCollator, convert_example_to_featurefrom extract_chinese_and_punct import ChineseAndPunctuationExtractor
class DuIEDataset(paddle.io.Dataset):
"""
Dataset of DuIE.
"""
def __init__(
self,
input_ids: List[Union[List[int], np.ndarray]],
seq_lens: List[Union[List[int], np.ndarray]],
tok_to_orig_start_index: List[Union[List[int], np.ndarray]],
tok_to_orig_end_index: List[Union[List[int], np.ndarray]],
labels: List[Union[List[int], np.ndarray, List[str], List[Dict]]]):
super(DuIEDataset, self).__init__()
self.input_ids = input_ids
self.seq_lens = seq_lens
self.tok_to_orig_start_index = tok_to_orig_start_index
self.tok_to_orig_end_index = tok_to_orig_end_index
self.labels = labels
def __len__(self):
if isinstance(self.input_ids, np.ndarray):
return self.input_ids.shape[0]
else:
return len(self.input_ids)
def __getitem__(self, item):
return {
"input_ids": np.array(self.input_ids[item]),
"seq_lens": np.array(self.seq_lens[item]),
"tok_to_orig_start_index":
np.array(self.tok_to_orig_start_index[item]),
"tok_to_orig_end_index": np.array(self.tok_to_orig_end_index[item]),
# If model inputs is generated in `collate_fn`, delete the data type casting.
"labels": np.array(
self.labels[item], dtype=np.float32),
}
@classmethod
def from_file(cls,
file_path: Union[str, os.PathLike],
tokenizer: ErnieTokenizer,
max_length: Optional[int]=512,
pad_to_max_length: Optional[bool]=None):
assert os.path.exists(file_path) and os.path.isfile(
file_path), f"{file_path} dose not exists or is not a file."
label_map_path = os.path.join(
os.path.dirname(file_path), "predicate2id.json")
assert os.path.exists(label_map_path) and os.path.isfile(
label_map_path
), f"{label_map_path} dose not exists or is not a file."
with open(label_map_path, 'r', encoding='utf8') as fp:
label_map = json.load(fp)
chineseandpunctuationextractor = ChineseAndPunctuationExtractor()
input_ids, seq_lens, tok_to_orig_start_index, tok_to_orig_end_index, labels = (
[] for _ in range(5))
dataset_scale = sum(1 for line in open(file_path, 'r'))
logger.info("Preprocessing data, loaded from %s" % file_path)
with open(file_path, "r", encoding="utf-8") as fp:
lines = fp.readlines()
for line in tqdm(lines):
example = json.loads(line)
input_feature = convert_example_to_feature(
example, tokenizer, chineseandpunctuationextractor,
label_map, max_length, pad_to_max_length)
input_ids.append(input_feature.input_ids)
seq_lens.append(input_feature.seq_len)
tok_to_orig_start_index.append(
input_feature.tok_to_orig_start_index)
tok_to_orig_end_index.append(
input_feature.tok_to_orig_end_index)
labels.append(input_feature.labels)
return cls(input_ids, seq_lens, tok_to_orig_start_index,
tok_to_orig_end_index, labels)
data_path = 'data'
batch_size = 32
max_seq_length = 128
train_file_path = os.path.join(data_path, 'train_data.json')
train_dataset = DuIEDataset.from_file(
train_file_path, tokenizer, max_seq_length, True)
train_batch_sampler = paddle.io.BatchSampler(
train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
collator = DataCollator()
train_data_loader = paddle.io.DataLoader(
dataset=train_dataset,
batch_sampler=train_batch_sampler,
collate_fn=collator)
eval_file_path = os.path.join(data_path, 'dev_data.json')
test_dataset = DuIEDataset.from_file(
eval_file_path, tokenizer, max_seq_length, True)
test_batch_sampler = paddle.io.BatchSampler(
test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
test_data_loader = paddle.io.DataLoader(
dataset=test_dataset,
batch_sampler=test_batch_sampler,
collate_fn=collator)
2.3定义损失函数和优化器
我们选择均方误差作为损失函数,使用paddle.optimizer.AdamW作为优化器。
在训练过程中,模型保存在当前目录checkpoints文件夹下。同时在训练的同时使用官方评测脚本进行评估,输出P/R/F1指标。在验证集上F1可以达到69.42。
import paddle.nn as nn
class BCELossForDuIE(nn.Layer):
def __init__(self, ):
super(BCELossForDuIE, self).__init__()
self.criterion = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, logits, labels, mask):
loss = self.criterion(logits, labels)
mask = paddle.cast(mask, 'float32')
loss = loss * mask.unsqueeze(-1)
loss = paddle.sum(loss.mean(axis=2), axis=1) / paddle.sum(mask, axis=1)
loss = loss.mean()
return lossfrom utils import write_prediction_results, get_precision_recall_f1, decoding
@paddle.no_grad()def evaluate(model, criterion, data_loader, file_path, mode):
"""
mode eval:
eval on development set and compute P/R/F1, called between training.
mode predict:
eval on development / test set, then write predictions to \
predict_test.json and predict_test.json.zip \
under /home/aistudio/relation_extraction/data dir for later submission or evaluation.
"""
example_all = []
with open(file_path, "r", encoding="utf-8") as fp:
for line in fp:
example_all.append(json.loads(line))
id2spo_path = os.path.join(os.path.dirname(file_path), "id2spo.json")
with open(id2spo_path, 'r', encoding='utf8') as fp:
id2spo = json.load(fp)
model.eval()
loss_all = 0
eval_steps = 0
formatted_outputs = []
current_idx = 0
for batch in tqdm(data_loader, total=len(data_loader)):
eval_steps += 1
input_ids, seq_len, tok_to_orig_start_index, tok_to_orig_end_index, labels = batch
logits = model(input_ids=input_ids)
mask = (input_ids != 0).logical_and((input_ids != 1)).logical_and((input_ids != 2))
loss = criterion(logits, labels, mask)
loss_all += loss.numpy().item()
probs = F.sigmoid(logits)
logits_batch = probs.numpy()
seq_len_batch = seq_len.numpy()
tok_to_orig_start_index_batch = tok_to_orig_start_index.numpy()
tok_to_orig_end_index_batch = tok_to_orig_end_index.numpy()
formatted_outputs.extend(decoding(example_all[current_idx: current_idx+len(logits)],
id2spo,
logits_batch,
seq_len_batch,
tok_to_orig_start_index_batch,
tok_to_orig_end_index_batch))
current_idx = current_idx+len(logits)
loss_avg = loss_all / eval_steps
print("eval loss: %f" % (loss_avg))
if mode == "predict":
predict_file_path = os.path.join("/home/aistudio/relation_extraction/data", 'predictions.json')
else:
predict_file_path = os.path.join("/home/aistudio/relation_extraction/data", 'predict_eval.json')
predict_zipfile_path = write_prediction_results(formatted_outputs,
predict_file_path)
if mode == "eval":
precision, recall, f1 = get_precision_recall_f1(file_path,
predict_zipfile_path)
os.system('rm {} {}'.format(predict_file_path, predict_zipfile_path))
return precision, recall, f1
elif mode != "predict":
raise Exception("wrong mode for eval func")
from paddlenlp.transformers import LinearDecayWithWarmup
learning_rate = 2e-5
num_train_epochs = 5
warmup_ratio = 0.06
criterion = BCELossForDuIE()# Defines learning rate strategy.
steps_by_epoch = len(train_data_loader)
num_training_steps = steps_by_epoch * num_train_epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_ratio)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])])2.4 模型训练与评估
模型训练的过程通常有以下步骤:
从dataloader中取出一个batch data。
将batch data喂给model,做前向计算。
将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。
loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
import time
import paddle.nn.functional as F
# Starts training.
global_step = 0
logging_steps = 50
save_steps = 10000
num_train_epochs = 2
output_dir = 'checkpoints'
tic_train = time.time()
model.train()
for epoch in range(num_train_epochs):
print("\n=====start training of %d epochs=====" % epoch)
tic_epoch = time.time()
for step, batch in enumerate(train_data_loader):
input_ids, seq_lens, tok_to_orig_start_index, tok_to_orig_end_index, labels = batch
logits = model(input_ids=input_ids)
mask = (input_ids != 0).logical_and((input_ids != 1)).logical_and(
(input_ids != 2))
loss = criterion(logits, labels, mask)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_gradients()
loss_item = loss.numpy().item()
if global_step % logging_steps == 0:
print(
"epoch: %d / %d, steps: %d / %d, loss: %f, speed: %.2f step/s"
% (epoch, num_train_epochs, step, steps_by_epoch,
loss_item, logging_steps / (time.time() - tic_train)))
tic_train = time.time()
if global_step % save_steps == 0 and global_step != 0:
print("\n=====start evaluating ckpt of %d steps=====" %
global_step)
precision, recall, f1 = evaluate(
model, criterion, test_data_loader, eval_file_path, "eval")
print("precision: %.2f\t recall: %.2f\t f1: %.2f\t" %
(100 * precision, 100 * recall, 100 * f1))
print("saving checkpoing model_%d.pdparams to %s " %
(global_step, output_dir))
paddle.save(model.state_dict(),
os.path.join(output_dir,
"model_%d.pdparams" % global_step))
model.train()
global_step += 1
tic_epoch = time.time() - tic_epoch
print("epoch time footprint: %d hour %d min %d sec" %
(tic_epoch // 3600, (tic_epoch % 3600) // 60, tic_epoch % 60))
# Does final evaluation.
print("\n=====start evaluating last ckpt of %d steps=====" %
global_step)
precision, recall, f1 = evaluate(model, criterion, test_data_loader,
eval_file_path, "eval")
print("precision: %.2f\t recall: %.2f\t f1: %.2f\t" %
(100 * precision, 100 * recall, 100 * f1))
paddle.save(model.state_dict(),
os.path.join(output_dir,
"model_%d.pdparams" % global_step))
print("\n=====training complete=====")
=====start training of 0 epochs=====
epoch: 0 / 2, steps: 0 / 312, loss: 0.724156, speed: 110.16 step/s
epoch: 0 / 2, steps: 50 / 312, loss: 0.487328, speed: 4.28 step/s
·········
eval loss: 0.027972
precision: 0.00 recall: 0.00 f1: 0.00
=====training complete=====2.5 模型预测
训练保存好的模型,即可用于预测。
!bash predict.sh
模型预测详情请参见项目『基于预训练模型完成实体关系抽取』:
https://aistudio.baidu.com/aistudio/projectdetail/1639963
2.6 尝试更多的预训练模型
基线采用的预训练模型为ERNIE,PaddleNLP提供了丰富的预训练模型,如BERT,RoBERTa,Electra,XLNet等,请参考预训练模型文档。 如可以选择RoBERTa large中文预训练模型优化模型效果,只需更换模型和tokenizer即可无缝衔接。
from paddlenlp.transformers import RobertaForTokenClassification, RobertaTokenizer
model = RobertaForTokenClassification.from_pretrained(
"roberta-wwm-ext-large",
num_classes=(len(label_map) - 2) * 2 + 2)
tokenizer = RobertaTokenizer.from_pretrained("roberta-wwm-ext-large")
加入交流群,一起学习吧
如果你在学习过程中遇到任何问题或疑问,欢迎加入PaddleNLP的QQ技术交流群!

动手试一试
是不是觉得很有趣呀。小编强烈建议初学者参考上面的代码亲手敲一遍,因为只有这样,才能加深你对代码的理解呦。
本次项目对应的代码:
https://aistudio.baidu.com/aistudio/projectdetail/1639963
除此之外, PaddleNLP提供了多种预训练模型,可一键调用,来更换一下预训练模型试试吧:
https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers.html
更多PaddleNLP信息,欢迎访问GitHub点star收藏后体验:
https://github.com/PaddlePaddle/PaddleNLP
回顾往期
越学越有趣:『手把手带你学NLP』系列项目01 ——词向量应用的那些事儿
越学越有趣:『手把手带你学NLP』系列项目02 ——语义相似度计算的那些事儿
越学越有趣:『手把手带你学NLP』系列项目03 ——快递单信息抽取的那些事儿

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









