






导读:12月12日,在上海举行的WAVE SUMMIT 2021深度学习开发者峰会上,飞桨深度学习开源框架2.2版本正式发布。飞桨是中国首个开源的深度学习框架,一直致力于让深度学习技术的创新与应用更简单。
最新的v2.2版本飞桨框架在编程接口方面,新增了傅里叶变换、线性代数计算、AI科学计算等相关的100多个API,可以支持更广泛任务类型的模型开发;分布式训练方面,在优化了4D混合并行等分布式技术的同时,新增了端到端自适应大规模分布式训练能力,支撑了全球首个知识增强千亿大模型——“鹏城-百度·文心”的发布;在硬件适配方面,提供了包括Kernel Primitive API和NNAdapter在内的的低成本硬件接入技术方案。
此外,飞桨框架v2.2还优化了文本任务开发全流程,给NLP开发者带来更快更易用开发体验。
飞桨框架 v2.2 共包含 1800+ commits,共有 190+ 贡献者参与,下面让我们看看该版本的重点更新:
API 体系支持更广泛的模型开发。
端到端自适应大规模分布式训练架构。
多层次、低成本的硬件适配统一方案。
加速文本任务全流程。
API 体系支持
更广泛的模型开发
飞桨框架v2.2新增100+ API,主要包括:
24个傅里叶变换API paddle.fft.* :支持可微分的 N 维实数与复数、复数与复数间的傅里叶变换和逆变换,及以此为基础的短时傅里叶变换和逆变换。
17个线性代数API paddle.linalg.* :全面覆盖了矩阵计算、矩阵分解、矩阵属性计算、线性方程组求解等4大场景。
新增 paddle.einsum,支持以更加简洁的方式来表达多维张量(Tensor)的计算。
增加更多的张量(Tensor)高级索引操作,即可用省略号、布尔值、Python List、Paddle Tensor等作为索引去操作张量(Tensor),能够更加方便和灵活地去读写张量(Tensor)中的某些元素。
加强对AI科学计算功能的支持,包括支持高阶微分的 elementwise_add、elementwise_mul、matmul、sigmoid 和 tanh 等算子,支持函数式自动微分接口的Jacobian、Hessian、jvp、vjp、vhp 等函数式自动微分 API,从而可以便捷实现基于深度学习的微分方程的求解,解决例如计算流体力学中的 LDC(Lid Driven Cavity Flow)等问题。
此外,还新增了很多 Tensor 操作类API、组网类API、硬件支持类API以及高层API。
v2.2 的 FFT API
在语音合成声码器上的应用
在最新的 PaddleSpeech 的语音合成声码器模型中,使用飞桨框架v2.2中的fft系列算子 paddle.signal.stft 实现了Parallel WaveGAN、Multi Band MelGAN、HiFiGAN和Style MelGAN等语音合成中的声码器模型。在Parallel WaveGAN模型的效果对比中,可以看到其收敛速度和收敛效果均略优于基于Pytorch v1.9实现的模型。
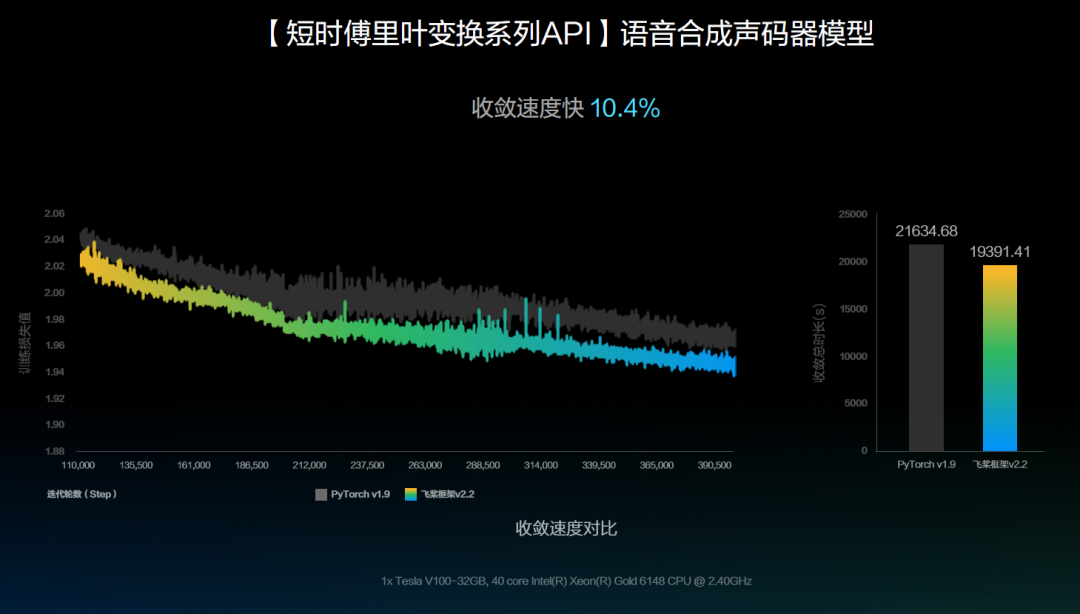
* PaddleSpeech :
https://github.com/PaddlePaddle/PaddleSpeech
v2.2 的函数式自动微分API和高阶微分
在计算流体力学场景上的探索
在科学计算领域,往往需要针对气候气象、能源材料、航空航天、生物医药等具体场景中的物理问题进行模拟。由于大多数物理规律可以表达为偏微分方程的形式,所以偏微分方程组的求解成为了解决科学计算领域问题的关键。传统方法一般是基于有限差分、有限元、有限体积等方法,求得偏微分方程组的近似解。这些方法面临着“维度灾难”,即计算量随着维度增加快速增长;
另一方面由于存在串行运算,这些方法难以使用GPU硬件进行加速。而深度学习的神经网络具备“万能逼近”能力,即只要网络有足够的神经元,就可以充分地逼近任意一个连续函数,基于神经网络去求解偏微分方程组为解决科学计算领域问题提供了新范式。
飞桨一方面通过改进框架自动微分机制和底层算子实现,支持了典型运算的高阶自动微分;另一方面,通过新增Jacobian、Hessian、jvp、vjp等API接口,增强了对偏微分方程组的表达能力。在以上两部分工作的基础上,飞桨实现了基于神经网络的偏微分方程组的求解,并在计算流体力学场景做了探索性的工作。
LDC是计算流体力学的一个经典问题,我们使用隐藏层节点数为50的10层全连接网络作为神经网络模型,在[-0.05, -0.05] 到[0.05, 0.05]的矩形区域上以100 * 100的为粒度划分网格,根据偏微分方程组和边界条件设计Loss,进行训练以实现对偏微分方程组的求解,从而正确模拟出了腔体内水平方向和垂直方向上的液体流速分布,与基于OpenFOAM软件实现的传统方法结果均方误差在1e-4数量级。

更进一步,基于100 * 100网格粒度下训练出的神经网络模型,我们在100 * 100,200 * 200, 400 * 400, 600 * 600 网格粒度下进行推理,并和对应网格粒度下的传统方法结果进行比较,实验结果表明使用AI方法解决该类问题具有更大的潜力:
各网格粒度下推理结果与传统方法的均方误差均在1e-4数量级,这说明了AI方法拥有在粗网格上训练,在更细网格上推理的泛化能力。
使用AI方法推理,计算量和网格点数成线性关系,复杂度优于传统算法,并且得益于算法容易并行的特性和GPU硬件算力,推理性能比传统方法可以提升12到626倍。

除了计算流体力学场景,我们还在多孔介质流体力学场景中的Darcy问题上进行了探索,正确拟合出了土壤中的压强分布。科学计算领域的相关工作将在发布的科学计算套件PaddleSciencev0.1上集成,我们正在积极丰富PaddleScience套件的功能,未来可以在更多场景上发挥作用,欢迎各个领域的伙伴一起贡献。
*PaddleScience:
https://github.com/PaddlePaddle/PaddleScience
分布式训练能力的
最新升级
飞桨围绕统一的分布式计算图表示和集群资源表示,针对不同应用模型与硬件平台,打造全流程通用异构自适应分布式软件栈,实现不同应用场景和硬件架构高效协同训练,支持超大规模分布式训练。
端到端自适应大规模分布式训练架构
针对当前传统的分布式训练技术在易用性、鲁棒性、资源利用率几个维度上面临的问题,飞桨重新思考并设计了端到端自适应的分布式训练架构。
首先将用户的组网转化成统一的分布式计算视图,同时将硬件侧的异构资源信息转化成统一的集群资源视图,并通过端到端代价模型建模选择最优放置策略,然后使用异步流水运行的机制开始训练。当集群环境发生变化时,例如训练设备故障或动态新增/删减时,弹性资源管理机制可以触发训练架构各个模块自适应做出反应。
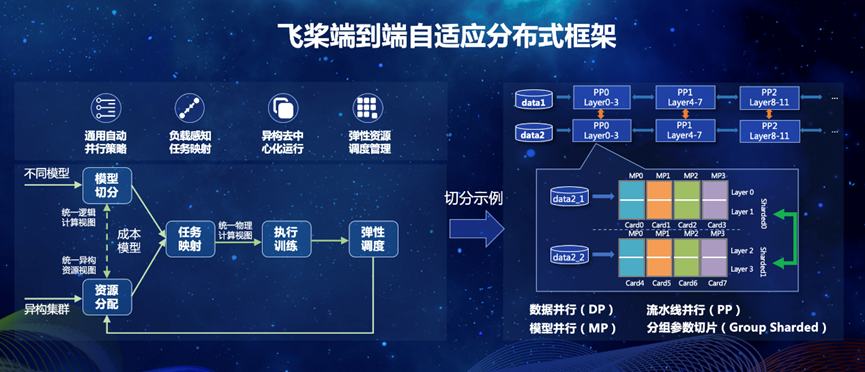
飞桨的自适应分布式训练架构在多个场景下得到了很好的验证。其中GPT-3 1460亿参数的模型、512张V100 GPU卡下,训练功耗达到理论峰值的48.6%;图像分类的ResNet50模型,采用数据并行和模型并行策略,单机8卡V100 GPU能支持6700万类别的模型训练;“鹏城-百度·文心”千亿大模型的训练性能达到同规模、非自适应架构下的性能的2.1倍。
https://mp.weixin.qq.com/s/sr-Du3t8tyyqvfviNqq8nA
混合并行能力升级
飞桨框架v2.2的动态图完善支持4D 混合并行能力。完善动态图混合并行功能,支持数据并行、张量模型并行和流水线并行以及多个策略任意组合,支持GPT-3 千亿参数模型的训练,并且在多种策略上性能持平静态图。
异构(Heter-PS)
参数服务器能力升级
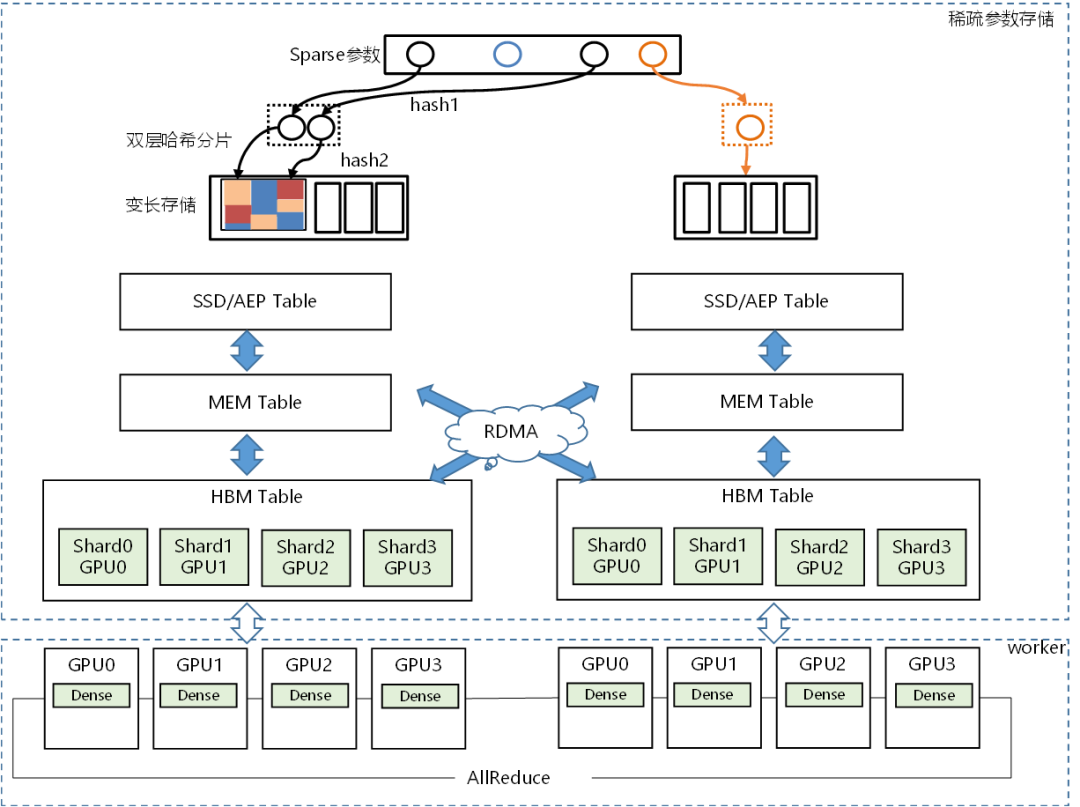
优化数据读取性能,优化基于GPU显存/AEP/SSD等存储介质的稀疏参数表构建及读写性能,完善流水线等功能,使得整体性能提升一倍,内存占用减少一半,一台 GPU 机器可替代百台 CPU 机器训练千亿稀疏模型。
多层次、低成本的
硬件适配统一方案
随着智能芯片种类越来越复杂,深度学习框架的硬件接入成本已经成为一个显著问题,也会进而影响到新硬件的应用推广。
为此,飞桨框架v2.2推出了硬件适配的统一方案,来降低适配成本。如下图所示,该方案不仅包括基于算子Kernel接入的 Kernel Primitive API方案,还有基于子图/整图接入的 NNAdapter 方案,硬件厂商可以根据硬件特性灵活选择。
此外,飞桨还在探索和研发神经网络编译器CINN,它可以利用基础算子自动融合优化来实现复杂算子功能,降低适配成本的同时,优化性能。

Kernel Primitive API
实现算子计算与硬件解耦
深度学习框架包含大量算子,不同硬件上算子Kernel实现不同,硬件移植成本高。Kernel Primitive API 通过对算子 Kernel 实现中的底层代码进行抽象与封装,提供高性能的 Block 级 IO 和 Compute 运算,实现了算子计算与硬件解耦。使Kernel开发可以更加专注计算逻辑的实现,在保证性能的同时大幅减少代码量,如softmax算子实现由155行减少为30行,大幅减少了硬件适配时的算子开发成本。
以昆仑芯第2代芯片(XPU-2)接入为例,实践证明Reduce、Elementwise、Activation这三类算子,适配代码量可减少93.4%。另外,使用 Kernel Primitive API 还实现了一处优化,多处收益的效果,仅对IO运算进行向量化访存优化,飞桨的70个算子性能就可以平均提升12.8%。您可以在这里了解关于 Kernel Primitive API 的详情。
*Kernel Primitive API 的详情:https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/07_new_op/kernel_primitive_api/index_cn.html
NNAdapter 飞桨推理
AI 硬件统一适配框架
为了进一步降低硬件厂商适配门槛、缩短适配周期、减少开发、沟通和维护成本。飞桨针对子图/整图接入方式提出了一种新的硬件适配方案———飞桨推理 AI 硬件统一适配框架NNAdapter。它作为推理框架与硬件的桥梁,向上通过NNAdapter API完成框架适配层接口的标准化,向下通过 NNAdapter HAL完成硬件抽象层接口的标准化,实现对硬件设备功能的抽象和封装,为NNAdapter 在不同设备提供统一的访问接口。以适配寒武纪MLU为例,NNAdapter方案较原方案代码行数减少69.4%,修改代码文件数减少62.3%。您可以在这里了解关于 NNAdapter 的详情。
* NNAdapter 的详情:
https://paddle-lite.readthedocs.io/zh/develop/develop_guides/nnadapter.html
加速文本任务全流程
飞桨框架 v2.2 通过四大特性加速了文本任务开发全流程,给开发者提供了更快更易用的开发体验。
文本预处理加速
本次升级框架增加了字符串张量的支持,使模型的训练和推理可以直接接受文本字符串的输入,提供更加端到端的开发体验。有了字符串张量的支持则可将常用的文本处理通过算子化来提升计算效率。相比在Python上实现文本处理操作,算子化的实现可以规避 Python 语言中的全局解释器锁(GIL)的问题,借助框架能力,充分发挥多核CPU并发执行能力,提升大Batch Size文本的吞吐量。
*Python 语言中的全局解释器锁(GIL):
https://wiki.python.org/moin/GlobalInterpreterLock
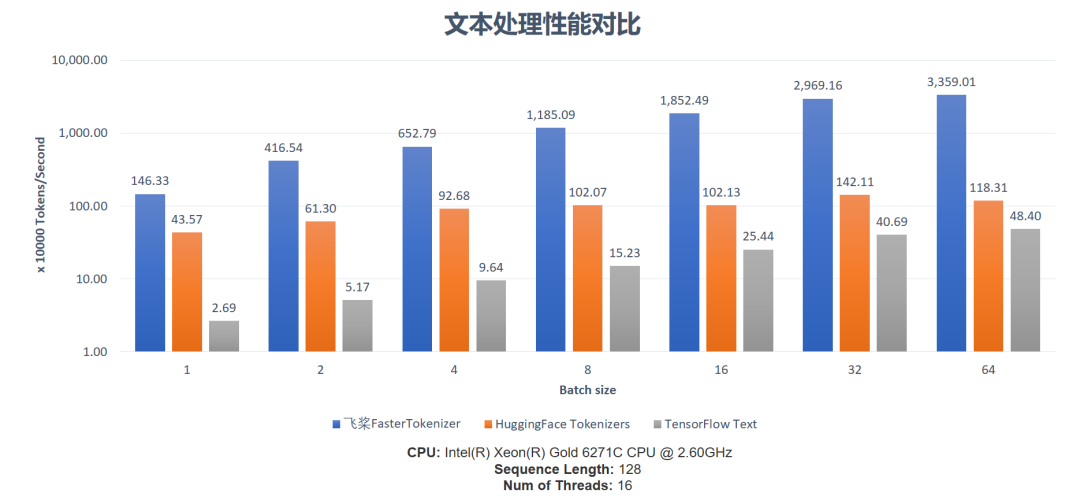
以 BERT 模型的中文 Tokenization 环节为例,飞桨FasterTokenizer采用纯 C++ 实现,相比 HuggingFace Tokenizers,性能达到其3.3到28.4倍;由于 FasterTokenizer 算子实现融合度更高,显著减少框架调度开销对效率的影响,性能达到 TensorFlow Text 实现的54.4到69.4倍。整体上看飞桨FasterTokenizer借助框架更充分地利用了CPU多核的能力,在大 Batch Size 文本中更具性能优势。完整的性能对比数据如下图所示:
*Tokenizers:
https://github.com/huggingface/tokenizers
预训练任务加速
在预训练模型中常用的Transformer结构的 Encoder 部分,飞桨框架v2.2提供了paddle.incubate.nn.FusedTransformerEncoderLayerAPI,对注意力机制与Feedforward模块进行了融合加速,有效降低了访存开销并提升数据重用率,可大幅度提升该结构在NVIDIA GPU上的计算速度,在NVIDIA Tesla A100的GPU上,以ERNIE微调任务为例,速度最高可达优化前的3.3倍。
生成解码加速
预训练生成模型在通用对话、机器翻译、文本摘要等场景中具有广泛的应用,而此类模型Decoder部分的计算占比远远高于Encoder部分。基于框架自定义算子能力,飞桨拓展了NVIDIA FasterTransformer v4.0的GPU高性能加速实现,并拓展了飞桨自研的模型结构支持与产业实践中有效的解码策略。以机器翻译场景为例,解码速度是最高可达优化前的24倍,可大幅降低预训练生成模型的产业落地成本。
训推一体部署体验
综合上述提及的优化,通过端到端的文本处理与预训练任务加速两大特性,我们提供了针对文本任务增强的训推一体开发模式,导出的静态图包含了FasterTokenizer算子,因此在C++ 的工业级部署应用中,开发者可以省去复杂的文本处理代码开发,通过端到端的方式让模型以原始字符串输入,得到预测结果。同时得益于FasterTokenizer与Transformer Encoder融合加速的联合优化,推理速度是框架上一版本的2.6倍。而在部署成本方面,以ERNIE 的 C++部署为例,代码量相比飞桨框架v2.1可以节省94%,大幅提升工业部署的易用性。
上述提到的文本加速全流程完整使用示例,均可在 PaddleNLP的 faster examples中获得,欢迎开发者前往体验。
* PaddleNLP:
https://github.com/PaddlePaddle/PaddleNLP
*faster examples:
https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.2/examples/faster
结语
关于本版本的更详细的信息,请参看v2.2.0 Release Note。飞桨提供了多种安装方式,欢迎大家登录飞桨官网(https://www.paddlepaddle.org.cn/)下载体验飞桨框架v2.2 。您也可以关注飞桨的官方网站来跟进最新进展。
*v2.2.0 Release Note:
https://github.com/PaddlePaddle/Paddle/releases/tag/v2.2.0
关注公众号,获取更多技术内容~
















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









