







项目背景
据有关数据显示,截止2021年,中国机动车保有量超过3.6亿,机动车驾驶人达到4.5亿,成为名副其实的汽车大国。但与此同时,全国每年有数万人丧生于交通事故,几乎平均每8分钟就有1人因车祸死亡。其中,驾驶员“三超一疲劳”也是造成事故的重要原因之一。
本项目主要为了解决驾驶人由于疲劳或产生幻觉或忽视交通路标的问题,通过对交通路标的检测,从而对驾驶员进行提醒。本文将从数据准备、数据加载、模型训练、模型预测的完整流程来讲解如何完成交通路标的检测。
数据集来源:
https://aistudio.baidu.com/aistudio/datasetdetail/103743
完整项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2280990?contributionType=1&shared=1
数据集说明
本项目使用的数据集是:目标检测数据集合集,包含口罩识别数据 、交通标志识别数据、火焰检测数据、锥桶识别数据以及中秋元素识别数据等。其中,本项目用到的交通标志识别图片共887张,一共包含四类,分别是crosswalk、speedlimit、stop、trafficlight,并已做好标注。
解压数据集:
!unzip -oq /home/aistudio/data/data103743/objDataset.zip解压后查看数据路径:
!tree objDataset -L 2我们可以看到这样的效果:

数据准备
本项目使用的数据格式是PascalVOC格式,开发者基于PaddleX开发目标检测模型时,无需对数据格式进行转换,开箱即用。
但为了进行训练,还需要将数据划分为训练集、验证集和测试集。数据划分之前需要安装PaddleX。
!pip install paddlex -i https://mirror.baidu.com/pypi/simple然后进行数据集的划分:
使用如下命令即可将数据划分为70%训练集,20%验证集和10%的测试集。
!paddlex --split_dataset --format VOC --dataset_dir objDataset/roadsign_voc --val_value 0.2 --test_value 0.1划分完成后,该数据集下会生成labels.txt, train_list.txt, val_list.txt和test_list.txt,分别存储类别信息,训练样本列表,验证样本列表,测试样本列表。
数据预处理
在训练模型之前,对目标检测任务的数据进行预处理,从而提升模型效果。可用于数据处理的API有:
Normalize:对图像进行归一化
ResizeByShort:根据图像的短边调整图像大小
RandomHorizontalFlip:以一定的概率对图像进行随机水平翻转
RandomDistort:以一定的概率对图像进行随机像素内容变换
更多关于数据处理的API及使用说明可查看文档:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
下面我们随机打开一条数据查看:
from paddlex import transforms
import matplotlib.pyplot as plt
import cv2
infer_img = cv2.imread("objDataset/roadsign_voc/JPEGImages/road0.png")
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(infer_img, cv2.COLOR_BGR2RGB))
plt.show()
定义训练和验证时的数据处理方式。
定义训练和验证时的数据处理方式。
# 定义训练和验证时的transforms
# API说明 https://github.com/PaddlePaddle/PaddleX#paddlex-使用文档train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.ResizeByShort(short_size=256),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.CenterCrop(crop_size=224),
transforms.ResizeByShort(short_size=256),
transforms.Normalize()
])
test_transforms = transforms.Compose([
transforms.CenterCrop(crop_size=224),
transforms.ResizeByShort(short_size=256),
transforms.Normalize()
])
infer_img = cv2.imread("objDataset/roadsign_voc/JPEGImages/road0.png")
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(infer_img, cv2.COLOR_BGR2RGB))
plt.show()读取PascalVOC格式的检测数据集,并对样本进行相应的处理。
import paddlex as pdx
# 定义训练和验证所用的数据集
# API说明:https://github.com/PaddlePaddle/PaddleX#paddlex-使用文档
train_dataset = pdx.datasets.VOCDetection(
data_dir='objDataset/roadsign_voc',
file_list='objDataset/roadsign_voc/train_list.txt',
label_list='objDataset/roadsign_voc/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='objDataset/roadsign_voc',
file_list='objDataset/roadsign_voc/val_list.txt',
label_list='objDataset/roadsign_voc/labels.txt',
transforms=eval_transforms)需要注意的是:
data_dir (str): 数据集所在的目录路径。
file_list (str): 描述数据集图片文件和对应标注文件的文件路径(文本内每行路径为相对data_dir的相对路径)。
label_list (str): 描述数据集包含的类别信息文件路径。
模型训练
PaddleX目前提供了FasterRCNN、YOLOv3和PP-YOLO等目标检测模型,多种Backbone模型。本案例以骨干网络为ResNet50_vd_ssld的PP-YOLO算法为例。
PP-YOLO是飞桨开源的基于YOLOv3进行优化的模型,通过几乎不增加预测计算量的优化方法尽可能地提高YOLOv3模型的精度,最终在COCO test-dev2017数据集上精度达到45.9%,单卡V100预测速度为72.9FPS。下表为PP-YOLO和YOLOv4模型在不同输入尺寸下精度和速度的对比。

注: 上表中数据均为在单卡Tesla V100上batch size=1测试结果,TRT-FP16为使用TensorRT且在FP16上的测试结果,TensorRT版本为5.1.2.2。
下面介绍一下PP-YOLO的网络结构:
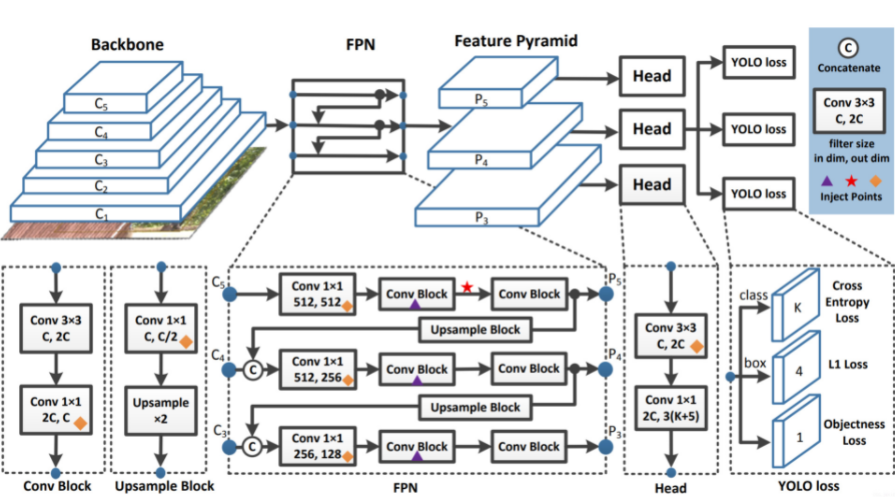
PP-YOLO基于ResNet系列骨干网络ResNet50-vd-dcn,使用mixup数据增广方式,通过合理的tricks组合,从而提升模型的性能。
模型结构
1. Backbone模型
直接用ResNet50-vd替换掉Darknet53会导致一部分的性能损失。因此,PP-YOLO将ResNet中的卷积替换为可变形卷积(Deformable Convolution Network)。可变形卷积的效果已经被很多论文证明了其有效性,但是过多的添加DCN层会导致增加预测时间,因此PP-YOLO替换了最后一个stage的3x3卷积为DCNs。
2. Detection Neck
使用FPN结构,将Backbone的第3,4,5个stage的输出作为FPN的输入(图中的 ,其中 =3,4,5),输出(图中的 ,其中 =3,4,5)的大小变为输入大小的一半。
3. Detection Head
常规来说Head的组成都是很简单的,包含两个卷积层,一个3x3卷积和一个1x1卷积。当输出类别是 的时候,输出的维度就是 ,每一个预测的特征图上的每一个预测位置都与三个不同的anchors相关。针对每一个anchor,前 个维度确定了类别,后4个确定了bounding box的定位,最后一个确定了目标置信度。CE和L1用于计算这些预测值的损失。
想要了解PP-YOLO Tricks实现详情,可以关注:
https://github.com/PaddlePaddle/PaddleDetection
图片来源:https://blog.csdn.net/weixin_44106928/article/details/107589319
查看网络结构
下面给大家介绍一种查看网络结构的办法,在组建好网络结构后,一般会想去对网络结构进行一下可视化,逐层的去对齐一下网络结构参数,看看是否符合预期。这里以LeNet()为例通过Model.summary接口进行可视化展示。用法点击链接查看:
https://www.paddlepaddle.org.cn/modelbase
import paddle
from paddle.static import InputSpec
input = InputSpec([None, 1, 28, 28], 'float32', 'image')
label = InputSpec([None, 1], 'int64', 'label')
model = paddle.Model(paddle.vision.models.LeNet(),
input, label)
params_info = model.summary()
print(params_info)下面我们开始模型加载:
# 初始化模型
# API说明: https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/detection.md
model = pdx.det.PPYOLO(num_classes=len(train_dataset.labels), backbone='ResNet50_vd_dcn')加载完模型之后,我们开始模型训练,参数保存在output/PPYOLO_resnet_50_vd_dcn目录下。
# 模型训练
# 各参数介绍与调整说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/detection.md
model.train(
num_epochs=300,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
train_batch_size=16,
pretrain_weights = 'COCO',
learning_rate=0.000125,
lr_decay_epochs=[210, 240],
save_dir='output/PPYOLO_resnet_50_vd_dcn')参数说明:
num_epochs (int): 训练迭代轮数。
train_batch_size (int): 训练数据batch大小。目前检测仅支持单卡评估,训练数据batch大小与显卡数量之商为验证数据batch大小。默认值为8。
save_interval_epochs (int): 模型保存间隔(单位:迭代轮数)。默认为20。
log_interval_steps (int): 训练日志输出间隔(单位:迭代次数)。默认为2。
save_dir (str): 模型保存路径。默认值为’output’。
pretrain_weights (str): 若指定为路径时,则加载路径下预训练模型;若为字符串’IMAGENET’,则自动下载在ImageNet图片数据上预训练的模型权重;若为字符串’COCO’,则自动下载在COCO数据集上预训练的模型权重;若为None,则不使用预训练模型。默认为’IMAGENET’。
模型预测
训练好模型之后,加载output目录下的模型文件进行预测。
import paddlex as pdx
model = pdx.load_model('output/PPYOLO_resnet_50_vd_dcn/best_model)
image_name = 'objDataset/roadsign_voc/JPEGImages/road358.png'
result = model.predict("objDataset/roadsign_voc/JPEGImages/road358.png",transforms=test_transforms)
pdx.det.visualize(image_name, result, threshold=0.5, save_dir='./output/ResNet50_vd_ssld')参数说明:
img_file (str|np.ndarray): 预测图像路径或numpy数组(HWC排列,BGR格式)。
transforms (paddlex.det.transforms): 数据预处理操作。
查看效果
imshow查看预测前和预测之后的效果。
infer_img = cv2.imread("objDataset/roadsign_voc/JPEGImages/road358.png")
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(infer_img, cv2.COLOR_BGR2RGB))
plt.show()
infer_img = cv2.imread("output/ResNet50_vd_ssld/visualize_road358.png")
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(infer_img, cv2.COLOR_BGR2RGB))
plt.show()
总结与升华
本项目在AI Studio上基于PaddleX完成了数据处理、模型训练、模型评估推理等工作。PaddleX作为飞桨全流程开发工具,集飞桨框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通深度学习开发全流程。同时,PaddleX提供简明易懂的Python API及一键下载安装的图形化开发客户端。用户可根据实际生产需求选择相应的开发方式,获得飞桨全流程开发的最佳体验。本项目已经实现了较高的预测效果,大家可以进行批量预测的尝试。
飞桨官网地址:
https://www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle

关注公众号,获取更多技术内容~















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









