






随着以语音为交互渠道的产业不断升级,企业对语音合成有着越来越多的需求,比如智能语音助手、手机地图导航、有声书播报等场景都需要用到语音合成技术。通过语音合成技术想要得到一个新的音色,需要定制音库,但是定制音库所耗费的人力成本和时间成本巨大,成为产业升级的屏障。
面对音库成本难题,PaddleSpeech语音合成技术再升级,开源多种降低定制音库成本方案。
-
多种小样本合成方案:支持一句话合成和小数据集微调。一句话合成方案即通过用户输入的一句话即可模仿用户的音色进行语音合成任务;小数据集微调方案针对少量数据学习用户音色,训练所需数据量降低98%以上。
-
跨语言学习方案:支持多发音人多语种训练,让发音人实现同音色跨语言语音合成任务,可有效降低音库对发音人多语种发音能力要求。
-
语音-语言跨模态大模型文心ERNIE-SAT:采用语音-文本联合训练的方式在多语言的数据集上训练,合成声音更加自然,可以承接多种下游任务,支持个性化合成、跨语言合成、语音编辑,可有效降低定制化音库所需数据量。
-
项目传送门:
https://github.com/PaddlePaddle/PaddleSpeech
- AIStudio 在线体验:
【PaddleSpeech进阶】PaddleSpeech小样本合成方案体验
https://aistudio.baidu.com/aistudio/projectdetail/4573549?sUid=2470186&shared=1&ts=1663753541400
方案技术解读
小样本合成方案
在语音合成任务中,想要学习一个发音人的音色需要大量的专业录音数据。以中文标准女声音库(Chinese Standard Mandarin Speech Copus)为例,其包含10000句,共计约12小时的干音数据。想要录制一个这样的标准音库,从音库设计,录制干音,到标注完成,涉及录音员、监听师、数据标注员等多种工作人员的参与,全套的工期至少需要两到三个月,消耗的人力成本和时间成本高。
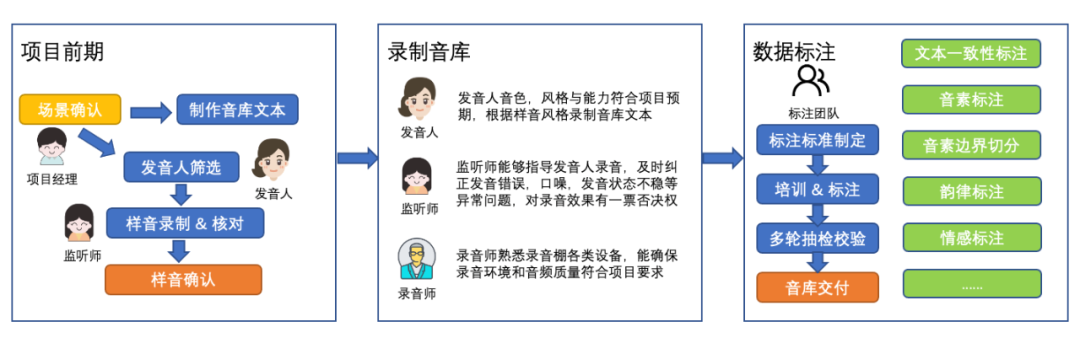
标准音库录制流程
定制音色需求在业务中也较为常见,例如,在智能客服行业中,服务提供商在提供语音合成服务时,用户想要使用自己话务员的声音,采用录制标准音库方案耗时长,成本高,此时可以考虑使用小样本合成方案,通过录制少量发音人的音色,快速使用发音人的音色进行发音。
对于小样本合成问题,业界有两种主流方案:一句话合成方案和小数据集微调方案。
一句话合成方案
在一句话合成方案中,将发音人的音色信息进行编码后,输入到多说话人语音合成模型中,使用发音人的音色进行合成任务。如SV2TTS模型结构所示,通过Speaker Encoder模块将说话人的音频转换成speaker embedding输入到Synthesizer中,得到具有说话人音色的梅尔频谱,再通过Vocoder将其转换成音频。
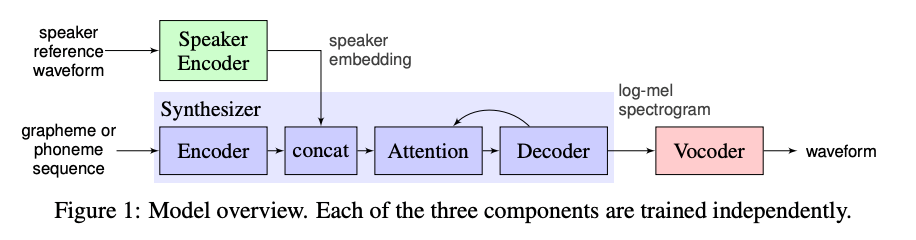
SV2TTS模型结构
非常热门的一句话合成项目Real-Time Voice Cloning Toolbox和Mocking Bird,也是采用类似的方案。在Speaker Encoder、Synthesizer和Vocoder阶段,都可以尝试不同的说话人编码器、合成器以及声码器组合。
针对一句话合成场景,PaddleSpeech提供了多种模型的组合方案。

一句话合成的效果受多说话人数据集和Speaker Encoder模型的影响较大,新发音人的声音会跟提取的speaker embedding在整个发音人向量空间中的最接近的那几个人的音色会比较像,因此一句话合成整体音色的效果因人而异,音色学习效果并不稳定。在能获取一定量的数据情况下,可以考虑小数据集微调方案。
小数据集微调方案
近年来,手机助手、地图导航、有声阅读等产品陆续开始支持用户自定义音色播报,常见流程是用户先阅读指定文本,在等待一段时间后(需要等待十几分钟到数个小时不等),APP可以使用用户的音色完成播报任务。这类应用多使用微调方案,在预训练模型的基础上进行微调,得到用户专属音色的相关模型。相比于一句话合成方案,该方案耗时更长,但具有更高的音色相似度和更好的音频质量。
PaddleSpeech开源小样本微调方案,基于aishell3开源多说话人数据集得到预训练模型,通过少量音频数据,同样可以学习新发音人的音色。

基于FastSpeech2的小样本微调方案
以FastSpeech2模型为例,数据量特别小的情况下,我们可以选择固定模型结构中一些层,如Encoder和Duration Predictor等,让其不参与训练过程,以此来提高微调效果的稳定性。当数据的量级逐步增加,可以逐渐放开一部分网络层参与到训练的过程中来。不同的声学模型结构,有着不同微调方案。以FastSpeech2模型为例,从中文标准女声音库(Chinese Standard Mandarin Speech Copus)选择200句就可以很好的学习到原发音人的音色了,相较于原版10000句的量级,训练所需的数据量降低了98%以上。
以只冻结Encoder网络为例,大家可以体验一下不同量级微调的合成效果。
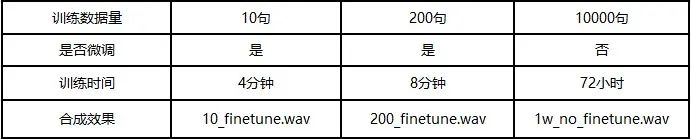
10_finetune 音频: 进度条 00:00 00:03 后退15秒 倍速 快进15秒
200_finetune 音频: 进度条 00:00 00:03 后退15秒 倍速 快进15秒
1w_no_finetune 音频: 进度条 00:00 00:03 后退15秒 倍速 快进15秒
根据自己场景和业务的需要,也可以加大参与微调部分的数据量,进一步提高音色的稳定性和发音效果。相较于从零开始构建音库,通过微调方案制作定制化发音人音色所需的人力成本、时间成本以及模型的训练成本都显著降低。
跨语言学习方案
多语言发音一直是语音合成场景中的强需求,在日常沟通过程中,很多句子会包含中英混合的词汇,比如GPS导航和JAVA工程师等等。针对中英双语场景,在制作音库时,通常会寻找能够进行中英双语播报的发音人录制音库,但是跟业务需求匹配同时能够双语播音的发音人筛选难度大,在录制过程中有时也会出现发音人英文口语表述不佳以及录音状态难以稳定等情况,导致最终合成的效果不佳。
PaddleSpeech这次发布的跨语言学习方案可以让0英文样本的中文发音人(Chinese Standard Mandarin Speech Copus)实现同音色双语播报。
跨语言学习方案
在音素集层面上使用多语言音素集,模型结构中增加多说话人Speaker Embedding,在数据集构造方面,预训练中英混合模型使用标准女声数据集(CSMSC)、开源英文女声数据集(LJ Speech)以及开源多说话人数据集aishell3和vctk共同训练,可以实现CSMSC音色和LJ Speech音色同时支持中英双语播报,实现跨语言学习。
这套方案同样可以用于其它语言,比如在训练的音库中加入普通话、粤语、英文、日语等其它语种,可实现多发音人、多语言播报。在制作音库过程中,可以降低对发音人的语种能力条件要求,提高音库制作的稳定性,降低成本。
语音-语言跨模态大模型
文心ERNIE-SAT
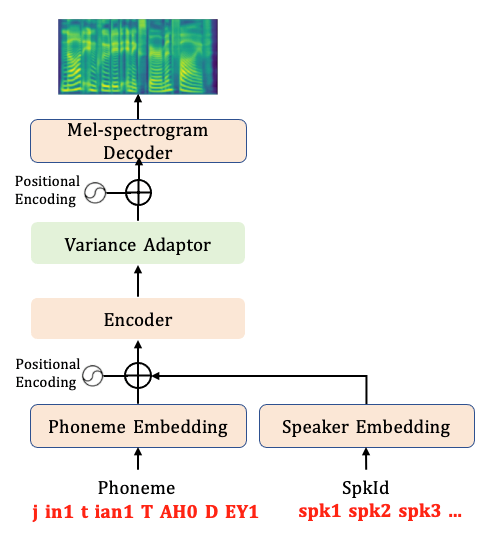
在这次的更新中,由文心大模型团队推出的语言-语音跨模态大模型文心ERNIE-SAT在飞桨语音套件PaddleSpeech中成功上线。文心ERNIE-SAT采用语音-语言联合训练的方式在中文和英文的数据集上进行预训练,可以使模型学到语音和文本之间的对齐关系,生成频谱的精度更高,生成声音更加自然。
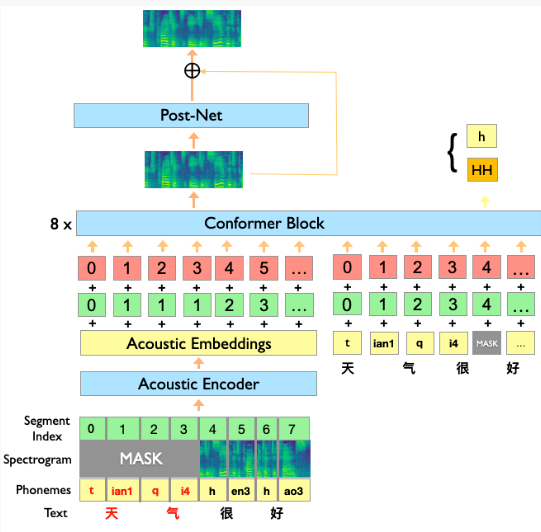
文心ERNIE-SAT模型结构图
文心ERNIE-SAT将语音和语言同时作为输入,通过MASK的方式对合成任务中部分区域掩盖,让模型自主学习前后的信息,并推断被Mask的部分的内容。相对于单模态的输入任务而言,文心ERNIE-SAT可以更好的学习上下文关键信息,能够支持语音编辑、个性化语音合成与跨语言语音合成等多种语音下游任务。
例如在智能语音客服场景中,与用户交互通常有TTS合成音频和以人工提前录音两种方式。早期TTS合成的音频辨识度高,自然度不足,用户难以与机器人进行多轮对话。客服机器人会采用人工录音的方式进行补充,以提高对话流畅度。但是人工录音需要提前准备大量话术,且难以应用于具有变量插槽的话术,如催收场景中播报用户姓名,欠款,预期信息等。此时,会采用人工录音+TTS合成变量拼接的方式,但是存在人工录音音色与TTS合成变量音色不一致,拼接不自然的问题,使用文心ERNIE-SAT的语音编辑功能,可以很自然的拼接人工录音和合成变量,流畅度相较于原先的方案更高。
PaddleSpeech自2022年5月20日发布1.0版本以来,已经接收到30+来自活跃开发者的代码贡献提交,其中有很多用户为我们提供了重大feature。
例如:
- GitHub用户@BarryKCL
将基于BERT的多音字预测模型g2pw(https://github.com/GitYCC/g2pW)转为onnx格式模型引入了PaddleSpeech的文本前端,使g2p wer大幅度下降(0.0260 -> 0.0240)
pr链接:
https://github.com/PaddlePaddle/PaddleSpeech/pull/2230
- GitHub用户@HighCWu
为我们贡献了多说话人的VITS模型和基于VITS的Voice Cloning和Voice Conversion代码示例
pr链接:
https://github.com/PaddlePaddle/PaddleSpeech/pull/2268
- GitHub用户@david-95
为我们贡献多个修复文本前端badcase的代码。
篇幅有限,热情的开发者们的代码贡献我们无法一一列举,但仓库中都留下了他们活跃的足迹,社区开发者们是PaddleSpeech的重要力量,欢迎更多开发者参与到PaddleSpeech的开发中!感谢各位开发者们的分享与贡献!
欢迎大家在GitHub中Star收藏,及时追踪最新发布!
项目传送门
https://github.com/PaddlePaddle/PaddleSpeech
https://gitee.com/paddlepaddle/PaddleSpeech
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~


















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









