







NLP (Natural Language Processing)自然语言处理是人工智能的一个子领域,它是能够让人类与智能机器进行沟通交流的重要技术手段,同时也是人工智能中最为困难的问题之一。因此,NLP的研究处处充满魅力和挑战,也因此被称为人工智能“皇冠上的明珠”。
目前各家主流深度学习框架,都开放了相应的 NLP 算法模型。其中,百度 PaddlePaddle 基于自身技术优势,在中文NLP领域提供丰富官方模型,全方位满足各种NLP任务需求。
1 月 20 日下午 ,第二期百度深度学习开发者·技术公开课在百度大脑创新体验中心开课。百度资深研发工程师为现场的开发者们介绍了 PaddlePaddle 在 NLP 方向开源模型及技术实践,Google 机器学习开发者专家和高级算法专家孔晓泉则讲述了基于 PaddlePaddle 的中文分词引擎应用案例。
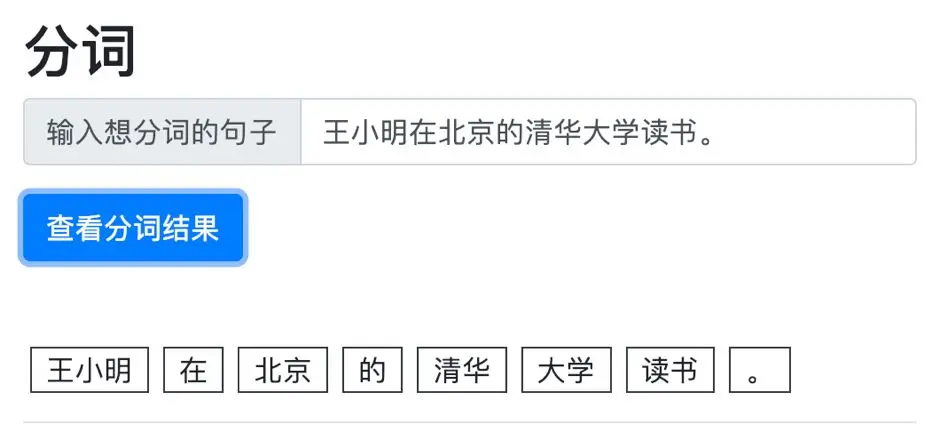
中文分词小试牛刀,100行代码的分词引擎实践
与大部分西方语言不同,书面汉语的词语之间没有明显的空格标记,句子是以字符串的形式出现,因此对中文进行处理的第一步就是进行自动分词,即将字符串转变成词语串,这也是处理中文的语义分析、文本分类、信息检索、机器翻译、机器问答等问题的基础。如果分词效果不好,很有可能会对后续的任务造成严重的影响。
谷歌机器学习开发者专家和高级算法专家孔晓泉,为大家分享了轻量级中文分词引擎——PaddlePaddle Tokenizer。该引擎基于PaddlePaddle Fluid API打造,充
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









