






深度学习入门-前言
本篇文章用于自己学习使用,其他人可以阅读,但不得用于商业用途。
P1-P4 Pytorch的安装以及环境的搭建
AnacondaPrompt下载安装
相关代码
import torch
print(torch.cuda.is_avaliable()) //检验我们环境是否安装完pytorch,一般GPU运行的输出True,没有GPU的报False也行
dir() //查看其中有哪些包
help() //查询如何使用
P5 Pytorch加载数据初认识
P5.1 加载数据的抽象理解
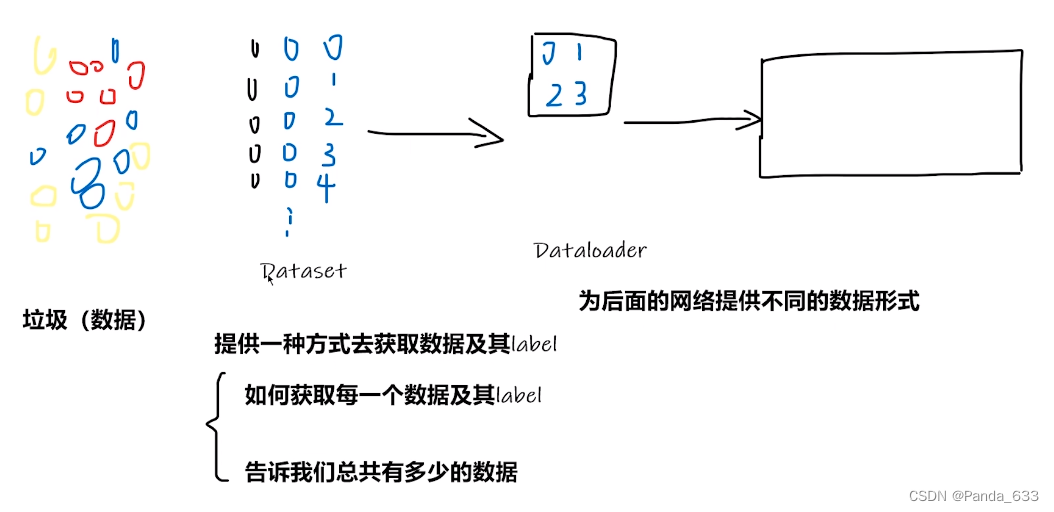
Dataset 从垃圾数据中获得我们需要的数据以及它的label
(黑色抽象圆圈为数据所对应的label,蓝色圆圈抽象为获得的数据,后面数字抽象为我们对获得数据的编号,以便我们了解数据的个数)
Dataloader为网络提供不同的数据形式
将前四个数据进行打包,然后送进后面的网络进行使用。
P5.2 数据的三种组织形式
第一种组织形式
ants文件夹中的图片数据全是各种不同形态的蚂蚁。那么ants就是这些图片数据的label。
第二种组织形式
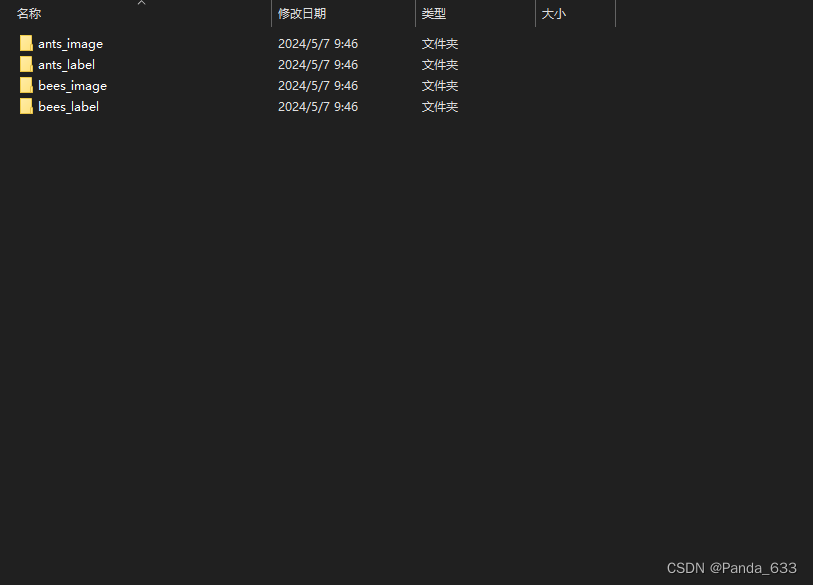
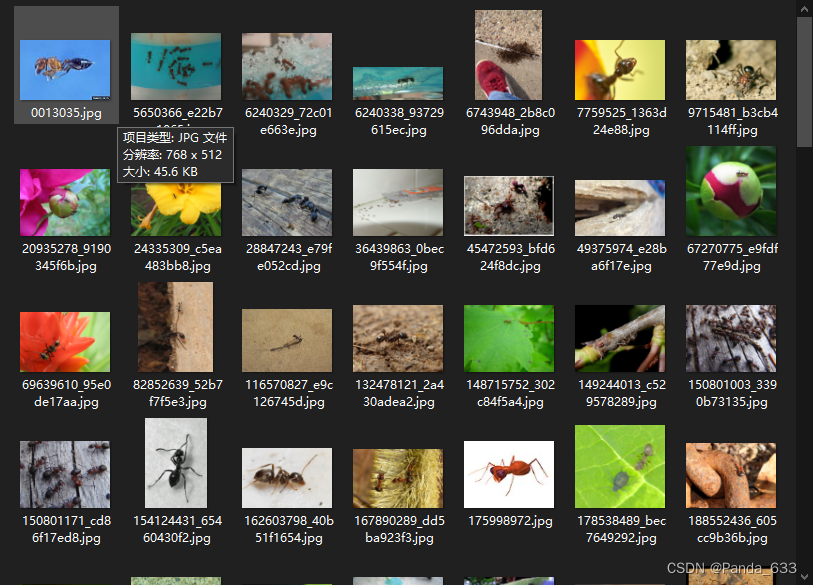
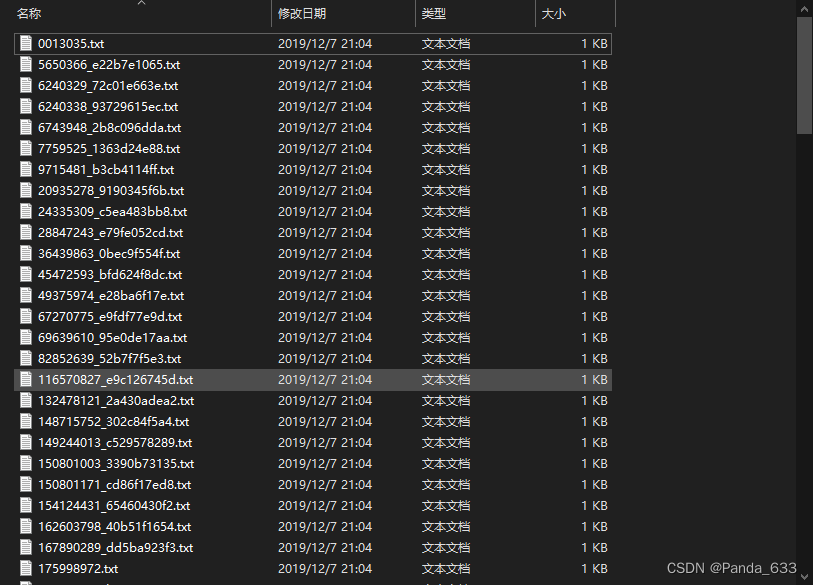
数据与label分开存放
还有一种形式,图片名就是label
相关代码
from torch.utils.data import Dataset

Dataset 是一个抽象类,所有的数据集都需要去继承这个类。所有子类都需要去重写__getitem__的方法,此方法用来获取数据对应的label。我们还可以重写__len__方法,告诉我们这个数据有多长。
P6-P7 Dataset类代码实战
from torch.utils.data import Dataset
import cv2 #视频里用的是另一个,这个没有安装
from PIL import Image #获取图片的相关信息
import os #获取图片的相关地址
class MyData(Dataset):
def __init__(self): //为我们的MyData类提供全局变量的拟定,方便后续方法的使用
def __getitem__(self, index):
P6.1检验一下部分代码的实现

imag_path = "F:\\learn_pytorch\\dataset\\hymenoptera_data\\train\\ants\\0013035.jpg" //获取图片绝对地址
img = Image.open(imag_path)
img.size #图片尺寸
img.show() #展示图片
P6.2想要获得图片文件的地址
import os
dir_path = "dataset\\hymenoptera_data\\train\\ants" #由于是在windows操作系统下,填写地址的时候一定要注意文件路径之间要用\\或者/来分开,避免转义
imag_path_list = os.listdir(dir_path) #这样就获取到了所有的图片名称列表,每一个元素都是一个对应图片的名称

P6.3 os库里拼接路径的方法
import os
root_dir = "dataset/hymenoptera_data/train" #定义源文件的路径,我的数据集放在了hymenoptera_data里面,根据个人调整即可
label_dir = "ants" #大家伙儿的标签都是蚂蚁
path = os.path.join(root_dir,label_dir) #在Windows与Linux中,/ 符号含义不一样,使用os.path.join()方法把两个路径拼接起来就避免了出错的麻烦
就像这样

P6.4补充刚才的MyData类里的方法
class MyData(Dataset):
def __init__(self): #self相当于为我们的MyData类拟定了一个全局变量,方便后续方法的使用
self.root_dir = root_dir #路径源文件夹
self.label_dir = label_dir #标签文件夹
self.path = os.path.join(self.root_dir,self.label_dir) #拼接路径
self.img_path = os.listdir(self.path) #获得图片路径
def __getitem__(self, index):
img_name = self.img_path[index] #图片名是图片名列表的元素
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) #拼接路径
img = Image.open(img_item_path) #加载图片,不是显示,显示是img.show()
label = self.label_dir #标签是对象的标签文件
return img, label #这个函数返回了两个值,一个是img文件,另一个是它的标签
def __len__(self):
return len(self.img_path) #返回 图片数据的长度
P6.5总的来看看
import os
from torch.utils.data import Dataset
import cv2
from PIL import Image
class MyData(Dataset):
def __init__(self,root_dir,label_dir): # self相当于定义了一个class中的全局变量
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, index):
img_name = self.img_path[index]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
##看看做的对不对
img,label = ants_dataset[1]
img.show()
没毛病
P8-P9 Tensorboard的使用
新建一个py文件,给它导个包
from torch.utils.tensorboard import SummaryWriter
在PyCharm中按住Ctrl点击包或者函数可以看它的用法
来看看SummaryWriter的用法
from torch.utils.tensorboard import SummaryWriter
# create a summary writer with automatically generated folder name.
writer = SummaryWriter() #定义实例后,可以不写任何东西
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# create a summary writer using the specified folder name.
writer = SummaryWriter("my_experiment") #定义实例后,可以写它的文件夹
# folder location: my_experiment
# create a summary writer with comment appended. #定义实例后,可以设置一些参数,LR_0.1是对应的学习速率,BATCH_16是对应的batchsize,创建后会在文件后面添加相关信息
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
P7.1 add_scalar()的使用以及TensorBoard的安装
先来安装TensorBoard模块,用Anaconda Prompt,切换至pytorch环境下执行 pip install tensorboard
来看看函数的用法,按住Ctrl点击它,查看它的用法
def add_scalar(
self, #实例对象,添加一个标量数据去summary
tag, #图表的标题
scalar_value, #对应所保存的数值,一般作为图表的Y轴
global_step=None, #训练到多少步,一般作为图表的X轴
walltime=None, #等待时间
new_style=False,
double_precision=False,
):
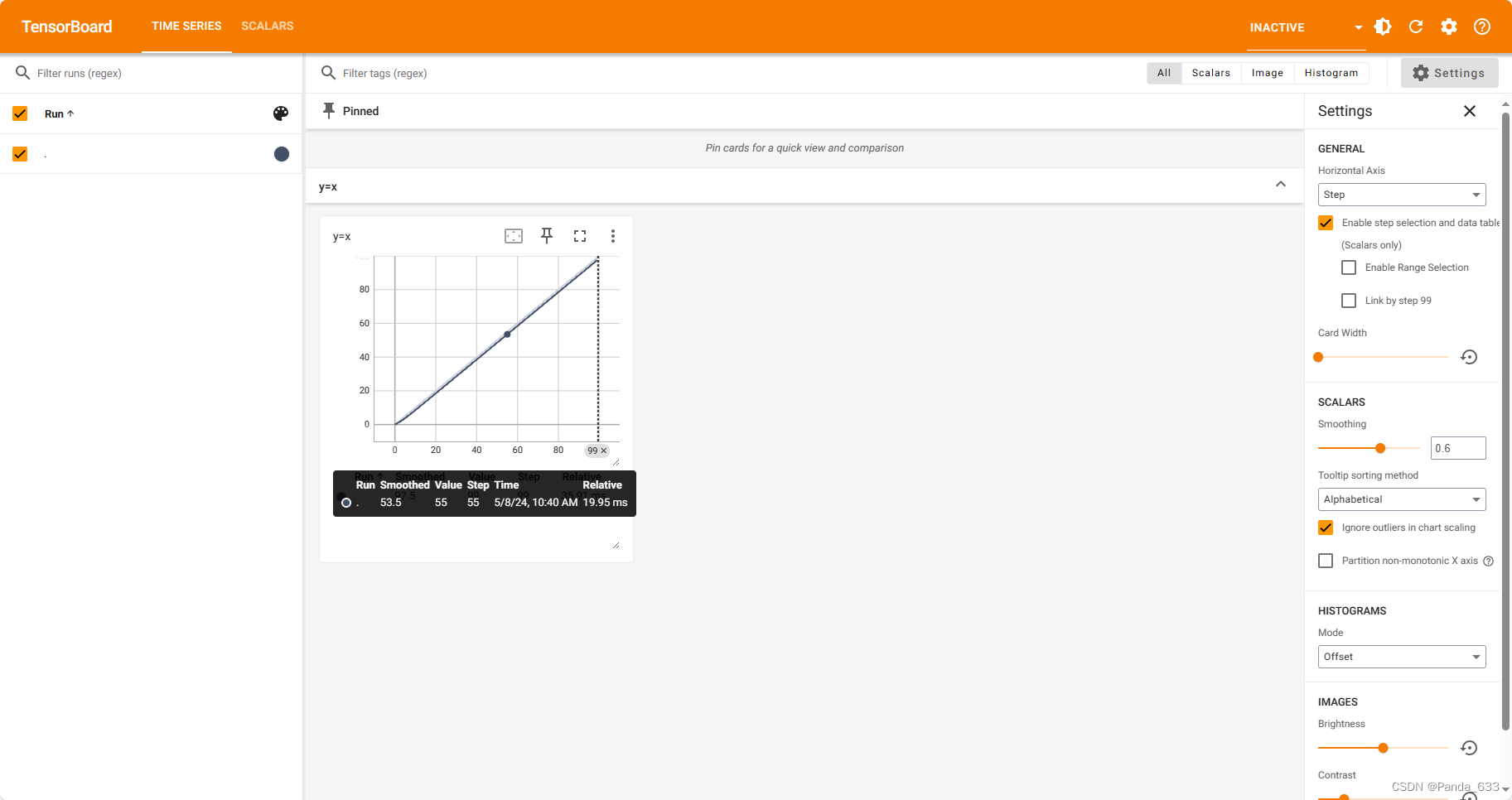
浅试一下
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
可以看到文件栏中多了logs文件夹
P7.2打开项目文件
这个terminal所在的地址就是我们项目文件夹的地址
执行命令 tensorboard --logdir=“事件文件所在的文件夹的名称”
我们能观察到,terminal打开的终端窗口是主机的6006窗口
TensorBoard 2.16.2 at http://localhost:6006/

点击一下,就可以看到了。按Ctrl+c进行取消
为了避免多人使用同一个端口,我们指定新的端口(命令行加一个参数,port)
tensorboard --logdir=logs --port=6007

P7.3同一个图片发生了里合
同一个事件文件名字记录了不同的事件操作会导致里合,因为从writer中写入新的事件的过程中,writer自身也记录了上一个事件的内容(这两步的tag都为“y=2x”)
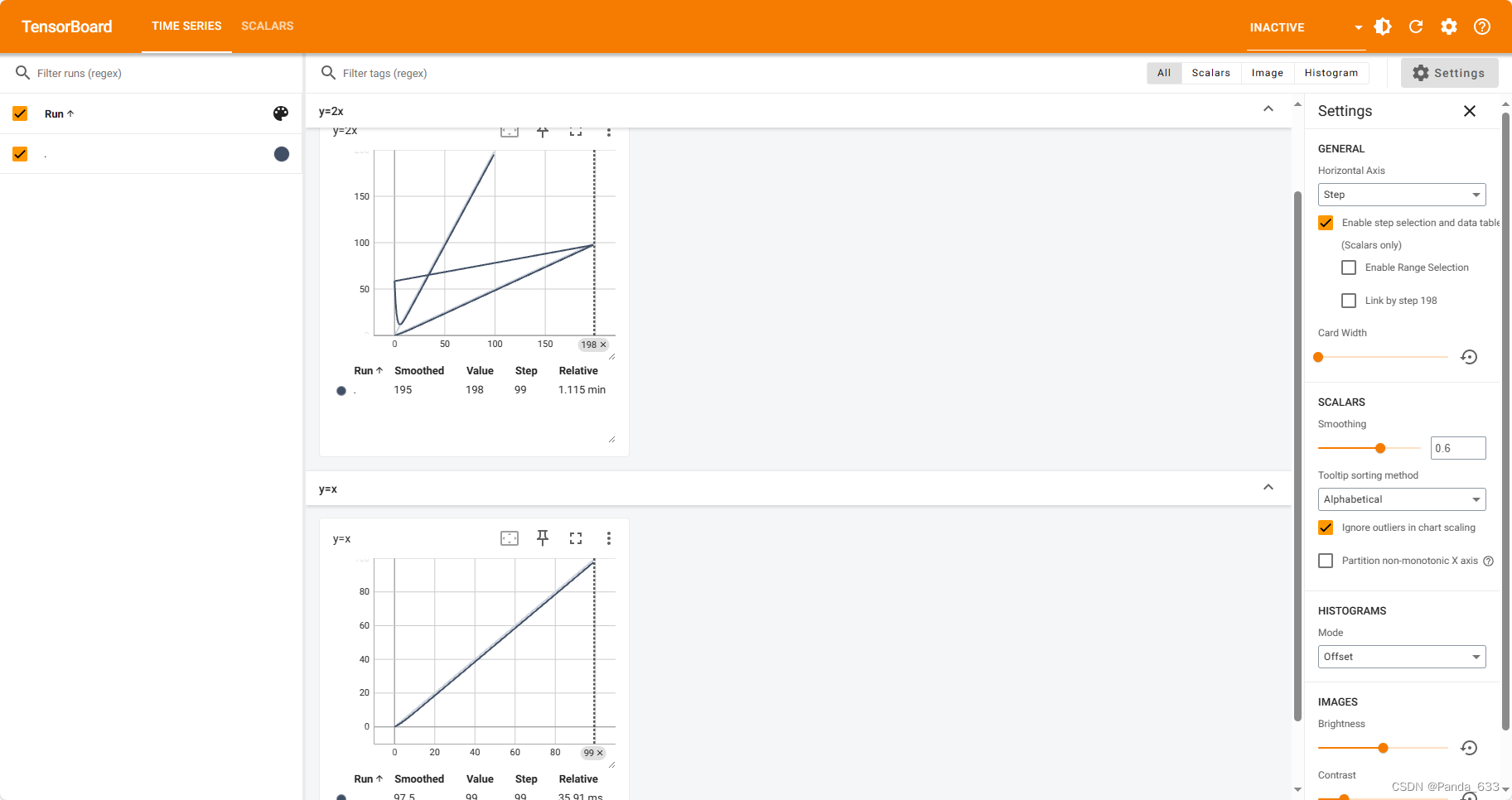
所以我们如何解决这个问题呢?有两种方法来解决。
第一种:我们可以停止程序的运行并将logs下对应的文件全部删除再重新开始。
第二种:官方推荐的方法:创建子文件夹。写一个新的SummaryWriter(“新的文件夹名称”)。
P8.1 add_image()的使用
def add_image(
self, #实例
tag, #图表名
img_tensor, #注意图像显示函数中这个元素的数据类型,torch.Tensor,numpy.ndarray, or string/blobname
global_step=None, #训练步骤
walltime=None, #等待时间
dataformats="CHW" #img_tensor数据的形状,"CHW"还是"HWC"还是"HW"
):
"""Add image data to summary.
Note that this requires the ``pillow`` package.
Args:
tag (str): Data identifier
img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
seconds after epoch of event
dataformats (str): Image data format specification of the form
CHW, HWC, HW, WH, etc.
"""
from PIL import Image
image_path = "dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(image_path)
print(type(img))
#我们发现此时的数据类型是<class 'PIL.JpegImagePlugin.JpegImageFile'>,因此不能直接用于add_image()
我们可以用opencv包来操作,也可以用numpy来转化数据类型
#numpy方法
import numpy as np
from PIL import Image
image_path = "dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(image_path)
img_array = np.array(img)
#这样数据类型就是numpy.array类型了
P8.2 关于add_image()方法中 dataformats的设置
即使我们将Jpg型数据转化为np.array类型的数据,代码跑的时候依然会报错。
经排除一系列的错误之后,我们将目光聚焦于 datraformats参数的设置。

关于数据的形状,默认是(3,H,W)。(3个通道,高度,宽度)的数据。
我们查看刚才的img_array数据形状
print(img_array.shape)
发现打印的结果是(512,768,3)所以它的数据类型本质上是(高度,宽度,3个通道)即(H,W,C)形的数据。
所以参数dataformats要设置成(HWC)
完整操作
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
image_path = "dataset/hymenoptera_data/train/bees/16838648_415acd9e3f.jpg"
img = Image.open(image_path)
# print(type(img))
img_array = np.array(img)
writer.add_image("test",img_array,1,dataformats="HWC")
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
运行完毕后,去终端看一下窗口
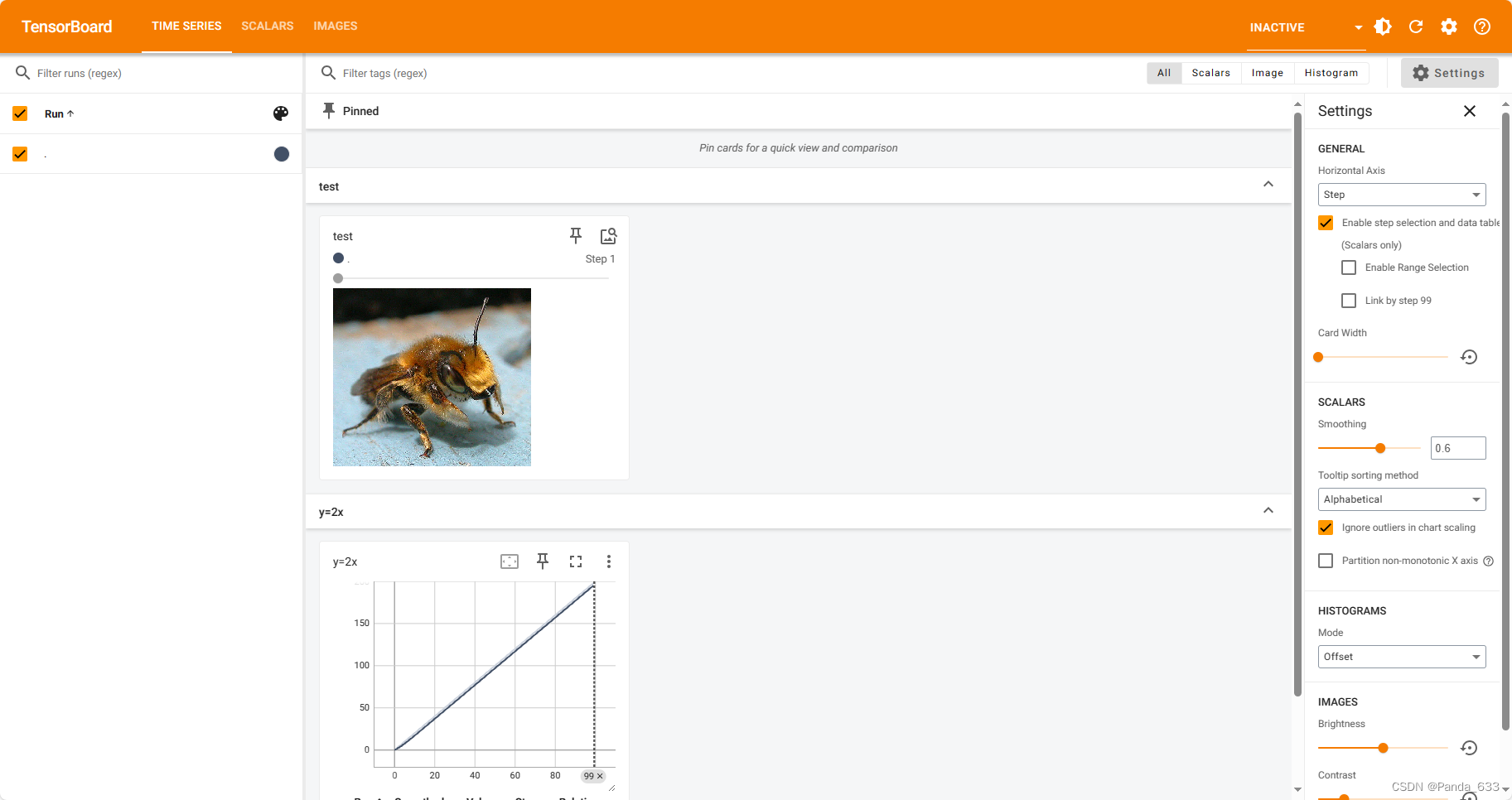
再改个路径,改个训练步数从1变2,终端窗口刷新。
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
image_path = "dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(image_path)
# print(type(img))
img_array = np.array(img)
writer.add_image("test",img_array,2,dataformats="HWC")
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
可以看到有新的图片加载了,并且,这个图片可以拖动按钮,从而方便我们观察数据的变化。
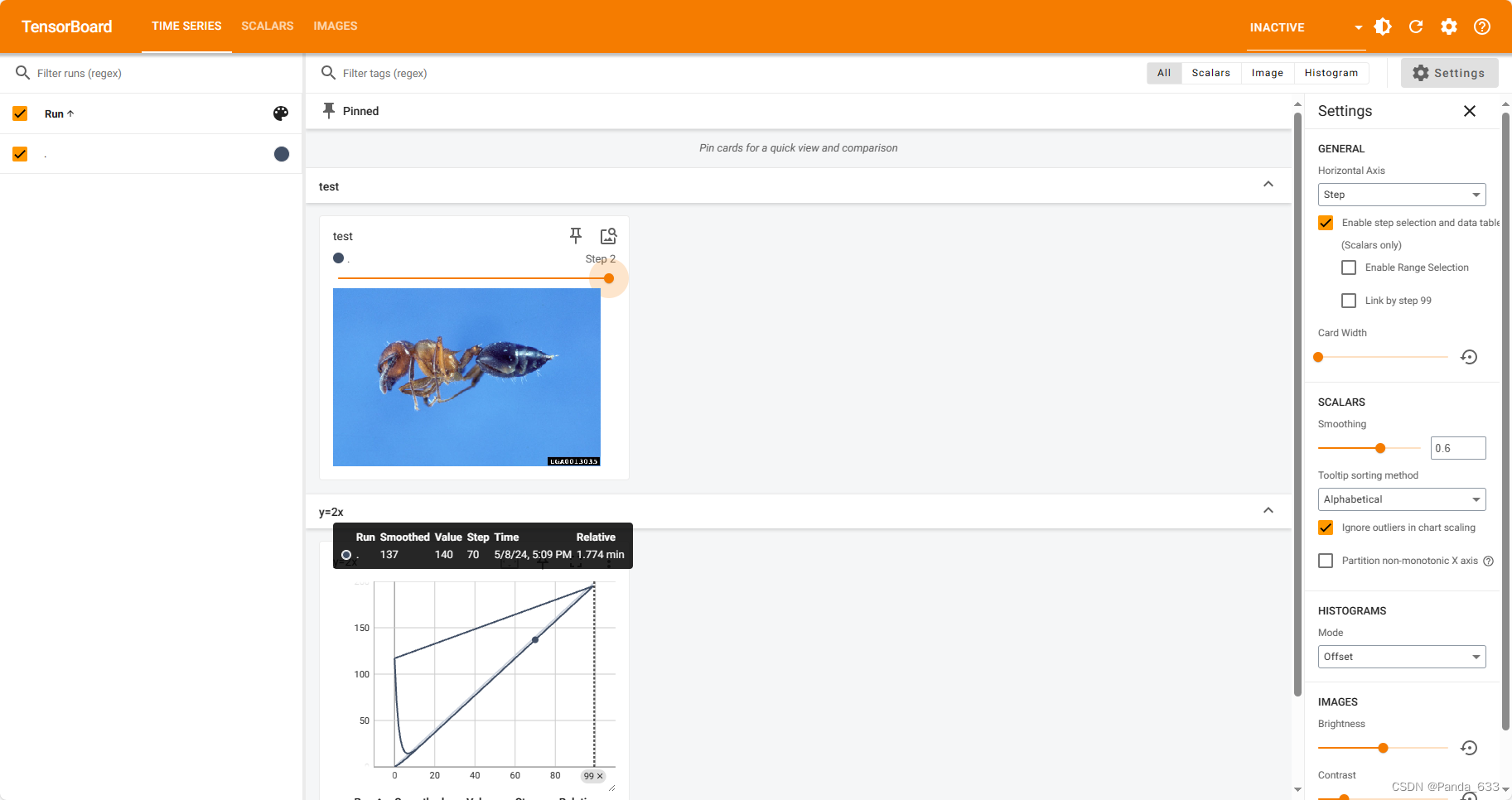
PS:忽视这里图表的里合哈哈哈,没有更改它的tags。
P10-P11 transforms的结构与用法
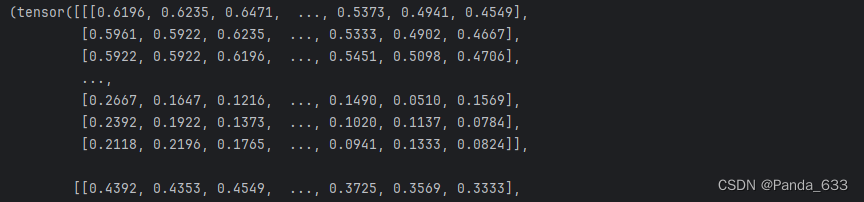
Tensor类型
通过transform.ToTensor解决两个问题
1.如何使用transform
2.Tensor数据类型相较于普通类型有什么区别,以及为什么我们需要Tensor数据类型。
from PIL import Image
img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
print(img)
控制台输出:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512 at 0x1EF9F09D7F0>
所以我们可以得知,Image.open()方法给出的是PIL_JPEG类型数据,模式为RGB,大小,逻辑地址。
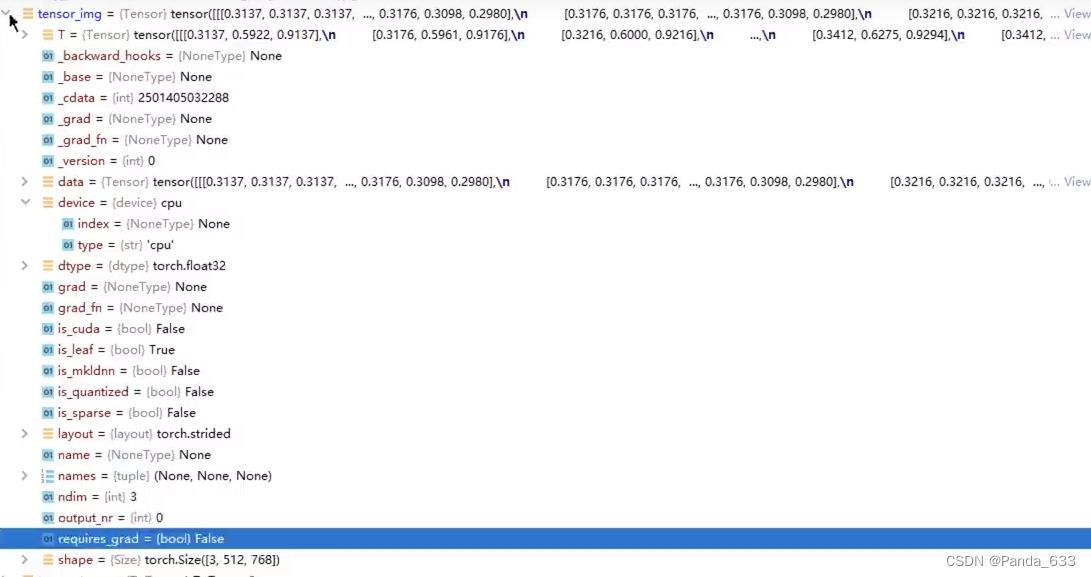
借助函数transforms.ToTensor(object)来把数据类型转换为 Tensor
tensor_trans = transforms.ToTensor() #新建一个transforms.ToTensor()类
tensor_img = tensor_trans(img) #将我们刚才的JPEG数据类型转换为tensor数据类型,以便后续使用
这里的 transforms.ToTensor(object),里面的数据是PIL_image类型或者numpy.ndarray类型。
简单来讲一下第一个问题,如何使用transform
我们将这个库抽象成工具箱。箱子里有很多工具图纸,我们想要使用工具完成我们的需求就需要先使用图纸制作工具,定义变量实际上就实现了我们打造工具的过程。然后我们用定义的变量,去解决待解决的问题就好。
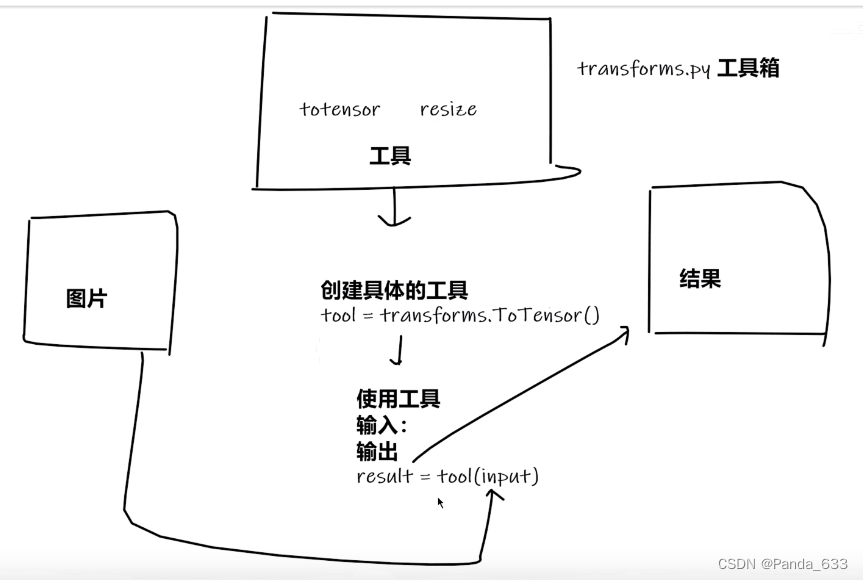
第二个问题,我们在神经网络中使用的函数大多数都是要用Tensor类型数据进行操作。我们的两种读取图片的方法一种是用Image.open(“路径”)读取为PILJPEG类型;一种是用cv.imread(“路径”)来进行读取获得到numpy.ndarray类型。两者都可以作为transforms.ToTensor()的输入数据类型。可以看到Tensor数据类型包含很多参数,包括反向传播、梯度等参数,为我们后续进行神经网络的训练以及使用提供了便利。
完整代码
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path) #将图片进行读取获得的数据类型是PILImage类型的数据
# print(img)
cv_img = cv2.imread(img_path) #将图片进行读取获得的数据是numpy.ndarray类型的数据
writer = SummaryWriter("logs")
#1.transforms该如何使用(python)
tensor_trans = transforms.ToTensor() #新建一个transforms.ToTensor()类
tensor_img = tensor_trans(img) #将PIGimage类型数据转换成Tensor类型的数据
writer.add_image("Tensor_img",tensor_img)
writer.close()
P12-P13常见的TransForms
如下图所示
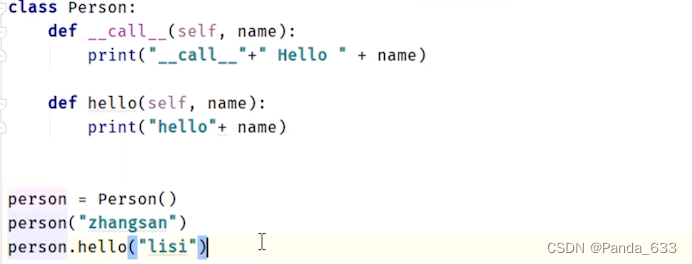
所定义的内置函数call,可以直接通过对象实例进行参数的设置。另一个是调用对象实例的hello放法。
ToTensor的使用
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter()
img = Image.open("dataset/hymenoptera_data/train/ants/9715481_b3cb4114ff.jpg")
#1.ToTensor的使用
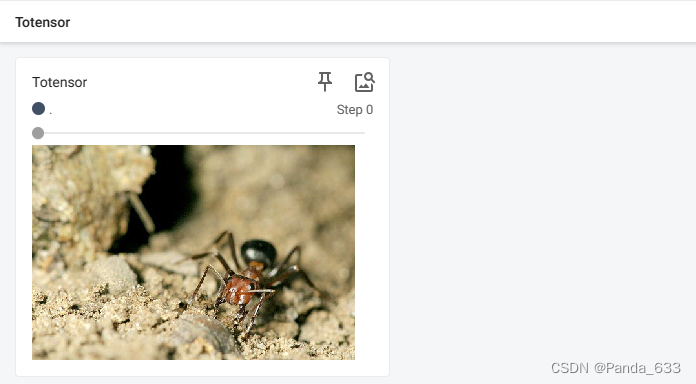
trans_totensor = transforms.ToTensor() #用蓝图打造工具,定义对象实例
img_tensor = trans_totensor(img) #ToTensor()方法传入参数为PILImage类型或者numpy.ndarray类型的数据,输出为tensor类型的数据
writer.add_image("Totensor",img_tensor)
writer.close()
展示效果
Normalize的使用(归一化)
计算公式(这里带的是上述代码中的0.5)

该方法的输入为Tensor类型的Image,因此我们在使用前一定先把数据类型转化成Tensor,mean是平均值,std是标准差,这里的图片是RGB三个通道,因此我们用一个三维列表来进行均值的表示,标准差也一样。
print(img_tensor[0][0][0])
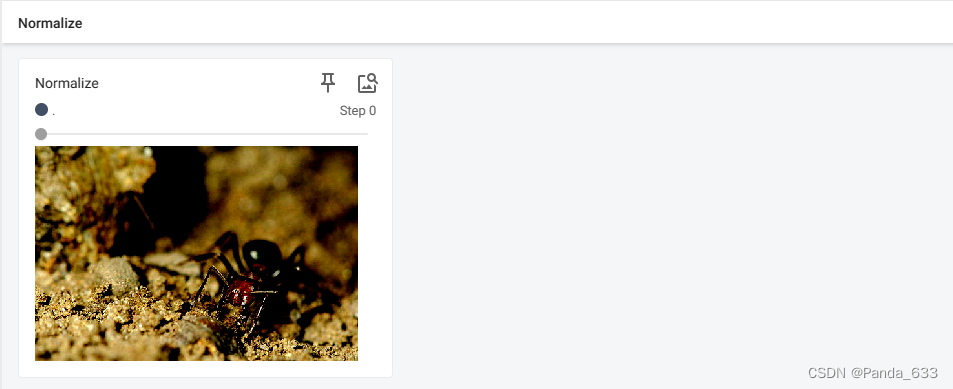
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor) #输出,对图片进行一个归一化
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()
展示效果
Resize(大小变化)
# Resize的使用
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img) #PILImage ————> PILImage
print(img_resize)
img_resize = trans_totensor(img_resize) #PILImage ————> Tensor
writer.add_image("Resize",img_resize,0)
注意上面代码中的transforms.Resize((512,512)),里面是一个元组的形式,并不是简单的两个数字。
Compose - Resize

# Compose - resize
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
其中trans_resize_2的类型是<class ‘torchvision.transforms.transforms.Resize’>
Compose的用法
后面一个参数的输入要与前面一个参数的输出保持类型上的一致。
trans_resize_2的类型为PILImage,作为后面trans_totensor的输入,将PILImage数据类型转化成Tensor数据类型。
RandCrop的使用(随机裁剪)
#RandomCorp
trans_rancorp = transforms.RandomCrop((200,100))
trans_compose_2 = transforms.Compose([trans_rancorp,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
先确定裁剪后的尺寸,注意不可大于原图的尺寸
再用Compose方法将原来的PILImage数据转换成Tensor类型的数据
用循环遍历来对每一个图片进行add_image操作
总结
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants/9715481_b3cb4114ff.jpg")
# #1.ToTensor的使用
trans_totensor = transforms.ToTensor() #用蓝图打造工具,定义对象实例
img_tensor = trans_totensor(img) #ToTensor()方法传入参数为PILImage类型或者numpy.ndarray类型的数据,输出为tensor类型的数据
# writer.add_image("Totensor",img_tensor)
# writer.close()
# print(1)
# #2.Normalize的使用
# print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #该方法的输入为Tensor类型的Image,因此我们在使用前一定先把数据类型转化成Tensor,mean是平均值,std是标准差,这里的图片是RGB三个通道,因此我们用一个三维列表来进行均值的表示,标准差也一样。
img_norm = trans_norm(img_tensor) #输出,对图片进行一个归一化
# print(img_norm[0][0][0])
# writer.add_image("Normalize",img_norm)
#3.Resize的使用
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img) #PILImage ————> PILImage
print(img_resize)
img_resize = trans_totensor(img_resize) #PILImage ————> Tensor
# writer.add_image("Resize",img_resize,0)
#Compose - resize
trans_resize_2 = transforms.Resize(512)
print(type(trans_resize_2))
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
# writer.add_image("Resize",img_resize_2,1)
#RandomCorp
trans_rancorp = transforms.RandomCrop((200,100))
trans_compose_2 = transforms.Compose([trans_rancorp,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
学习这几个方法的最终目的是掌握当我们遇到新的方法时,我们应该如何去通过查询官方文档来了解这个函数如何使用。
首先看它的__init是如何定义的。里面需要哪些参数,什么类型的数据。它的输出是什么。
P14 torchvision中数据的使用
数据集的使用
官网中有很多用来训练的数据集,计算机视觉,声音,文本等。我们本节主要使用的是CIFAR10数据集,它是由多个32*32像素组成的图片以及它所具备的标签来构成的数据集。大小约为100MB左右。像COCO数据集,是由多个手写文字来组成的数据集,大小约为30G不利于我们进行日常的训练。
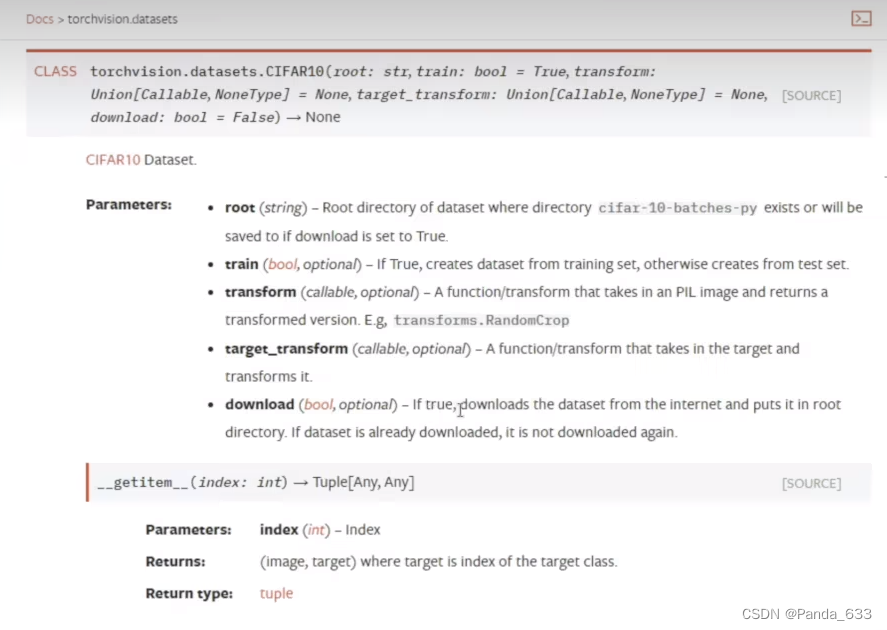
数据集的构成,参数有文件夹,是否为训练集,transform的类型,target_transform的类型,以及download是否下载。
1.首先文件夹名称不必多说,相对路径也行,绝对路径也ok。
2.是否为训练集其值为bool类型。True为生成一个训练集,False为生成一个测试集。默认True。
transform参数一般可以设置为我们前面用Compose()方法来定义完的Tensor数据类型,除了数据类型外,我们还可以用Compose来对我们已有的图片进行重新定义大小,随机裁剪,归一化等一系列操作。
3.是否准许下载。我们一般将其设置为True。如果本地没有的话默认会给我们下载数据集。
完整代码
import torchvision
from torch.utils.tensorboard import SummaryWriter
#我们定义我们数据集的transform,并使用Compose方法来对其进行初步的加工
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#训练集跟测试集,各个参数都设置一下
train_set = torchvision.datasets.CIFAR10(root="./P14_dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./P14_dataset",train=False,transform=dataset_transform,download=True)
###我们看看这个测试集是什么类型的数据
# print(test_set[0])
# print(test_set.classes)
#
# img,target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])
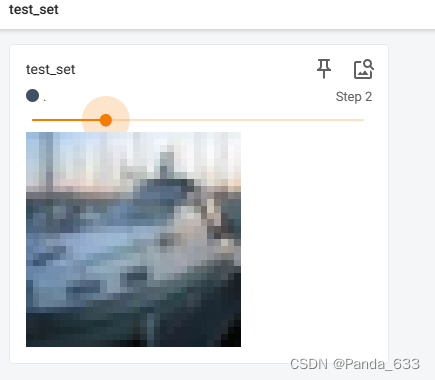
#定义我们的TensorBoard,文件夹名称为p14
writer = SummaryWriter("p14")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close() #千万千万别忘记关闭
然后去Terminal端输入 tensorboard --logdir=p14
端口默认
点击
查看效果
P15 DataLoader的使用
基础讲解
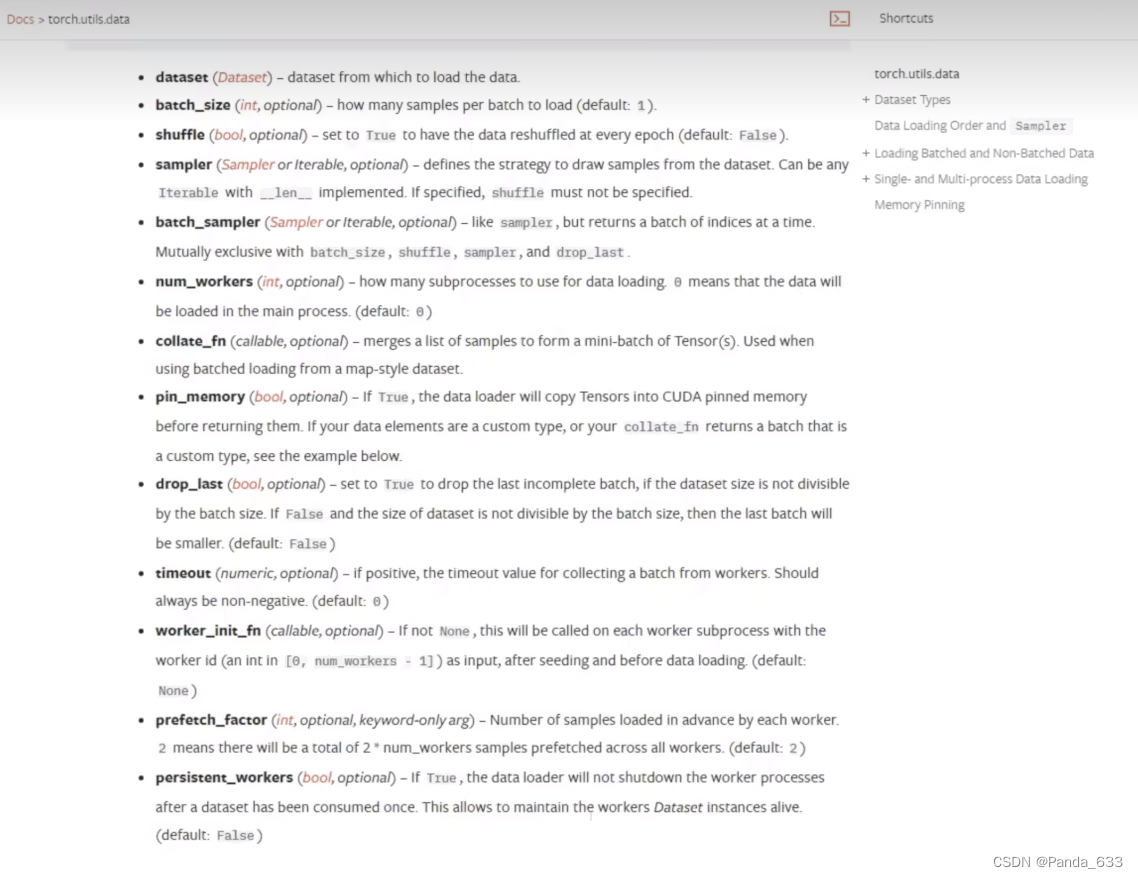
dataset 什么数据从哪
batch_size每次从牌堆里取几张
shuffle是否打乱,默认False,不打乱
sampler
batch_sampler
num_workers加载数据时是单进程还是多进程,在Windows系统下有可能会报错。出现BrokenPipeError类型的错误时,可以将这个参数设置为0.
drop_last当我们从总共100张牌的牌堆中每次摸三张牌。有一张会单独被摸出来。若此参数设置为True时,我们将最后一张牌舍弃。若为False,我们保留最后一张牌。默认为False。
测试数据集中第一张图片以及它的target
import torchvision
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./P14_dataset",train=False,transform=torchvision.transforms.ToTensor())
test_dataloader = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=True)
img,target = test_data[0]
print(img.shape)
print(target)

我们可以看到,此时输出的第一张图片的信息,是三通道,像素32*32,target = 3
让我们遍历一下每一组图片看一下
for data in test_dataloader:
img,target = data
print(img)
print(target)

可以看到img是tensor数据类型,test_dataloader将它分成64张图片每组,且每张图片是3通道,大小为32*32
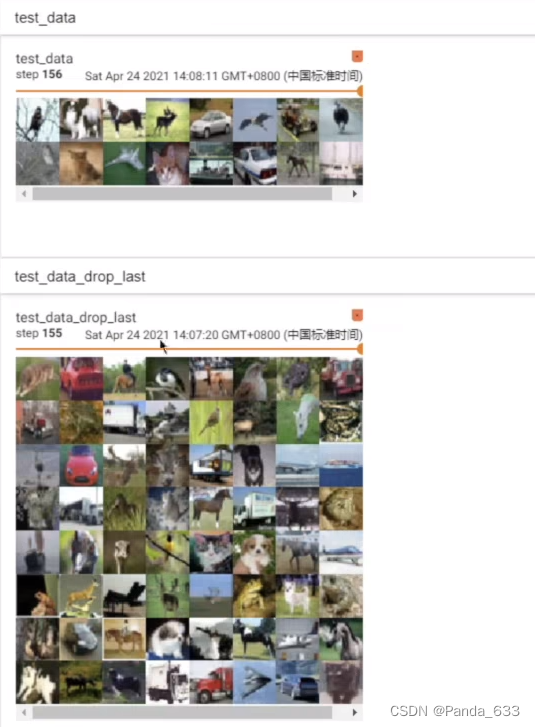
完整代码
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./P14_dataset",train=False,transform=torchvision.transforms.ToTensor())
test_dataloader = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=True)
img,target = test_data[0]
print(img.shape)
print(target)
step = 0
writer = SummaryWriter("P15")
for data in test_dataloader:
img,target = data
# print(img.shape)
# print(target)
writer.add_images("test_dataloader",img,step)
step += 1
writer.close()
效果(上述代码为删除不足64张图片的组,如果不删可以更改DataLoader里的drop_last参数)
P16 神经网路的基本骨架-nn.Module的使用
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self): #重写实例化方法
super().__init__()
def forward(self,input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
简单的看一下nn.Moudle的使用
对实例化方法进行重写,forward方法实现输入加一后作为输出返回,在函数主体中运行。

打印结果如图所示。
P17 卷积操作
这里拿2维卷积来举例子
CLASS torch.nn.Conv2d(
in_channels, #输入通道数
out_channels, #输出通道数
kernel_size, #卷积核尺寸
stride=1, #卷积核移动步长
padding=0, #是否填充
dilation=1, #卷积过程中核的距离
groups=1,
bias=True, #偏置
padding_mode='zeros',
device=None,
dtype=None)

卷积的演示如下图所示
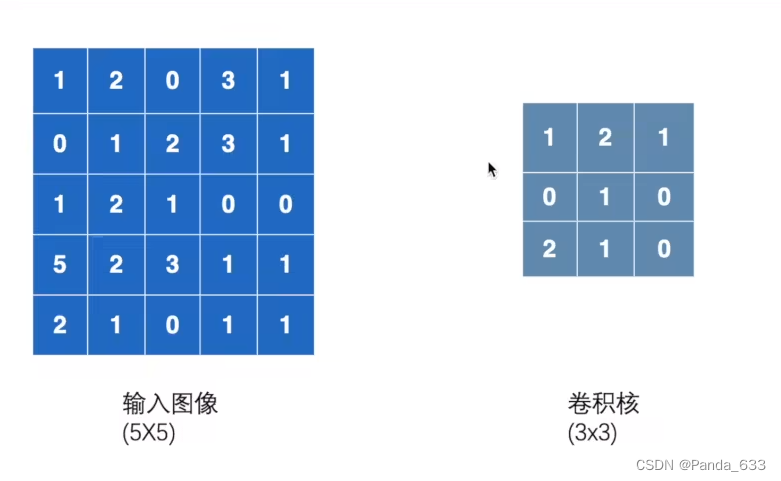
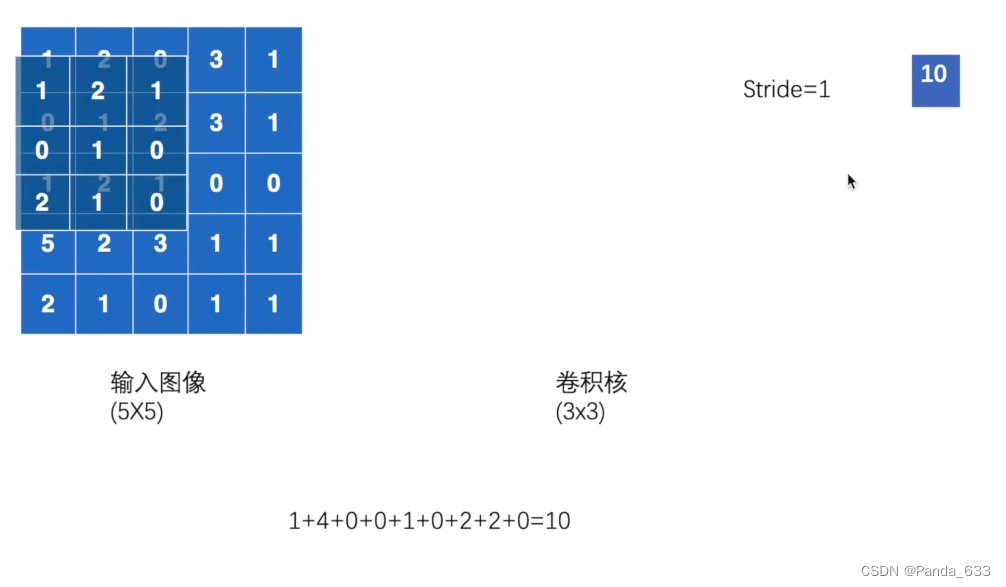
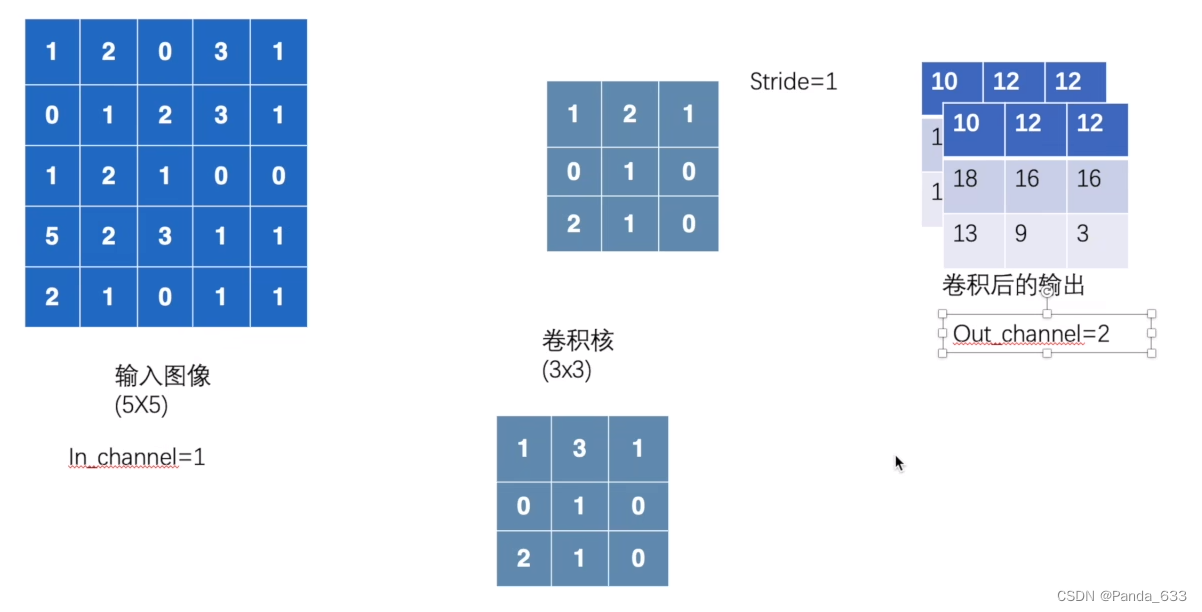
卷积核与输入图像做点乘,即为输出图像的第一个值。
然后移动卷积核,重复上述步骤,直到完成输出。
import torch
import torch.nn.functional as F
input = torch.tensor([
[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]
])
kernel = torch.tensor([
[1,2,1],
[0,1,0],
[2,1,0]
])
#形状(1,1,5,5) batchsize = 1,1个通道,5*5的一个矩阵
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))
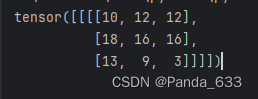
output = F.conv2d(input,kernel,stride=1)
print(output)
输出结果如下图所示
注意:我们在设置该方法的in_channels参数时,必须要将简单的二维矩阵转换成对应的形式。这个参数对应三个或四个数字。如下图。
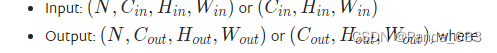
我们可以用
torch.reshape(变量名,格式)
来帮助我们实现格式的转换。完成格式的转换后,才能正常使用卷积操作。
改变一下stride的值,我们发现输出矩阵也发生变化了
output = F.conv2d(input,kernel,stride=1)
print(output)
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
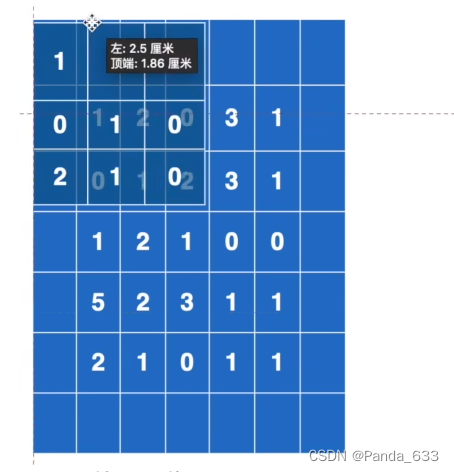
当Padding = 1时,卷积核与输入矩阵做点乘效果如下图所示。padding起到了在输入矩阵外围扩了一圈,并赋值为0。
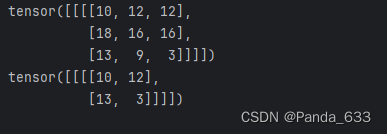
如下图所示,对于两个卷积核,当out_channel设置为2的时候,卷积后输出两个矩阵,很多算法都是采用多个输出通道来实现不同结果的对比。
代码展示
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./P14_dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size = 64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1 = Conv2d(in_channels = 3, out_channels = 3, kernel_size = 3, stride = 1, padding = 0)
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
print(tudui)
输出结果

加载数据、对图片做卷积
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./P14_dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size = 64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1 = Conv2d(in_channels = 3, out_channels = 3, kernel_size = 3, stride = 1, padding = 0)
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
print(tudui)
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# 输入size torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs,step)
# 输出size torch.Size([64, 3, 30, 30])
writer.add_images("output",imgs,step)
step += 1
报错了,因为 输出的channel与输出的channel不一样。所以我们需要reshape一下output
torch.Size([64, 3, 30, 30]) —>[xxx,3,30,30]
这个方法不严谨!!!!
不知道xxx的话就填写-1。会根据后面的输出尺寸、通道进行自动更改。
torch.reshape(output,(-1,3,30,30))
完整代码
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./P14_dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size = 64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1 = Conv2d(in_channels = 3, out_channels = 3, kernel_size = 3, stride = 1, padding = 0)
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
print(tudui)
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs,step)
# torch.Size([64, 3, 30, 30])
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",imgs,step)
step += 1
复习一下打开terminal
tensorboard --logdir=logs

做了实验看起来是随机的。
(蓝色忧郁系列)















 6239
6239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









