







一、集合
集合是无序的,本身自带去重属性
理解:集合解决了判断一个元素是否在列表中的问题,不用通过循环的方式一一去比对,减少了内存的消耗。
2.集合运算
列表,字典,集合判断一个字符是否存在均使用x in s
读取所有文件内容
集合是无序的,本身自带去重属性
理解:集合解决了判断一个元素是否在列表中的问题,不用通过循环的方式一一去比对,减少了内存的消耗。
1.集合的书写形式
(1)第一种形式
list=[1,4,5,3,5,6,7,9]
#去重
list1 = set(list)
#交集(intersection)
list2 = set([2,4,6,88,66,77])
print(list1.intersection(list2))
#并集(union)
print(list1.union(list2))
#差集(difference)
print(list1.difference(list2))
list3 = set([4,6])
#子集(issubset)print(list3.issubset(list1))
#父集(issuperset)
print(list1.issuperset(list3))
#对称差集(取两个列表均没有的symmetric_difference)
print(list1.symmetric_difference(list2))
list4 = set([200,100])
#list1和list2在没有相同项的时候返回True,否则返回False
print(list1.isdisjoint(list2))#交集
a = list1 & list2
#并集
a = list2 | list2
#差集
a = list1 - list2
#对称差集
a = list1 ^ list22.集合运算
#增
list1.add(99)
list1.update([15,20,18])
#删
list1.remove(15)
list1.discard(99)列表,字典,集合判断一个字符是否存在均使用x in s
二、文件操作
1.文件的打开与读取
f = open("yesterday",encoding="utf-8")读取所有文件内容
f.read()f.readline()f.readlines()for line in f:
if count == 9:
print('--------我是分割线---------')
count +=1
continue
print(line)
count +=1写入模式(不可读,不存在则创建、存在则删除内容)
f = open("yesterday","W",encoding="utf-8")f = open("yesterday",a",encoding="utf-8")f = open("test","rb")
f = open("test","wb)
f = open("test","ab")返回文件的当前位置读/写指针在文件位置
f.tell()f.seek()f = open("yesterday","r",encoding="utf-8")
f_new = open("yesterday2","w",encoding="utf-8")
for line in f:
if "" in line:
line = line.replace("self","new")
f_new.write(line)#声明文件编码
f.encoding
#获取文件名称
f.name
#截取字符
f.truncate(10)
#关闭文件
f.close()虽然Python有回收机制,但是在对文件进行操作时常常忘记关闭,可采用以下方式打开文件
with open('log','r') as f:
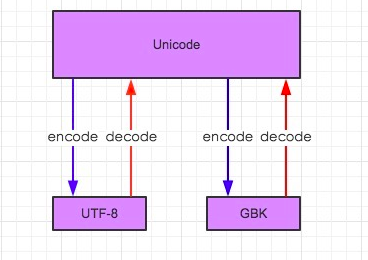
...1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









