









目录
1.ConfigurationClassPostProcessor注册原理
2.Spring调用BeanFactoryPostProcessor接口
3.ConfigurationClassPostProcessor类的执行流程
在看本篇时推荐去看一下Spring的大致框架说明。
一、相关注解及接口
1.相关注解
这里只介绍几个常用相关的注解:
- @Bean注解:注解在@Configuration注解类中的方法上,标志着方法的返回值将会作为一个bean对象保存在Spring工厂中;
- @Import注解:只能注解在@Configuration注解类上才能起作用,其功能是将一个未被Spring扫描到的类引入到Spring工厂中,引入的类可以是普通的类,也可以是@Configuration配置类;
- @ComponentScan注解:在@Configuration类中配置,功能类似传统XML中的<component-scan/>标签,用来扫描某个包下的bean对象。这个注解也有lazyInit属性的配置。
2.相关接口
常用接口也就两个,分别如下:
- ImportSelector接口:需要搭配@Import注解使用,相当于@Import的功能延伸,@Import只能直接引入类,而该接口可以进行一定的逻辑处理后再返回需要引入的类;
- ImportBeanDefinitionRegistrar接口:针对经过@Configuration配置类为入口获取到的类进行处理,经常与@Import和ImportSelector接口搭配使用,如使用@Import引入一个类,再使用该接口将引入的类注册到bean工厂中。
二、流程分析
流程图如下:
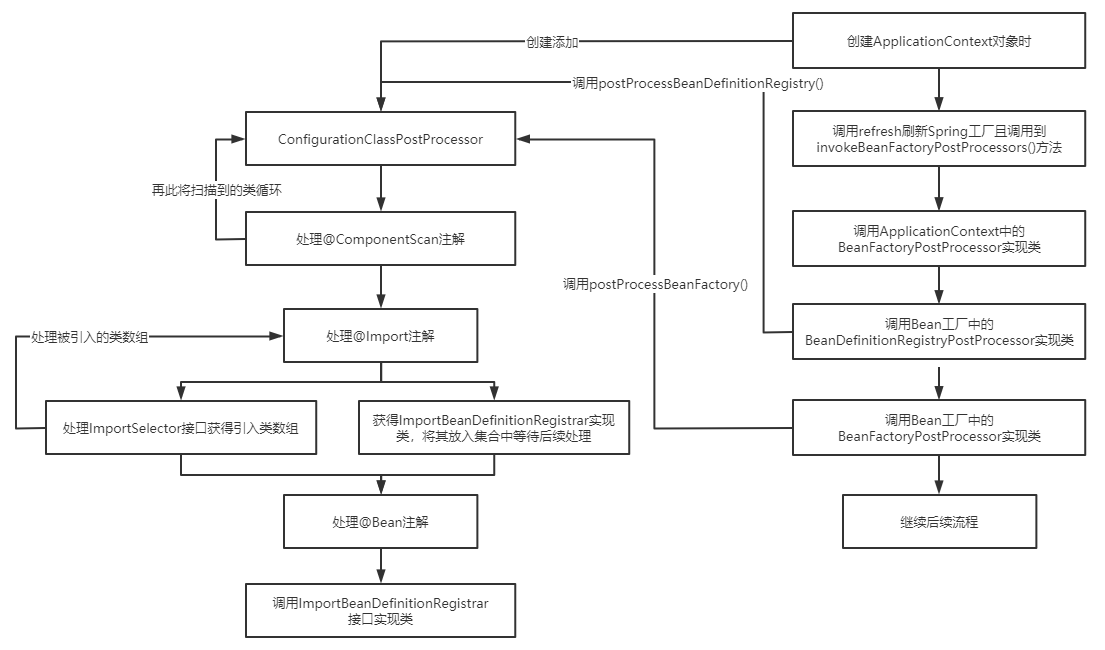
接下来根据上面流程大致分析一下其源码流程。
三、源码分析
处理@Configuration配置及相关注解接口的类实际上是BeanFactoryPostProcessor接口的实现类ConfigurationClassPostProcessor,这个类由实现了BeanDefinitionRegistryPostProcessor接口,这两个接口等下会说明其分别的调用顺序和功能。
1.ConfigurationClassPostProcessor注册原理
既然知道了@Configuration配置类是在ConfigurationClassPostProcessor类中完成的,那么先来看下这个类是在哪个流程中被添加到bean工厂获取Spring上下文中的。
1.1 传统Spring的XML配置
如果是传统的Spring项目的话便是通过在XML配置文件中配置<annotation-config/>标签来完成相关功能的使用的。关键源码如下:
public class ContextNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
...
// <annotation-config/>标签对应着AnnotationConfigBeanDefinitionParser
registerBeanDefinitionParser("annotation-config",
new AnnotationConfigBeanDefinitionParser());
...
}
}
public class AnnotationConfigBeanDefinitionParser
implements BeanDefinitionParser {
@Override
@Nullable
public BeanDefinition parse(Element element,
ParserContext parserContext) {
Object source = parserContext.extractSource(element);
// 调用的registerAnnotationConfigProcessors方法,这个方法将会返回
// 包含ConfigurationClassPostProcessor类的bean定义集合
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils
.registerAnnotationConfigProcessors(
parserContext.getRegistry(), source);
// 为周围的<context:annotation-config>元素注册组件
CompositeComponentDefinition compDefinition =
new CompositeComponentDefinition(element.getTagName(),
source);
parserContext.pushContainingComponent(compDefinition);
// 遍历从registerAnnotationConfigProcessors方法获得的bean定义
for (BeanDefinitionHolder processorDefinition :
processorDefinitions) {
// 通过调用这个方法最终会把bean定义添加到bean工厂中
parserContext.registerComponent(
new BeanComponentDefinition(processorDefinition));
}
// 最后注册复合组件,略过
parserContext.popAndRegisterContainingComponent();
return null;
}
}1.2 Springboot添加方式
看过Springboot源码流程的便可以知道,如果需要创建的ApplicationContext是SERVLET类型,那么创建的ApplicationContext将是AnnotationConfigServletWebServerApplicationContext类型,这个类在初始化时将会调用AnnotationConfigUtils.registerAnnotationConfigProcessors()方法注册需要的ConfigurationClassPostProcessor类。大致流程如下:
public class AnnotationConfigServletWebServerApplicationContext
extends ServletWebServerApplicationContext
implements AnnotationConfigRegistry {
// 读取注解bean定义和扫描bean定义的两个对象
private final AnnotatedBeanDefinitionReader reader;
private final ClassPathBeanDefinitionScanner scanner;
public AnnotationConfigServletWebServerApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
}
public class AnnotatedBeanDefinitionReader {
// bean注册中心
private final BeanDefinitionRegistry registry;
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry) {
this(registry, getOrCreateEnvironment(registry));
}
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry,
Environment environment) {
this.registry = registry;
this.conditionEvaluator =
new ConditionEvaluator(registry, environment, null);
// 传入注册中心,将ConfigurationClassPostProcessor类注册到Spring工厂中
AnnotationConfigUtils.registerAnnotationConfigProcessors(
this.registry);
}
}接下来我们正式开始流程图的流程分析。
2.Spring调用BeanFactoryPostProcessor接口
直接看到refresh刷新流程中invokeBeanFactoryPostProcessors方法,其源码如下:
public abstract class AbstractApplicationContext
extends DefaultResourceLoader
implements ConfigurableApplicationContext {
// ApplicationContext中的BeanFactoryPostProcessor对象集合
private final List<BeanFactoryPostProcessor> beanFactoryPostProcessors=
new ArrayList<>();
protected void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory) {
// 这里面便是执行BeanFactoryPostProcessor方法的地方
PostProcessorRegistrationDelegate
.invokeBeanFactoryPostProcessors(
beanFactory, getBeanFactoryPostProcessors());
...
}
}
final class PostProcessorRegistrationDelegate {
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory,
List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// 这个方法我们可以分为两部分,一部分是实现了BeanDefinitionRegistry注册
// 中心接口差别的bean工厂处理类型,另一部分是实现了注册中心和没有实现注册
// 中心公共执行部分
// 记录已经执行过的BeanFactoryPostProcessor对象
Set<String> processedBeans = new HashSet<>();
// 需要注意的是BeanDefinitionRegistryPostProcessor接口的参数是Spring的
// 注册中心,因此只有当前的bean工厂是BeanDefinitionRegistry注册中心的
// 实现类之一才会处理BeanDefinitionRegistryPostProcessor接口,否则
// 直接处理BeanFactoryPostProcessor对象即可
// 第一部分判断处理实现注册中心和没有实现注册中心
if (beanFactory instanceof BeanDefinitionRegistry) {
// 转换为Spring注册中心
BeanDefinitionRegistry registry =
(BeanDefinitionRegistry) beanFactory;
// 为实现BeanDefinitionRegistryPostProcessor接口的常规
// BeanFactoryPostProcessor对象集合,实际上保存的是需要
// 调用BeanFactoryPostProcessor接口方法的对象
// 因为BeanDefinitionRegistryPostProcessor接口方法将会在
// 获取到bean对象时就被调用
List<BeanFactoryPostProcessor> regularPostProcessors =
new ArrayList<>();
// Spring工厂中BeanDefinitionRegistryPostProcessor接口实现类的集合
List<BeanDefinitionRegistryPostProcessor> registryProcessors =
new ArrayList<>();
// 先遍历判断传进来beanFactoryPostProcessors集合对象
for (BeanFactoryPostProcessor postProcessor :
beanFactoryPostProcessors) {
// 如果是BeanDefinitionRegistryPostProcessor的实现类则添加到
// registryProcessors集合中
if (postProcessor instanceof
BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
// 先调用传进来的beanFactoryPostProcessors集合对象方法
registryProcessor
.postProcessBeanDefinitionRegistry(registry);
// 再添加到registryProcessors集合中
registryProcessors.add(registryProcessor);
}
else {
// 否则添加到常规的BeanFactoryPostProcessor集合对象中
regularPostProcessors.add(postProcessor);
}
}
// 保存从Spring工厂中获取到的BeanDefinitionRegistryPostProcessor
// 实现类
List<BeanDefinitionRegistryPostProcessor>
currentRegistryProcessors = new ArrayList<>();
// 从工厂中获取所有BeanDefinitionRegistryPostProcessor的实现类
String[] postProcessorNames = beanFactory.getBeanNamesForType(
BeanDefinitionRegistryPostProcessor.class, true, false);
// 先处理实现了PriorityOrderer接口的实现类
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory
.getBean(ppName,
BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
// 对集合进行排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 添加到registryProcessors集合中等下需要调用其属于
// BeanFactoryPostProcessor接口的方法
registryProcessors.addAll(currentRegistryProcessors);
// 调用BeanDefinitionRegistryPostProcessor接口的方法
invokeBeanDefinitionRegistryPostProcessors(
currentRegistryProcessors, registry);
// 清空
currentRegistryProcessors.clear();
// 接下来是处理未实现PriorityOrdered接口的实现类,和上面方法类似
// 只是少了PriorityOrdered接口类型的判断,因此次略过
...
// 最后循环调用在BeanDefinitionRegistryPostProcessor实现类中
// 被加入的实现类或者前面漏过的实现类,直到所有的实现类都被调用过
boolean reiterate = true;
while (reiterate) {
reiterate = false;
// 获取BeanDefinitionRegistryPostProcessor的实现类
postProcessorNames = beanFactory.getBeanNamesForType(
BeanDefinitionRegistryPostProcessor.class,
true, false);
// 继续刚刚的第二步,依次遍历获取到的实现类,流程类似,可略过
...
}
// 调用前面添加到registryProcessors和regularPostProcessors集合
// 中属于BeanFactoryPostProcessor接口的方法
invokeBeanFactoryPostProcessors(registryProcessors,
beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors,
beanFactory);
} else {
// 如果bean工厂不是注册中心的实现类则直接调用传进来集合中的
// 对象BeanFactoryPostProcessor接口方法
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors,
beanFactory);
}
// 第一部分:刚刚执行的是传进来的BeanFactoryPostProcessor集合和注册中心
// 中BeanDefinitionRegistryPostProcessor接口的实现类,第二部分
// 要处理的便是唯一实现了BeanFactoryPostProcessor接口而没有实现
// BeanDefinitionRegistryPostProcessor接口的公共处理部分
// 获取bean工厂中所有的BeanFactoryPostProcessor对象
String[] postProcessorNames = beanFactory.getBeanNamesForType(
BeanFactoryPostProcessor.class, true, false);
// 这个对象将会保存实现了PriorityOrdered接口的对象
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors =
new ArrayList<>();
// 保存实现了Ordered接口的对象
List<String> orderedPostProcessorNames = new ArrayList<>();
// 保存没有实现上述两个接口任一接口的对象
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// 如果执行过则直接跳过这个bean对象
}
else if (beanFactory.isTypeMatch(ppName,PriorityOrdered.class)){
// 添加实现了PriorityOrdered集合对象
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName,
BeanFactoryPostProcessor.class));
} else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
// 添加实现了Ordered集合对象
orderedPostProcessorNames.add(ppName);
} else {
// 添加没有实现上述两个接口任一接口的对象
nonOrderedPostProcessorNames.add(ppName);
}
}
// 由上面循环中的if判断可以知道,PriorityOrdered接口的优先级大于Ordered
// 且后续的流程也是这样的,先调用PriorityOrdered接口的对象,在调用实现
// Ordered接口的对象
// 一、排序并调用PriorityOrdered接口对象
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors,
beanFactory);
// 二、和PriorityOrdered差不多,只是多了从Spring工厂获取bean对象的环节
List<BeanFactoryPostProcessor> orderedPostProcessors =
new ArrayList<>();
// 遍历获取到的Ordered接口实现类对象,因为前面Ordered类型没有调用
// Spring工厂获取bean对象
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName,
BeanFactoryPostProcessor.class));
}
// 排序并调用BeanFactoryPostProcessor接口的方法
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors,beanFactory);
// 三、调用没有实现PriorityOrdered和Ordered接口的对象,方法流程和二
// 类似,因此略过
...
// 清除缓存的合并bean定义,因为后处理程序可能有修改原始元数据
// 例如替换值中的占位符
beanFactory.clearMetadataCache();
}
}方法流程较长,但只要分清了实现BeanDefinitionRegistry注册中心和没有实现注册中心的bean工厂类型就可以得知其实两部分的流程差不多。
3.ConfigurationClassPostProcessor类的执行流程
从上面小节部分我们已经知道了是如何调用BeanFactoryPostProcessor实现类的流程,现在直接看到处理@Configuration入口的实现类。加下来的流程比较长,建议先看流程图了解大概之后再来看源码流程,其部分源码如下:
public class ConfigurationClassPostProcessor
implements BeanDefinitionRegistryPostProcessor, PriorityOrdered,
ResourceLoaderAware, BeanClassLoaderAware, EnvironmentAware {
// 将会在BeanDefinitionRegistryPostProcessor实现类的对应方法中记录执行
// 过的注册中心唯一标示ID,这里记录的是注册中心的唯一ID
private final Set<Integer> registriesPostProcessed = new HashSet<>();
// 将会在BeanFactoryPostProcessor实现类的对应方法中记录执行过的注册中心
// 唯一标示ID,这里记录的是bean工厂的唯一ID
private final Set<Integer> factoriesPostProcessed = new HashSet<>();
@Override
public void postProcessBeanDefinitionRegistry(
BeanDefinitionRegistry registry) {
// 从上一小节的流程我们可以得知,这个接口将会比BeanFactoryPostProcessor
// 接口的方法postProcessBeanFactory执行的要早
// 获取当前注册中心在系统中唯一的hashCode值
int registryId = System.identityHashCode(registry);
// 如果这个注册中心早已经调用过该方法则抛出异常
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException();
}
// 如果针对bean工厂的唯一ID和注册中心的唯一ID一致(代表是同一个对象)
// 则说明这个工厂将要执行第二次,抛出异常
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException();
}
// 将注册中心的唯一ID放入registriesPostProcessed集合中
this.registriesPostProcessed.add(registryId);
// 这个方法便是具体执行分析候选者的地方
processConfigBeanDefinitions(registry);
}
@Override
public void postProcessBeanFactory(
ConfigurableListableBeanFactory beanFactory) {
// 这个方法将会在postProcessBeanDefinitionRegistry方法后面执行
// 生成bean工厂的唯一ID,在前面的方法生成的registryId将和这个一致
// 因为是同一个对象
int factoryId = System.identityHashCode(beanFactory);
// 判断bean工厂集合中不存在,言外之意便是没有第二次调用进
// postProcessBeanFactory方法
if (this.factoriesPostProcessed.contains(factoryId)) {
throw new IllegalStateException();
}
// 将factoryId添加到factoriesPostProcessed集合中,缓存防止第二次调用
this.factoriesPostProcessed.add(factoryId);
// 如果前面的postProcessBeanDefinitionRegistry执行过,且是第一次执行
// 那么processConfigBeanDefinitions方法一定会被执行过,且registryId
// 将会被放入registriesPostProcessed集合中缓存起来,因此这里如果判断
// 成立则说明processConfigBeanDefinitions方法执行过,无需再次执行
if (!this.registriesPostProcessed.contains(factoryId)) {
processConfigBeanDefinitions(
(BeanDefinitionRegistry) beanFactory);
}
// 使用CGLIB封装被@Configuration注解的类,这里面大致逻辑便是遍历Spring
// 工厂中所有的bean,然后再为@Configuration配置类添加CGLIB的beanClass
enhanceConfigurationClasses(beanFactory);
// 手动添加一个BeanPostProcessor,这个是用来处理实现ImportAware接口的
beanFactory.addBeanPostProcessor(
new ImportAwareBeanPostProcessor(beanFactory));
}
public void processConfigBeanDefinitions(
BeanDefinitionRegistry registry) {
// 方法较长,因此取一些关键的点来看,一些不怎么重要的便做个大致说明略过
// 可以大致将其分为三个关键部分
// 一、从所有bean中获取有资格的bean
// 保存所有bean中被@Configuration注解的类
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
// 获取所有的beanName
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) ||
ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
// 进入到这里说明bean已经处理过,直接跳过
}
else if (ConfigurationClassUtils
.checkConfigurationClassCandidate(beanDef,
this.metadataReaderFactory)) {
// checkConfigurationClassCandidate方法实际上判断的条件
// 是是否被@Configuration或@Bean所注解,如果被@Configuration
// 注解了则configurationClass属性是full,如果没有@Configuration
// 只有@Bean注解,则configurationClass属性是lite,但是都会当成
// 候选者进行后续操作
configCandidates.add(new BeanDefinitionHolder(beanDef,
beanName));
}
}
// 如果候选者集合为空则直接返回
if (configCandidates.isEmpty()) {
return;
}
// 二、对获取到的候选者集合进行排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(
bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(
bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// 这里还会有一步设置BeanNameGenerator对象,但是可以忽略
...
// 三、开始第三步解析@Configuration注解的配置类
// 先将bean工厂、加载器和beanName生成器等实例化实际解析的对象
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter,
this.environment, this.resourceLoader,
this.componentScanBeanNameGenerator, registry);
// 使用前面解析获得的候选者集合在生成新的待解析集合对象
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(
configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(
configCandidates.size());
do {
// 调用解析器的解析方法开始解析
parser.parse(candidates);
// 解析之后验证,一般作用为验证@Configuration注解
parser.validate();
// 从解析其中获取已经解析完的配置类集合
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(
parser.getConfigurationClasses());
// 去除已经解析过的候选者对象
configClasses.removeAll(alreadyParsed);
// 前面已经使用解析器获取到了解析过后的配置类,但是并没有将其注册到
// Spring工厂管理起来,因此这里使用BeanDefinitionReader来读取和
// 注册配置类及其bean对象
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader,
this.environment, this.importBeanNameGenerator,
parser.getImportRegistry());
}
// 读取并将涉及到的bean配置类注册到注册中心
this.reader.loadBeanDefinitions(configClasses);
// 将配置类对象添加到已经解析过的集合中,这个集合是不会清空的
alreadyParsed.addAll(configClasses);
// 将已经解析过的对象从集合中删除,以方便后续添加其它的配置类对象
candidates.clear();
// 判断注册中心的bean定义数量是否大于候选者集合数量,如果bean定义
// 数量大于则重新获取一遍候选者,且过滤掉已经解析过的候选者,随后
// 将重新获取到的候选者再次解析加载一次
// 或许看到这里会很困惑为什么这里需要再判断一次,但是只是要深入了解
// 了Parser和Reader这两个对象执行的流程操作就能理解为什么这里还要
// 加一层判断了,其原因是在前面的Reader对象调用loadBeanDefinition
// 方法时会在注册中心中再注册额外的bean定义,且是没有解析过的,因此
// 可能会遗漏一些@Configuration配置类,因此这里需要再获取一次,防止
// 新引入的配置类对象发生遗漏,接下来看其操作,和前面的流程很像
if (registry.getBeanDefinitionCount() > candidateNames.length){
// 获得注册中心所有的bean定义对象
String[] newCandidateNames = registry
.getBeanDefinitionNames();
// 将原来的候选者集合全部放入oldCandidateNames集合中,以判断
// 新的候选者哪些已经解析过了
Set<String> oldCandidateNames = new HashSet<>(
Arrays.asList(candidateNames));
// 等下用来存储已经解析过的配置类
Set<String> alreadyParsedClasses = new HashSet<>();
// 遍历已经解析过配置类集合,并将类对象放入刚声明的集合中
for (ConfigurationClass configurationClass : alreadyParsed){
alreadyParsedClasses.add(configurationClass.getMetadata()
.getClassName());
}
// 遍历新的需要解析的集合
for (String candidateName : newCandidateNames) {
// 已经解析过的集合不包含这个配置类,防止重复解析加载
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry
.getBeanDefinition(candidateName);
// 判断需要是@Configuration且再次判断有没有被解析过
// 使用两步判重是因为原来就分了两个集合,一个是存储将要
// 解析的集合,一个是存储已经解析过的集合
if (ConfigurationClassUtils
.checkConfigurationClassCandidate(bd,
this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd
.getBeanClassName())) {
// 放入将要解析的候选者集合中
candidates.add(
new BeanDefinitionHolder(bd, candidateName));
}
}
}
// 将注册中心新的候选者集合赋值给candidateNames,以便再次循环
// 遍历使用
candidateNames = newCandidateNames;
}
// 如果candidates需要解析的集合不为空则继续循环遍历解析读取
} while (!candidates.isEmpty());
// 后面是注册内部类importRegistry,可以略过
...
}
}在该类的processConfigBeanDefinitions方法中有一个循环遍历处理,可能第一眼看起来让人很懵,但是只要捋清楚其作用思路便清晰了。其流程图如下:
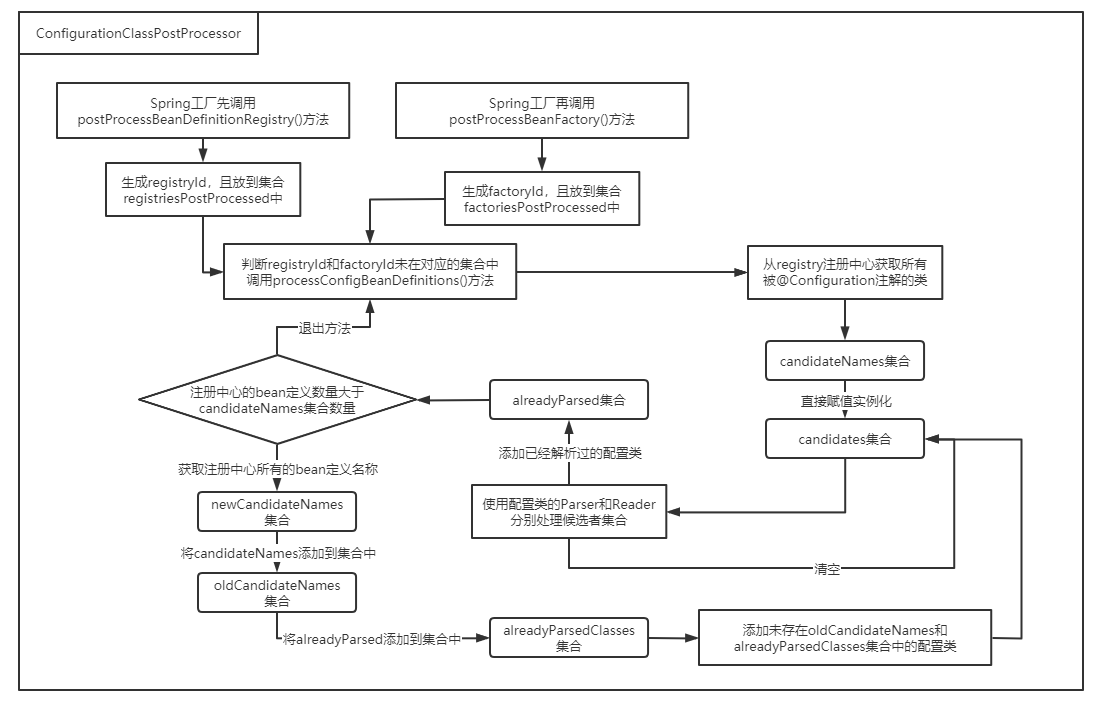
本篇对于@Configuration的BeanFactoryPostProcessor分析便到此结束。这是上篇,下篇对于获取到的@Configuration如何解析以及读取注册会有更详细的分析,有兴趣可跳至(三)Spring框架原理之@Configuration及搭配注解接口源码分析(下)文章。














 6944
6944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









