






实时流式计算
概念
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。 直梯 扶梯

流式计算就相当于上图的右侧扶梯,是可以源源不断的产生数据,源源不断的接收数据,没有边界。
应用场景
-
日志分析
网站的用户访问日志进行实时的分析,计算访问量,用户画像,留存率等等,实时的进行数据分析,帮助企业进行决策
-
大屏看板统计
可以实时的查看网站注册数量,订单数量,购买数量,金额等。
-
公交实时数据
可以随时更新公交车方位,计算多久到达站牌等
-
实时文章分值计算
头条类文章的分值计算,通过用户的行为实时文章的分值,分值越高就越被推荐。
技术方案选型
-
Hadoop

-
Apache Storm
Storm 是一个分布式实时大数据处理系统,可以帮助我们方便地处理海量数据,具有高可靠、高容错、高扩展的特点。是流式框架,有很高的数据吞吐能力。
-
Kafka Stream
可以轻松地将其嵌入任何Java应用程序中,并与用户为其流应用程序所拥有的任何现有打包,部署和操作工具集成。
Kafka Stream
概述
Kafka Stream是Apache Kafka从0.10版本引入的一个新特性。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点如下:
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
Kafka Streams的关键概念
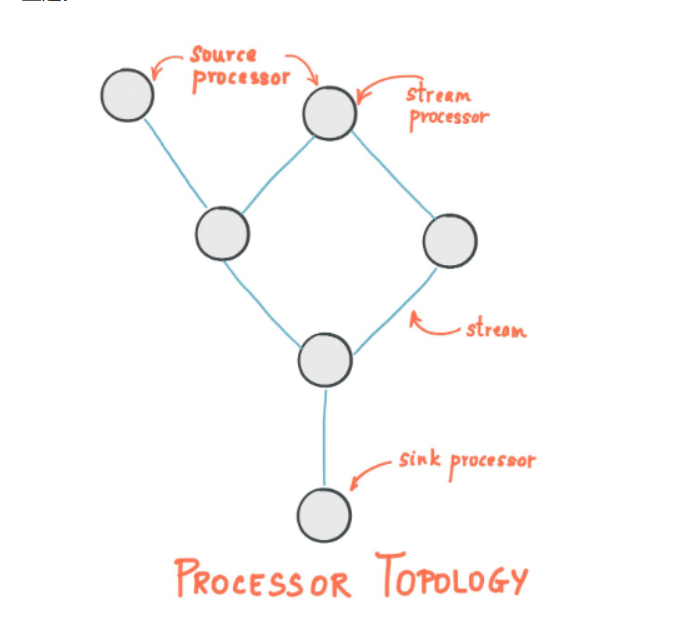
(1)Stream处理拓扑
- 流是Kafka Stream提出的最重要的抽象概念:它表示一个无限的,不断更新的数据集。流是一个有序的,可重放(反复的使用),不可变的容错序列,数据记录的格式是键值对(key-value)。
- 通过Kafka Streams编写一个或多个的计算逻辑的处理器拓扑。其中处理器拓扑是一个由流(边缘)连接的流处理(节点)的图。
- 流处理器是
处理器拓扑中的一个节点;它表示一个处理的步骤,用来转换流中的数据(从拓扑中的上游处理器一次接受一个输入消息,并且随后产生一个或多个输出消息到其下游处理器中)。
(2)在拓扑中有两个特别的处理器:
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
- Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
KStream&KTable
(1)数据结构类似于map,key-value键值对
(2)KStream
KStream数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。
数据流中比较常记录的是事件,这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。
KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。
为了说明这一点,让我们想象一下以下两个数据记录正在发送到流中:
(“ alice”,1)->( alice“,3)
如果您的流处理应用是要总结每个用户的价值,它将返回( alice“,4)。为什么?因为第二条数据记录将不被视为先前记录的更新。(insert)新数据
(3)KTable
KTable传统数据库,包含了各种存储了大量状态(state)的表格。KTable负责抽象的,就是表状数据。每一次操作,都是更新插入(update)
为了说明这一点,让我们想象一下以下两个数据记录正在发送到流中:
(“ alice”,1)->( alice“,3)
如果您的流处理应用是要总结每个用户的价值,它将返回(“ alice“,3)。为什么?因为第二条数据记录将被视为先前记录的更新。
KStream - 每个新数据都包含了部分信息。
KTable - 每次更新都合并到原记录上。
Kafka Stream入门案例编写
API参考:http://kafka.apache.org/documentation/streams/
(1)引入依赖
在之前的kafka-demo工程的pom文件中引入
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
(2)创建类
package com.heima.kafka.streams;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.*;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
// 指定一个应用的id
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
// kafka的地址
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.85.143:9092");
// key的序列化
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// value的序列化
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
// 读取指定topic中的数据
KStream<String, String> textLines = builder.stream("TextLinesTopic");
//(k,v)–>(k,v1),(k,v2)
// 原数据:key:"10010" value:"tom jerry jack tom tom jack"
// topic中的数据转成数组
KStream<String, String> stringKStream = textLines.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) { //value 就是原数据
return Arrays.asList(value.split(" "));
}
});
// stringKStream:
// 10010 tom
// 10010 jerry
// 10010 jack
// 10010 tom
// 10010 tom
// 10010 jack
// 根据value分组 三个参数:p1:key p2:value p3:用来分组的属性
KGroupedStream<String, String> groupedStream = stringKStream.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String value) {
return value; //根据value分组
}
});
// groupedStream:
// 10010 tom
// 10010 tom
// 10010 tom
// 10010 jerry
// 10010 jack
// 10010 jack
// 数量的统计
KTable<String, Long> kTable = groupedStream.count(Materialized.with(Serdes.String(), Serdes.Long()));
// kTable
// tom:3
// jerry:1
// jack:2
// 把上面的结果转成另一个map 把原数据中的value由Long转成String
KStream<String, String> kStream = kTable.toStream().map(new KeyValueMapper<String, Long, KeyValue<String, String>>() {
@Override
public KeyValue<String, String> apply(String key, Long value) {
return new KeyValue<>(key, value.toString());
}
});
kStream.to("WordsWithCountsTopic");
// KTable<String, Long> wordCounts = textLines
// .flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
// .groupBy((key, word) -> word)
// .count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
// wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
方法简介:
1、flatMapValues的效果:(k,v)–>(k,v1),(k,v2)
2、GroupByKey:根据key进行分组
3、GroupBy:根据自定义的信息进行分组
4、map | mapValues 将一条record映射为另外一条record
5、 Count方法 :统计key相同的record出现的次数
6、windowed窗口操作:根据时间维度统计 每隔一段时间统计 统计是这段时间内的数据
测试
可以直接使用第6天写的入门案例向topic中放数据
package com.heima.kafka.produce;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class ProducerTest {
public static void main(String[] args) {
// 设置属性
Properties props = new Properties();
// 指定连接的kafka服务器的地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.85.143:9092");
props.put(ProducerConfig.ACKS_CONFIG,"all");
// 构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props, new StringSerializer(), new StringSerializer());
// 定义kafka主题
String topic = "TextLinesTopic";
// 调用生产者发送消息
String message = "tom jerry jack tom tom jack";
// 构建消息
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, message);
// 同时发送key和value
record = new ProducerRecord<String, String>(topic, "10010", message);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception!=null){
// 没有发送成功
exception.printStackTrace();
}
System.out.println(metadata.offset());
}
});
// 释放连接
producer.close();
}
}
(3)按时间区间统计
统计某一段时间内单词出现的次数
大致步骤是:
1、topic中的数据转成数组
2、 根据value分组
3、 设置时间间隔
4、数量的统计
5、把原数据中的value由Long转成String
package com.heima.kafka.streams;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication2 {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
// 指定一个应用的id
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
// kafka的地址
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.85.143:9092");
// key的序列化
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// value的序列化
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
// 读取指定topic中的数据
KStream<String, String> textLines = builder.stream("TextLinesTopic");
//(k,v)–>(k,v1),(k,v2)
// 原数据:key:"10010" value:"tom jerry jack tom tom jack"
// topic中的数据转成数组
KStream<String, String> stringKStream = textLines.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) { //value 就是原数据
return Arrays.asList(value.split(" "));
}
});
// stringKStream:
// 10010 tom
// 10010 jerry
// 10010 jack
// 10010 tom
// 10010 tom
// 10010 jack
// 根据value分组 三个参数:p1:key p2:value p3:用来分组的属性
KGroupedStream<String, String> groupedStream = stringKStream.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String value) {
return value; //根据value分组
}
});
// 设置时间间隔 这里是60秒
TimeWindowedKStream<String, String> windowedKStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofSeconds(60)));
// groupedStream:
// 10010 tom
// 10010 tom
// 10010 tom
// 10010 jerry
// 10010 jack
// 10010 jack
// 数量的统计
// KTable<String, Long> kTable = groupedStream.count(Materialized.with(Serdes.String(), Serdes.Long()));
KTable<Windowed<String>, Long> kTable = windowedKStream.count(Materialized.with(Serdes.String(), Serdes.Long()));
// kTable
// tom:3
// jerry:1
// jack:2
// 把上面的结果转成另一个map 把原数据中的value由Long转成String
KStream<String, String> kStream = kTable.toStream().map(new KeyValueMapper<Windowed<String>, Long, KeyValue<String, String>>() {
@Override
public KeyValue<String, String> apply(Windowed<String> key, Long value) {
return new KeyValue<>(key.key(), value.toString());
}
});
kStream.to("WordsWithCountsTopic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
SpringCloudStream
使用SpringCloudStream可以方便集成Kafka Stream
新建项目spring-cloud-kafka-stream-demo
https://docs.spring.io/spring-cloud-stream-binder-kafka/docs/3.0.10.RELEASE/reference/html/spring-cloud-stream-binder-kafka.html#_programming_model
使用步骤如下:
(1) 添加依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR6</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
(2) 添加配置
spring:
cloud:
stream:
kafka:
streams:
binder:
application-id: app_1
brokers: 192.168.85.143:9092
configuration:
commit.interval.ms: 1000
default:
key.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
value.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
(3) 添加监听器
处理器接口
package com.heima.stream.listener;
import org.apache.kafka.streams.kstream.KStream;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
public interface WordCountProcessor {
@Input("WordCountSource")
KStream<String, String> input();
@Output("WordCountResult")
KStream<String, String> output();
}
监听器
package com.heima.kafkastream.wordscount;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.kstream.*;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.binder.kafka.streams.annotations.KafkaStreamsProcessor;
import org.springframework.messaging.handler.annotation.SendTo;
import java.time.Duration;
import java.util.Arrays;
@EnableBinding(WordCountProcessor.class)
public class WordCountProcessorApplication {
@StreamListener("WordCountSource")
@SendTo("WordCountResult")
public KStream<String, String> process(KStream<String, String> input) {
// return input
// .flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// .groupBy((key, value) -> value)
// .windowedBy(TimeWindows.of(5000))
// .count(Materialized.as("WordCounts-multi"))
// .toStream()
// .map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
// 最原始的数据 "10010":"tom jerry jack tom jerry tom"
KStream<String, String> stringKStream = input.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
String[] strings = value.split(" ");
return Arrays.asList(strings);
}
});
KGroupedStream<String, String> groupedStream = stringKStream.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String value) {
return value;
}
});
TimeWindowedKStream<String, String> windowedKStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofSeconds(60)));
KTable<Windowed<String>, Long> countKTable = windowedKStream.count();
KStream<String, String> kStream = countKTable.toStream().map(new KeyValueMapper<Windowed<String>, Long, KeyValue<String, String>>() {
@Override
public KeyValue<String, String> apply(Windowed<String> key, Long value) {
return new KeyValue<>(key.key(), value.toString());
}
});
return kStream;
}
}
lamda:
package com.heima.kafka.listener;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.kstream.*;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.binder.kafka.streams.annotations.KafkaStreamsProcessor;
import org.springframework.messaging.handler.annotation.SendTo;
import java.time.Duration;
import java.util.Arrays;
@EnableBinding(WordProcess.class)
public class WordCountListener {
@StreamListener("WordCountSource")
@SendTo("WordCountResult")
public KStream<String, String> process(KStream<String, String> input) {
return input.flatMapValues((ValueMapper<String, Iterable<String>>) value -> { //value 就是原数据
return Arrays.asList(value.split(" "));
}).groupBy((key, value) -> {
return value; //根据value分组
}).windowedBy(TimeWindows.of(Duration.ofSeconds(60)))
.count(Materialized.with(Serdes.String(), Serdes.Long()))
.mapValues(value -> value.toString()).toStream().map( (key, value) -> new KeyValue<>(key.key(), value));
}
}
引导类:
package com.heima.stream;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class StreamApp {
public static void main(String[] args) {
SpringApplication.run(StreamApp.class,args);
}
}

实时热点文章计算
需求分析
- 根据用户的行为(阅读、点赞、评论、收藏)实时计算热点文章
思路分析
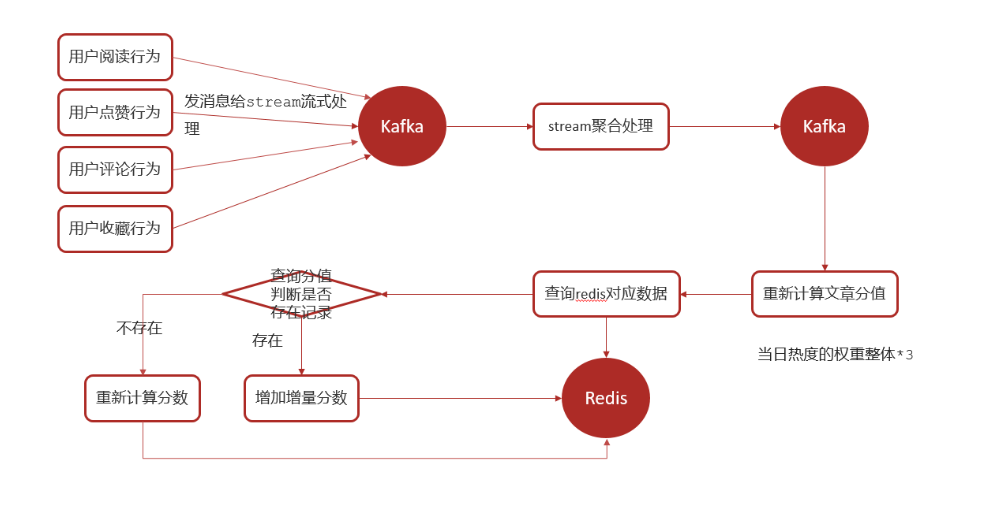
- 实时计算热点文章
- 行为微服务,用户阅读或点赞了某一篇文章,发送消息给kafka
- 文章微服务,接收行为消息,使用kafkastream流式处理进行聚合,发消息给kafka
- 文章微服务,接收聚合之后的消息,计算文章分值(当日分值计算方式,在原有权重的基础上再*3)
- 新数据重新设置到缓存中
功能实现
用户行为发送消息
①在leadnews-behavior微服务中集成kafka生产者配置
修改application.yml (大家注意,第6天添加的是消费者的配置,现在是生产者的配置)
spring:
application:
name: leadnews-behavior
kafka:
bootstrap-servers: 192.168.85.143:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
② 定义消息发送封装类:UpdateArticleMessage
import lombok.Data;
@Data
public class UpdateArticleMessage {
/**
* 操作类型 0 阅读 1 点赞 2 评论 3 收藏
*/
private Integer type;
/**
* 文章ID
*/
private Long articleId;
/**
* 修改数据的增量,可为正负 1或者-1
*/
private Integer add;
}
保存点赞时发送消息
(如果你做了点赞的功能,添加以下代码,如果没有做点赞的功能就直接使用junit测试去模拟数据)
package com.heima.article.test;
import com.alibaba.fastjson.JSON;
import com.heima.article.dto.UpdateArticleMessage;
import org.apache.commons.lang3.RandomUtils;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaTemplate;
@SpringBootTest
public class SendArticleBehaviorTest {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
@Test
public void testSend(){
for (int i = 0; i < 5; i++) {
UpdateArticleMessage articleMessage = new UpdateArticleMessage();
articleMessage.setType(RandomUtils.nextInt(0,4)); // 0 阅读 1 点赞 2 评论 3 收藏
articleMessage.setArticleId(1463531645259747329L);
articleMessage.setAdd(1);
kafkaTemplate.send("hot_article_score_topic", JSON.toJSONString(articleMessage));
}
for (int i = 0; i < 10; i++) {
UpdateArticleMessage articleMessage = new UpdateArticleMessage();
articleMessage.setType(RandomUtils.nextInt(0,4)); // 0 阅读 1 点赞 2 评论 3 收藏
articleMessage.setArticleId(1468428215671345154L);
articleMessage.setAdd(1);
kafkaTemplate.send("hot_article_score_topic", JSON.toJSONString(articleMessage));
}
}
}
实时消息聚合
①在leadnews-article微服务中集成kafkaStream
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>
application.yml中新增自定义配置
spring:
cloud:
stream:
kafka:
streams:
binder:
application-id: ${spring.application.name}-kafka-stream-id
brokers: 192.168.85.143:9092
configuration:
commit.interval.ms: 5000
default:
key.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
value.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
②定义实体类,用于聚合之后的操作封装
具体的数据变化如下:
最原本的数据
{"add":1,"articleId":1456141911827836930,"type":0}
{"add":1,"articleId":1456088799662469121,"type":2}
{"add":1,"articleId":1456088799662469121,"type":1}
{"add":1,"articleId":1456088799662469121,"type":0}
{"add":1,"articleId":1456141911827836930,"type":3}
{"add":1,"articleId":1456088799662469121,"type":3}
{"add":1,"articleId":1456141911827836930,"type":0}
{"add":1,"articleId":1456088799662469121,"type":3}
给每个数据设置一个key 可以就是每个数据的文章id
1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":2}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":1}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":0}
1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":3}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
根据key分组
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":2}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":1}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":0}
1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":3}
1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
根据type计算分值 操作类型 0 阅读 1 点赞 2 评论 3 收藏
需要通过聚合计算
1456088799662469121 {articleId:"1456088799662469121",view:1 , like:1, comment:1 , collect:2 }
1456141911827836930 {articleId:"1456141911827836930",view:2 , like:0, comment:0 , collect:1 }
把以上的结果放到一个新的topic中
package com.heima.article.dto;
import lombok.Data;
@Data
public class ArticleStreamMessage {
/**
* 文章id
*/
private Long articleId;
/**
* 阅读
*/
private long view;
/**
* 收藏
*/
private long collect;
/**
* 评论
*/
private long comment;
/**
* 点赞
*/
private long like;
}
从behavior中拷贝UpdateArticleMessage到article微服务的dto包下
③ 定义stream,接收消息并聚合
package com.heima.article.listener;
import org.apache.kafka.streams.kstream.KStream;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
public interface IHotArticleProcessor {
@Input("hot_article_score_topic")
KStream<String, String> input();
@Output("hot_article_result_topic")
KStream<String, String> output();
}
流式监听器
(阅读:1,点赞:3,评论:5,收藏:8)
package com.heima.article.listener;
import com.alibaba.fastjson.JSON;
import com.heima.article.dto.ArticleStreamMessage;
import com.heima.article.dto.UpdateArticleMessage;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.kstream.*;
import org.checkerframework.checker.units.qual.K;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.binder.kafka.streams.annotations.KafkaStreamsProcessor;
import org.springframework.messaging.handler.annotation.SendTo;
import java.time.Duration;
@EnableBinding(IHotArticleProcessor.class)
public class HotArticleListener {
@StreamListener("hot_article_score_topic")
@SendTo("hot_article_result_topic")
public KStream<String, String> process(KStream<String, String> input) {
// topic最原本的数据
// {"add":1,"articleId":1456141911827836930,"type":0}
// {"add":1,"articleId":1456088799662469121,"type":2}
// {"add":1,"articleId":1456088799662469121,"type":1}
// {"add":1,"articleId":1456088799662469121,"type":0}
// {"add":1,"articleId":1456141911827836930,"type":3}
// {"add":1,"articleId":1456088799662469121,"type":3}
// {"add":1,"articleId":1456141911827836930,"type":0}
// {"add":1,"articleId":1456088799662469121,"type":3}
KStream<String, String> map = input.map(new KeyValueMapper<String, String, KeyValue<String, String>>() {
@Override
public KeyValue<String, String> apply(String key, String value) {
UpdateArticleMessage updateArticleMessage = JSON.parseObject(value, UpdateArticleMessage.class);
Long articleId = updateArticleMessage.getArticleId();
return new KeyValue<>(articleId.toString(), value);
}
});
// 现在的数据:
// 1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":2}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":1}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":0}
// 1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":3}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
// 1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
KGroupedStream<String, String> groupedStream = map.groupByKey();//根据可以分组
// 现在的数据:
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":2}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":1}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":3}
// 1456088799662469121 {"add":1,"articleId":1456088799662469121,"type":0}
//
// 1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
// 1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":3}
// 1456141911827836930 {"add":1,"articleId":1456141911827836930,"type":0}
TimeWindowedKStream<String, String> windowedKStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofSeconds(60))); //每60秒统计一次
// 聚合之前的初始化器 内容为空
Initializer<String> initializer = new Initializer<String>() {
@Override
public String apply() {
return null;
}
};
// 开始聚合
Aggregator<String,String, String> aggregator = new Aggregator<String, String, String>() {
@Override //key:文章id value:UpdateArticleMessage{"add":1,"articleId":1456088799662469121,"type":2} aggregate聚合后的结果 {articleId:"1456088799662469121",view:1 , like:1, comment:1 , collect:2 }
public String apply(String key, String value, String aggregate) {
ArticleStreamMessage articleStreamMessage = null;
if(aggregate==null){
articleStreamMessage = new ArticleStreamMessage();
articleStreamMessage.setArticleId(Long.parseLong(key));
articleStreamMessage.setView(0);
articleStreamMessage.setLike(0);
articleStreamMessage.setComment(0);
articleStreamMessage.setCollect(0);
}else{
articleStreamMessage = JSON.parseObject(aggregate,ArticleStreamMessage.class);
}
UpdateArticleMessage updateArticleMessage = JSON.parseObject(value, UpdateArticleMessage.class);
Integer type = updateArticleMessage.getType();
switch (type){
case 0: //阅读
articleStreamMessage.setView(articleStreamMessage.getView()+updateArticleMessage.getAdd());
break;
case 1: //点赞
articleStreamMessage.setLike(articleStreamMessage.getLike()+updateArticleMessage.getAdd());
break;
case 2: //评论
articleStreamMessage.setComment(articleStreamMessage.getComment()+updateArticleMessage.getAdd());
break;
case 3: //收藏
articleStreamMessage.setCollect(articleStreamMessage.getCollect()+updateArticleMessage.getAdd());
break;
}
return JSON.toJSONString(articleStreamMessage);
}
};
KTable<Windowed<String>, String> kTable = windowedKStream.aggregate(initializer, aggregator);
// 聚合后的结果:
// 1456088799662469121 {articleId:"1456088799662469121",view:1 , like:1, comment:1 , collect:2 }
// 1456141911827836930 {articleId:"1456141911827836930",view:2 , like:0, comment:0 , collect:1 }
// 把每10秒聚合后的结果放到新的topic中
KStream<String, String> stream = kTable.toStream().map(new KeyValueMapper<Windowed<String>, String, KeyValue<String, String>>() {
@Override
public KeyValue<String, String> apply(Windowed<String> key, String value) {
return new KeyValue<>(key.key(), value);
}
});
return stream;
}
}
聚合消息结果处理
定义监听,接收聚合之后的数据,文章的分值重新进行计算
package com.heima.article.listener;
import com.alibaba.fastjson.JSON;
import com.heima.article.dto.ArticleStreamMessage;
import com.heima.article.service.IApArticleService;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class HotArticleResultListener {
@Autowired
private IApArticleService articleService;
@KafkaListener(topics = "hot_article_result_topic")
public void handleMessage(ConsumerRecord<String, String> record) {
// 获取消息,转换称为结果对象 ArticleStreamMessage
System.out.println("接收到消息: " + record.value());
ArticleStreamMessage articleStreamMessage = JSON.parseObject(record.value(), ArticleStreamMessage.class);
articleService.updateHotArticle(articleStreamMessage);
}
}
重新计算文章的分值,更新到缓存中
在IApArticleService添加方法,用于更新缓存中的文章分值
/**
* 更新文章分值
* @param mess
*/
public void updateHotArticle(ArticleStreamMessage message);
实现类方法
@Override
public void updateHotArticle(ArticleStreamMessage message) {
// 1、重新计算文章的热度值(今天产生的数据*3)
Long articleId = message.getArticleId();
ApArticle article = this.getById(articleId);
int score = computeTodayScore(message);
ApArticle cache = new ApArticle();
cache.setId(article.getId());
cache.setTitle(article.getTitle());
cache.setImages(article.getImages());
cache.setAuthorId(article.getAuthorId());
cache.setAuthorName(article.getAuthorName());
cache.setLayout(article.getLayout());
cache.setStaticUrl(article.getStaticUrl());
// 2、更新redis中的数据
// String key = "hot_article_first_page_" + dto.getChannelId();
Double scoreBefore = redisTemplate.boundZSetOps("hot_article_first_page_0").score(JSON.toJSONString(cache));
if(scoreBefore!=null){
redisTemplate.boundZSetOps("hot_article_first_page_0").add(JSON.toJSONString(cache),scoreBefore+score);
redisTemplate.boundZSetOps("hot_article_first_page_"+article.getChannelId()).add(JSON.toJSONString(cache),scoreBefore+score);
}else{
redisTemplate.boundZSetOps("hot_article_first_page_0").add(JSON.toJSONString(cache),score);
redisTemplate.boundZSetOps("hot_article_first_page_"+article.getChannelId()).add(JSON.toJSONString(cache),score);
}
// 3、更新mysql中ApArticle中的阅读数、点赞数、评论数、收藏数
LambdaUpdateWrapper<ApArticle> updateWrapper = new LambdaUpdateWrapper<>();
updateWrapper.eq(ApArticle::getId,message.getArticleId());
updateWrapper.setSql("views=views+"+message.getView());
updateWrapper.setSql("likes=likes+"+message.getLike());
updateWrapper.setSql("comment=comment+"+message.getComment());
updateWrapper.setSql("collection=collection+"+message.getCollect());
this.update(updateWrapper);
}
/**
* 计算当日的增量分数 当日的操作整体权重*3
*
* @param message
* @return
*/
private int computeTodayScore(ArticleStreamMessage message) {
int score = 0;
score += message.getView() * 1 * 3;
score += message.getLike() * 3 * 3;
score += message.getComment() * 5 * 3;
score += message.getCollect() * 8 * 3;
return score;
}















 2696
2696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









