






经过差不多一个星期的折腾,当然这其中也有做很多其他事情。周四写出来直接通过浏览器Network找到观察者网评论链接进行的爬虫,今天下午有折腾了差不多一下午,终于通过BeautifulSoup解析出的html中找到了data-id,也就是构造评论链接的关键。
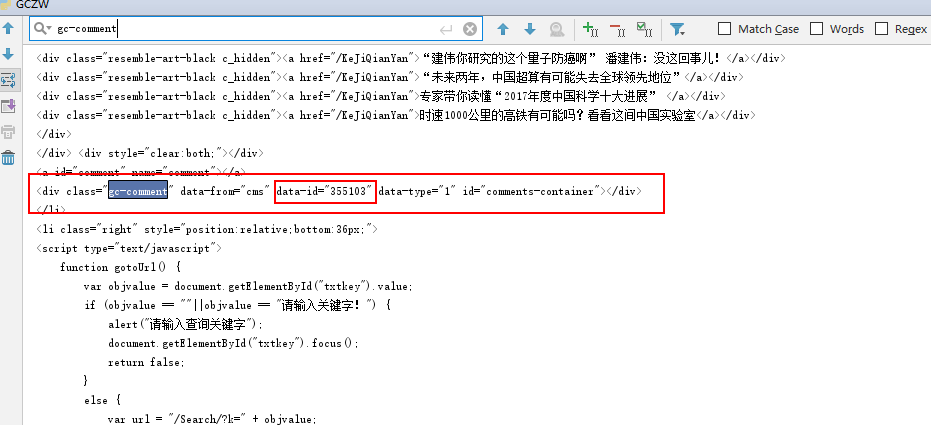
找到了data-id之后,这样就可以把每篇文章和其评论建立联系。这样接下来的通过文章链接,直接爬评论的想法就可以水到渠成了。
而下午的主要时间都花费在怎么data-id解析提取出来。尝试了很多方法,比如先找到 clas

 经过一周的学习与实践,作者成功编写了自己的第一个Python爬虫,用于抓取观察者网的文章评论。关键在于通过BeautifulSoup解析HTML,找出class为'gc-comment'的div标签中的"data-id"。在解决数据类型问题上遇到挑战,最终确定使用bs4的方法提取"data-id"属性。这次经历不仅是Python学习的里程碑,也暴露了基础知识的不足,为后续学习指明方向。
经过一周的学习与实践,作者成功编写了自己的第一个Python爬虫,用于抓取观察者网的文章评论。关键在于通过BeautifulSoup解析HTML,找出class为'gc-comment'的div标签中的"data-id"。在解决数据类型问题上遇到挑战,最终确定使用bs4的方法提取"data-id"属性。这次经历不仅是Python学习的里程碑,也暴露了基础知识的不足,为后续学习指明方向。
经过差不多一个星期的折腾,当然这其中也有做很多其他事情。周四写出来直接通过浏览器Network找到观察者网评论链接进行的爬虫,今天下午有折腾了差不多一下午,终于通过BeautifulSoup解析出的html中找到了data-id,也就是构造评论链接的关键。
找到了data-id之后,这样就可以把每篇文章和其评论建立联系。这样接下来的通过文章链接,直接爬评论的想法就可以水到渠成了。
而下午的主要时间都花费在怎么data-id解析提取出来。尝试了很多方法,比如先找到 clas

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















