






0 项目说明
基于在线民宿 UGC 数据的意见挖掘
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
1 研究目的
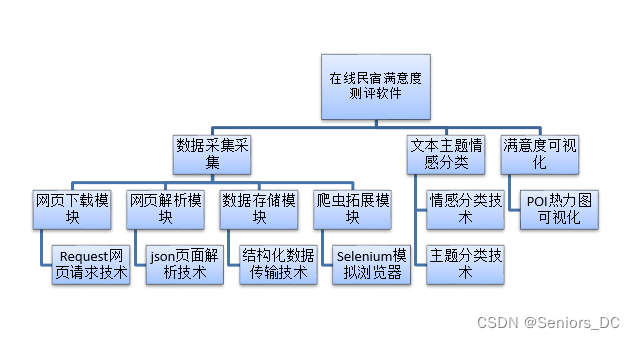
包含数据挖掘和NLP 相关的处理,负责数据采集、主题抽取、情感分析等任务。目的是克服用户打分和评论不一致,实时对在线民宿的满意度评测,主要功能包括在线原始评论采集、主题聚类、评论情感分析与结果可视化展示等四个模块。
2 研究方法
搭建了百度地图POI查询入口,可以进行自动化的批量查询 POI 信息的功能;构建了基于在线民宿语料的 LDA 自动主题聚类模型,利用主题中心词能找出对应的主题属性字典;以用户打分作为标注,然后 litNlp 自带的字符级 TextCNN 进行情感分析,将情感分类概率分布作为情感趋势,最后通过 POI 热力图的方式对不同地域的民宿满意度进行展示。
3 研究结论
基于用户 UGC 的在线民宿满意度挖掘,负责数据采集、主题抽取、情感分析等任务。开发的目的是克服用户打分和评论不一致,实现了在线评论采集和用户满意度分析。
4 项目源码
# -*- coding: utf-8 -*-
# @USER: CarryChang
from sklearn.feature_extraction.text import CountVectorizer
from gensim.corpora.dictionary import Dictionary
# 加载 LDA 模型库
from gensim.models.ldamodel import LdaModel
# 加载计算 LDA 模型的评估库
from gensim.models.coherencemodel import CoherenceModel
# 加载 LDA 主题模型
from sklearn.decomposition import LatentDirichletAllocation
import matplotlib.pyplot as plt
import jieba.posseg as pseg
from tqdm import tqdm
import numpy as np
from setting import *
# 分词器预热
list(pseg.cut('垃圾饭店'))
# 定义处理函数
def get_n_filter(sentence_list):
# 提取语料提取后的名词
n_filter_list = list()
for sentence_ in tqdm(sentence_list):
n_filter = list()
words = pseg.cut(sentence_)
for word, flag in words:
# 过滤长度大于 1 的名词
if 'n' in flag and len(word) > 1:
n_filter.append(word)
n_filter_list.append(n_filter)
return n_filter_list
def topic_number_search():
# 设初始的主题数 start_topic_number
start_topic_number = 1
# 设置最大的主题数 topic_numbers_max
topic_numbers_max = 10
# 收集模型分数
error_list = list()
# 定义主题数搜索列表,每次计算差距 2 个 topic
topics_list = list(range(start_topic_number, topic_numbers_max + 1, 2))
for topic_numbers in tqdm(topics_list):
lda_model = LdaModel(corpus=corpus,
id2word=dictionary,
num_topics=topic_numbers)
# 计算主题模型的分数
CM = CoherenceModel(
model=lda_model,
texts=data_comment_n,
dictionary=dictionary, )
# 收集不同主题数下的一致性分数
error_list.append(CM.get_coherence())
return error_list, topics_list
def best_lda_trian():
# 使用 best_topic_numbers 作为主题数,其余参数均使用默认即可
best_lda_model = LatentDirichletAllocation(n_components=best_topic_numbers)
# 开始训练 LDA 模型
best_lda_model.fit(n_comment_count_vec)
# 设置每个主题下关联的主题词数量
topic_words_numbers = 30
# 获取所有的词典中的词语
feature_names = n_count_vectorizer.get_feature_names()
# 打印每个主题和附属的主题词
for topic_idx, topic in enumerate(best_lda_model.components_):
print("Topic # {}: ".format(int(topic_idx)))
print(" ".join([feature_names[i] for i in topic.argsort()[:-topic_words_numbers - 1:-1]]))
def topic_vis():
# 横坐标表示聚类点
plt.xlabel('topic_number')
# 纵坐标表示一致性分数
plt.ylabel('coherence_score')
# 对主题数进行标注
plt.plot(topics_list, error_list, '*-')
plt.show()
if __name__ == '__main__':
import pandas as pd
data = pd.read_csv('data/xiecheng_ugc.csv')
# 对用户评论进行名词标注
data['comment_n'] = get_n_filter(data['content'].tolist())
data_comment_n = data['comment_n'].tolist()
n_count_vectorizer = CountVectorizer(max_features=n_features)
# 对用户评价中的名词进行字典转换
n_comment_count_vec = n_count_vectorizer.fit_transform([str(i) for i in data_comment_n])
# 生成统计词典
dictionary = Dictionary(data_comment_n)
# 利用词典对生成每个词进行字典向量化
corpus = [dictionary.doc2bow(text) for text in data_comment_n]
# 开始搜素最佳主题数
error_list, topics_list = topic_number_search()
# 开始对主题数量进行可视化
topic_vis()
# 求得最大一致性分数所在的索引
max_score_index = np.argmax(error_list)
# 根据最大的值的索引找到最佳的主题数
best_topic_numbers = topics_list[max_score_index]
print('找到最佳的主题数为:{}'.format(best_topic_numbers))
# 使用找到的最佳主题数进行主题模型训练
best_lda_trian()
5 最后
**项目分享: ** https://gitee.com/asoonis/htw















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









