







Vhost-net已经悄悄地成为了基于qemu-kvm的虚拟环境中默认的流量卸载机制,利用了标准的virtio网络接口。这种机制允许在一个内核模块中执行网络处理,从而释放了qemu进程,提高了整体的网络性能。
在之前的博客文章中,我们以高层次的概述介绍了构成这种架构的不同元素,并详细解释了这些元素如何协同工作。在本文中,我们将提供一个逐步操作的实际操作指南,教你如何设置这个示例架构。一旦运行起来,我们将能够检查主要组件的运行情况。
在阅读本文后(希望您能在自己的计算机上重新创建这个环境),您将熟悉虚拟化中常用的工具(如virsh),知道如何设置vhost-net环境,以及如何检查运行中的虚拟机并测量其网络性能。
安装环境
要求:
运行Linux发行版的计算机。本指南专注于Fedora 30,但对于其他Linux发行版,命令应该没有显著变化。
具有sudo权限的用户
家目录中约25GB的可用空间
至少8GB的RAM
首先,让我们安装需要的软件包:
user@host $ sudo dnf install qemu-kvm libvirt-daemon-qemu libvirt-daemon-kvm libvirt iperf3 virt-install libguestfs-tools-c kernel-tools
如果要进行基准测试,还需要安装netperf。为此,您可以获取适用于您的操作系统的软件包之一。在编写本文时,您可以执行以下命令安装最新版本:
user@host $ sudo dnf install https://raw.githubusercontent.com/rpmsphere/x86_64/master/n/netperf-2.7.0-2.1.x86_64.rpm
在以后需要时,您还需要在虚拟机中安装netperf!
为了能够使用libvirt,您的用户必须是libvirt组的一部分:
user@host $ sudo usermod -a -G libvirt $(whoami)
在修改用户的组成员身份后,您可能需要重新登录以使更改生效。此外,您需要重新启动libvirt:
user@host $ sudo systemctl restart libvirtd
Creating a VM
首先,下载最新的Fedora-Cloud-Base镜像:
user@host $ sudo wget -O /var/lib/libvirt/images/Fedora-Cloud-Base-30-1.2.x86_64.qcow2 http://fedora.inode.at/releases/30/Cloud/x86_64/images/Fedora-Cloud-Base-30-1.2.x86_64.qcow2
(请注意上面的URL可能会更改,请更新为http://fedora.inode.at/releases/30/Cloud/x86_64/images/中的最新qcow2镜像)
这将下载一个预先安装了Fedora30的版本,可以在OpenStack环境中运行。由于我们没有运行OpenStack,所以我们必须清理镜像。为此,首先我们将复制该镜像,以便将来重复使用:
user@host $ sudo qemu-img create -f qcow2 -b /var/lib/libvirt/images/Fedora-Cloud-Base-30-1.2.x86_64.qcow2 /var/lib/libvirt/images//virtio-test1.qcow2 20G
如果我们导出以下变量,可以使用非特权用户(推荐)执行以下libvirt命令
user@host $ export LIBVIRT_DEFAULT_URI="qemu:///system"
现在,执行清理命令(将密码更改为您自己的密码):
user@host $ sudo virt-sysprep --root-password password:changeme --uninstall cloud-init --selinux-relabel -a /var/lib/libvirt/images/virtio-test1.qcow2
这个命令会挂载文件系统,并自动应用一些基本的配置,以便镜像可以重新启动。
我们还需要一个网络来连接我们的虚拟机。Libvirt以与管理虚拟机类似的方式处理网络,您可以使用XML文件定义网络,并通过命令行启动或停止它。
在这个示例中,我们将使用一个名为“default”的网络,它的定义已经包含在libvirt中以方便使用。以下命令定义了“default”网络,启动它并检查它是否正在运行。
user@host $ virsh net-define /usr/share/libvirt/networks/default.xml
Network default defined from /usr/share/libvirt/networks/default.xml
user@host $ virsh net-start default
Network default started
user@host $virsh net-list
Name State Autostart Persistent
--------------------------------------------
default active no yes
最后,我们可以使用virt-install来创建虚拟机。这个命令行实用程序会为一组知名操作系统创建所需的定义。这将为我们提供基本的定义,然后我们可以进行自定义:
user@host $ virt-install --import --name virtio-test1 --ram=4096 --vcpus=2 \
--nographics --accelerate \
--network network:default,model=virtio --mac 02:ca:fe:fa:ce:01 \
--debug --wait 0 --console pty \
--disk /var/lib/libvirt/images/virtio-test1.qcow2,bus=virtio --os-variant fedora30
除了根据我们指定的选项定义虚拟机之外,virt-install命令还应该已经为我们启动了虚拟机,因此我们应该能够列出它:
user@host $ virsh list
Id Name State
------------------------------
1 virtio-test1 running
大功告成!我们的虚拟机正在运行。
作为一个提醒,virsh是与libvirt守护程序通信的命令行接口。您可以通过运行以下命令来启动虚拟机:
user@host $ virsh start virtio-test1
通过运行以下命令跳转到控制台:
user@host $ virsh console virtio-test1
通过运行以下命令停止虚拟机:
user@host $ virsh shutdown virtio-test1
通过运行以下命令删除虚拟机(如果您不想再次创建虚拟机,请勿立即执行!):
user@host $ virsh undefine virtio-test1
检查客户端
如前所述,virt-install 命令已自动使用 libvirt 创建并启动了一个虚拟机。使用 libvirt 创建的每个虚拟机都由一个 XML 文件描述,该文件定义了正在模拟的硬件。让我们通过转储其内容来查看此文件的相关部分:
user@host $ virsh dumpxml virtio-test1
具体来说,让我们查看virt-install为我们创建的网络设备:
<devices>
...
<interface type='network'>
<mac address='02:ca:fe:fa:ce:01'/>
<source network='default' bridge='virbr0'/>
<target dev='vnet0'/>
<model type='virtio'/>
<alias name='net0'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
…
</devices>
我们可以看到已经创建了一个virtio设备,并且它连接到一个网络中,其中包括一个Linux桥接(名为virbr0)。 此外,该设备已被分配了一个PCI域、总线和插槽。
现在,让我们进入虚拟机的控制台,看看它从内部是什么样子的:
user@host $ virsh console virtio-test1
一旦登录(使用您在virt-sysprep步骤中配置的密码),在继续之前,让我们安装一些软件包:
[root@guest ~]# dnf install pciutils iperf3
现在,让我们四处看看。我们可以看到我们的虚拟PCI总线上确实有一个网络设备(根据您的XML修改PCI总线,或者首先使用lspci检查):
[root@localhost ~]# lspci -s 0000:01:00.0 -v
01:00.0 Ethernet controller: Red Hat, Inc. Virtio network device (rev 01)
Subsystem: Red Hat, Inc. Device 1100
Physical Slot: 0
Flags: bus master, fast devsel, latency 0, IRQ 21
Memory at fda40000 (32-bit, non-prefetchable) [size=4K]
Memory at fea00000 (64-bit, prefetchable) [size=16K]
Expansion ROM at fda00000 [disabled] [size=256K]
Capabilities: [dc] MSI-X: Enable+ Count=3 Masked-
Capabilities: [c8] Vendor Specific Information: VirtIO: <unknown>
Capabilities: [b4] Vendor Specific Information: VirtIO: Notify
Capabilities: [a4] Vendor Specific Information: VirtIO: DeviceCfg
Capabilities: [94] Vendor Specific Information: VirtIO: ISR
Capabilities: [84] Vendor Specific Information: VirtIO: CommonCfg
Capabilities: [7c] Power Management version 3
Capabilities: [40] Express Endpoint, MSI 00
Kernel driver in use: virtio-pci
除了典型的PCI信息(如内存区域和功能),我们还看到使用的驱动程序是virtio-pci。此驱动程序实现了通用的PCI上的virtio功能,并创建了一个virtio设备,然后由virtio_net驱动,如果我们稍微进一步检查PCI设备,我们可以看到:
[root@localhost ~]# readlink /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0/virtio0/driver
../../../../../bus/virtio/drivers/virtio_net
virtio_net驱动程序负责为操作系统的其余部分创建一个网络接口:
[root@localhost ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 02:ca:fe:fa:ce:01 brd ff:ff:ff:ff:ff:ff
[root@localhost ~]#
在主机上检查
好的,我们已经查看了客户端,现在让我们查看主机。请注意,如果我们配置一个类型为“network”的接口,则默认行为是使用vhost-net。
首先,让我们查看是否加载了vhost-net:
user@host $ sudo lsmod | grep vhost
vhost_net 32768 1
vhost 53248 1 vhost_net
tap 28672 1 vhost_net
tun 57344 4 vhost_net
我们还可以通过检查QEMU与tun、kvm和vhost-net设备以及QEMU进程为它们分配的文件描述符之间的交互来检查它们(实际的文件描述符ID可能会有所变化),检查/proc文件系统:
user@host $ ls -lh /proc/$(pgrep qemu)/fd | grep '/dev'
...
lrwx------. 1 qemu qemu 64 Aug 27 06:38 13 -> /dev/kvm
lrwx------. 1 qemu qemu 64 Aug 27 06:38 30 -> /dev/net/tun
lrwx------. 1 qemu qemu 64 Aug 27 06:38 31 -> /dev/vhost-net
这意味着除了打开了一个kvm设备来执行实际的虚拟化并创建了一个tun/tap设备外,qemu进程还打开了一个vhost-net设备。此外,我们还可以看到与我们的qemu实例相关联的vhost内核线程已经创建:
user@host $ ps -ef | grep '\[vhost'
root 21743 2 0 14:11 ? 00:00:00 [vhost-21702]
$ pgrep qemu
21702
最后,我们可以看到由qemu进程创建的tun接口(也可以看到qemu打开的文件描述符),以及连接主机和客户机的桥接接口。请注意,尽管tap设备附加到了qemu进程,但vhost-net内核线程才是实际的tap读写者。
user@host $ # ip -d tuntap
virbr0-nic: tap persist
Attached to processes:
vnet0: tap vnet_hdr
Attached to processes:qemu-system-x86(21702)
好的,vhost已经启动并运行了,qemu也连接到了它。现在,让我们生成一些流量,看看系统的性能如何。
生成流量
如果您正确地按照先前的步骤操作,可以使用它们的IP地址从主机发送数据到虚拟机,反之亦然。例如,使用iperf3测试网络性能。请注意,这些测量不是正式的基准测试,任何参数的微小变化,如软件或硬件版本或不同的网络堆栈参数,都可能显著改变所获得的结果。性能调优或特定用途的基准测试不在本文档的范围之内。
首先检查虚拟机的IP地址,并在其上执行iperf3服务器(或任何您想要用于检查连通性或进行基准测试的工具):
[root@guest ~]# ip addr
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 02:ca:fe:fa:ce:01 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.41/24 brd 192.168.122.255 scope global dynamic noprefixroute eth0
valid_lft 2534sec preferred_lft 2534sec
inet6 fe80::ca:feff:fefa:ce01/64 scope link
valid_lft forever preferred_lft forever
[root@localhost ~]# iperf3 -s
user@host $ iperf3 -c 192.168.122.41
...
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 26.3 GBytes 22.6 Gbits/sec 0 sender
[ 5] 0.00-10.04 sec 26.3 GBytes 22.5 Gbits/sec receiver
以及主机上的iperf3客户端:
user@host $ iperf3 -c 192.168.122.41
...
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 26.3 GBytes 22.6 Gbits/sec 0 sender
[ 5] 0.00-10.04 sec 26.3 GBytes 22.5 Gbits/sec receiver
在iperf3的输出中,我们可以看到在两个方向上的传输速度约为22.5 Gbit/sec(请记住,网络带宽取决于许多因素,所以不要期望在您的环境中获得相同的速度)。我们可以修改数据包的大小(使用-l选项)以增加数据平面的负载。
如果在iperf3测试期间运行top命令,我们可以看到vhost-$pid内核线程正在使用一个完整的核心进行数据包转发,而QEMU几乎使用了两个核心。
user@host $ top
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14548 qemu 20 0 6094256 1.1g 22304 S 180.5 3.5 1:37.80 qemu-system-x86
14586 root 20 0 0 0 0 R 99.7 0.0 0:20.83 vhost-14548
14753 root 20 0 3904 2360 2116 R 57.0 0.0 0:13.39 iperf3
要测量延迟,我们使用netperf命令启动netperf服务器,然后使用以下命令来测量延迟:
user@host $ netperf -l 30 -H 192.168.122.41 -p 16604 -t TCP_RR
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
212992 212992 1 1 30.00 28822.60
因此,该示例中的延迟为1/28822.60 = 0.000000347秒,因为所有请求都是串行的。正如之前所说,我们并未进行适当的基准测试或精细调整。我们只是为了让您熟悉这项技术而进行这些操作。
Extra: Disable vhost-net
正如我们已经看到的,由于它带来的性能提升,vhost-net的使用是默认行为。然而,由于我们在这里是为了动手实践和学习,让我们禁用vhost-net并查看性能上的差异。通过这样做,我们将看到qemu必须处理所有数据包处理的繁重工作,以及它如何影响性能。
首先,停止虚拟机:
user@host $ virsh shutdown virtio-test1
然后,编辑虚拟机并在网络定义中添加 :
user@host $ virsh edit virtio-test1 # it will open your editor
修改网络接口,使其如下所示:
<devices>
...
<interface type='network'>
<mac address='02:ca:fe:fa:ce:01'/>
<source network='default' bridge='virbr0'/>
<target dev='vnet0'/>
<model type='virtio'/>
<driver name="qemu"/>
<alias name='net0'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
…
</devices>
退出编辑器,然后使用以下命令重新启动虚拟机:
user@host $ virsh start virtio-test1
您可以检查没有指向 /dev/vhost-net 的文件描述符了。
分析性能影响
如果我们在没有vhost-net的情况下重复上一节的基准测试,现在可以看到在top输出中没有显示vhost-net内核线程,并且我们可以看到性能下降了(约为19.2 Gb/sec):
user@host $ iperf3 -c 192.168.122.41
...
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 22.4 GBytes 19.2 Gbits/sec 2 sender
[ 5] 0.00-10.00 sec 22.4 GBytes 19.2 Gbits/sec receiver
此外,如果我们使用top命令,可以看到qemu进程的CPU使用率增加,从大约180%上升到190-260%,当然也没有vhost-$pid内核线程的迹象。
user@host $ top
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1954 qemu 20 0 6007188 569192 22020 R 220.6 1.7 2:39.32 qemu-system-x86
如果我们比较两种架构的TCP和UDP延迟,我们会发现使用vhost-net相对于QEMU提供了一致的性能提升:
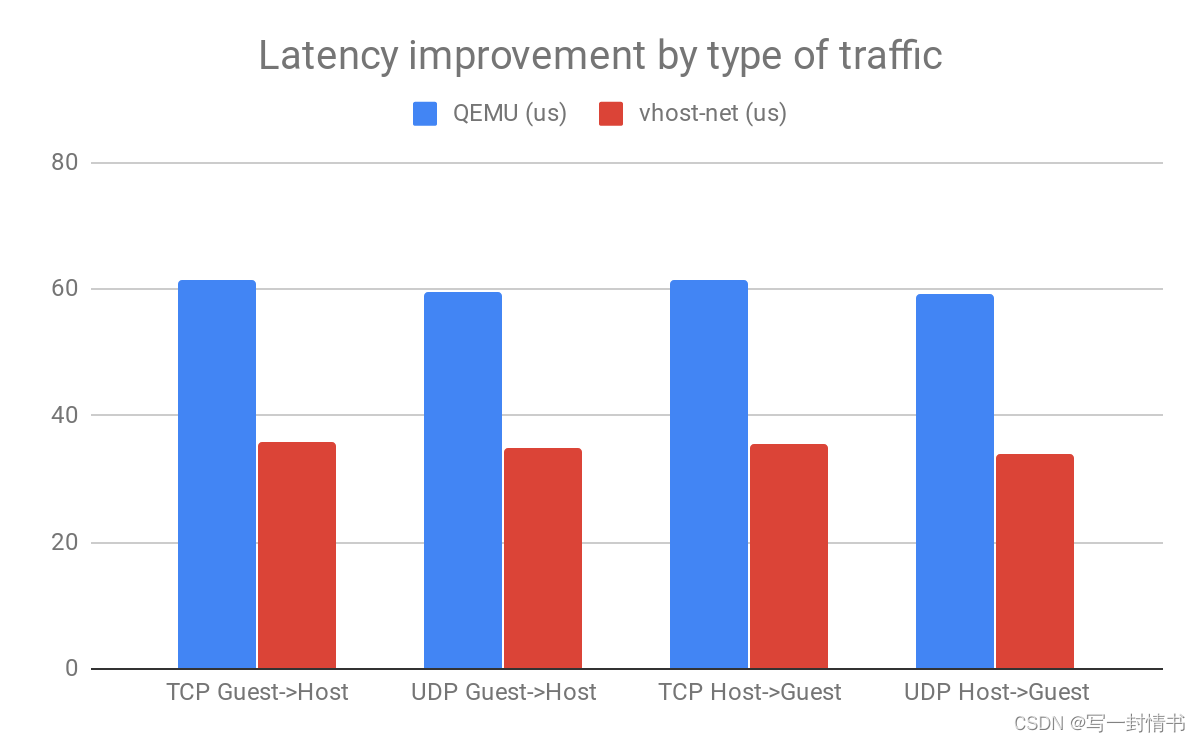
另一个了解情况的好指标是qemu必须发送给KVM的IOCTL数量。这是因为每当有一个需要由qemu处理的I/O事件时,它需要处理它并发送一个IOCTL给KVM,以便将上下文切换回客户端。我们可以使用strace命令分析qemu在每个系统调用上花费的时间。以下表格比较了使用和不使用vhost-net驱动程序时获得的结果: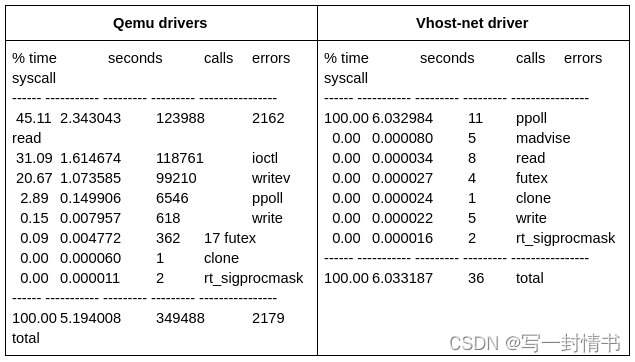
在这个表格中,我们可以看到没有vhost-user时,qemu花费了大量时间读取数据并发送IOCTL
Ansible脚本现已提供!
设置和运行此环境是为了理解、调试和测试这个架构的第一步,也是基本的步骤。为了尽快、尽可能地简化这个过程,红帽的virtio-net团队已经开发了一组Ansible脚本供每个人在GitHub上使用。
只需按照README中的说明操作,Ansible应该会处理剩下的事情。
结论
在这篇文章中,我们通过创建一个带有QEMU和vhost-net的虚拟机,检查了宿主机和客户机,以便了解这个架构的各个方面。我们还展示了vhost-net流量卸载带来的性能改进。
这是一次旅程的最后一站,旅程始于“virtio-networking和vhost-net简介”,在那里介绍了该架构的概述。接着是“深入了解virtio-networking和vhost-net”,其中详细解释了所有组件。现在,通过展示如何实际设置事物,我们总结了这个主题,希望为IT专家、架构师和开发人员提供足够的资源,以了解这项技术的优势并开始使用它。
敬请关注我们将要讨论的下一个主题:用户空间网络和DPDK!



















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











