






原文:https://arxiv.org/abs/2305.18290 (来自斯坦福大学的研究)
摘要
虽然大规模无监督语言模型(Im)学习了广泛的世界知识和一些推理技能,但由于其训练的完全无监督性质,很难实现对其行为的精确控制。获得这种可控性的现有方法收集模型生成的相对质量的人工标记,并微调无监督LM以符合这些偏好,通常通过人工反馈的强化学习(RLHF)。然而,RLHF是一个复杂且往往不稳定的过程,首先拟合反映人类偏好的奖励模型,然后使用强化学习对大型无监督LM进行微调,以在不偏离原始模型太远的情况下最大化该估计奖励。Inthis paperwe introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solvethe standard RLHF problem with only a simple classification loss.由此产生的算法,称为直接偏好优化(DPO),是稳定、高性能和计算量轻的,消除了在微调或执行重要的超参数调优期间从LM中采样的需要。实验表明,DPO可以微调语言模型以符合人类偏好,以及或优于现有方法。值得注意的是,DPO的微调在控制代的情感方面超过了基于ppo的RLHF,并匹配或提高了摘要和单回合对话的响应质量,同时大大简化了实现和训练。
1 简介
在超大数据集上训练的大型无监督语言模型(Im)获得惊人的能力[11,7,42,8]。然而,这些模型是在具有各种目标、优先级和技能的人类产生的数据上进行训练的。其中一些目标和技能可能不值得模仿;例如,虽然我们可能希望我们的AI编码助手理解常见的编程错误以纠正它们,然而,在生成代码时,我们希望使我们的模型倾向于其训练数据中存在的(可能罕见的)高质量编码能力。类似地,我们可能希望我们的语言模型是意识到的一个常见误解,50%的人相信,但我们当然不希望模型声称这种误解在50%的查询中是正确的!换句话说,从非常广泛的知识与能力中选择模型的期望的反应和行为对于构建安全、高性能和可控的AI系统[28]至关重要。虽然现有方法通常使用强化学习(RL)引导语言模型匹配人类偏好,但本文将表明,现有方法使用的基于强化学习的目标可以用一个简单的二进制交叉嫡目标进行精确优化,大大简化了偏好学习管道。
在高层次上,现有方法使用精选的人类偏好集,将所需的行为灌输到语言模型中,这些偏好集代表了人类认为安全和有帮助的行为类型。这个偏好学习阶段发生在对大型文本数据集进行大规模无监督预训练的初始阶段之后。虽然偏好学习最直接的方法是对高质量响应的人类演示进行有监督的微调,但最成功的一类方法是从人类(或AI)反馈中强化学习(RLHF/RLAIF:[12,2])。RLHF方法将奖励模型与人类似好数据集拟合,然后使用RL优化语言模型策略,以产生分配高奖励的响应,而不会偏离原始模型太远。虽然RLHF产生的模型具有令人印象深刻的对话和编码能力,但RLHF管道比监督学习要复杂得多,涉及在训练循环中训练多个语言模型并从语言模型策略中采样,导致了巨大的计算成本。
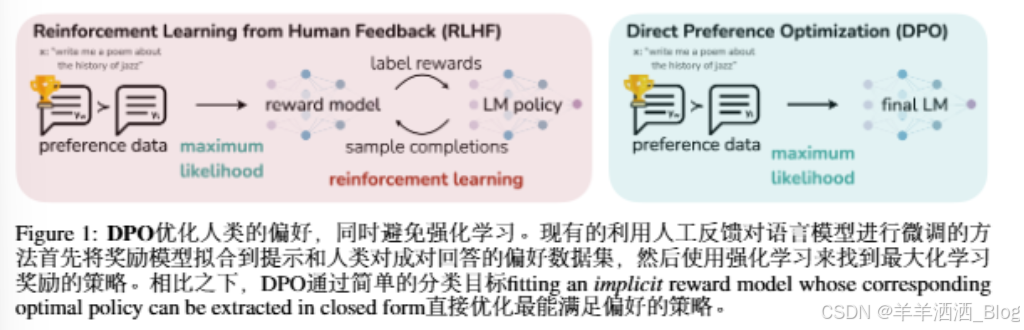
本文展示了如何直接优化语言模型,以坚持人类的偏好,而不需要明确的奖励建模或强化学习。我们提议Direct Preference Optimization(DPO),一种隐式优化与现有RLHF算法相同目标的算法(带有kl-散度约束的奖励最大化),但易于实现且训练简单。直观地说,DPO更新增加了首选响应相对于非首选响应的对数概率,但它包含了一个动态的、每个示例的重要性权重,以防止我们发现的在朴素概率比目标下发生的模型退化。像现有的算法一样,DPO依赖于一个理论偏好模型(如布拉德利-特里模型:[5]),衡量给定的奖励函数与经验偏好数据的一致性。然而,现有的方法使用偏好模型来定义偏好损失来训练奖励模型,然后训练一个优化学习奖励模型的策略,DPO使用变量的变化直接将偏好损失定义为策略的函数。给定人类对模型响应的偏好数据集,DPO因此可以使用简单的二元交叉嫡目标producing the optimal policy to an implicit reward function fit to the preference data优化策略。
我们的主要贡献是Direct Preference Optimization (DPO),一个简单的RL-free算法,用于从偏好中训练语言模型。实验表明,DPO在使用多达6B参数的语言模型从情感调制、摘要和对话等任务中的偏好中学习方面,至少与现有方法(包括基于ppo的R(LHF)一样有效。
2 相关工作
规模不断扩大的自监督语言模型可以学习完成一些任务,零样本[33]或用少样本提示[6,27,11]。然而,它们在下游任务上的性能和与用户意图的对齐可以通过对指令和人工编写的完成数据集进行微调来显著提高[25,38,13,41]。这个"指令调整"过程使llm能够泛化到指令调优集之外的指令,并通常增加其可用性[13]。尽管指令调优取得了成功,但对响应质量的相对人工判断往往比专家演示更容易收集,因此后续工作用人类偏好的数据集对llm进行了微调,提高了翻译的熟练程度[20]、摘要[40,51]、故事讲述51]和指令遵循[28,34]。这些方法首先优化神经网络奖励函数以兼容偏好模型下的偏好数据集,如布拉德利-特里模型[5].然后使用强化学习算法微调语言模型以最大化给定的奖励,通常强化[47],近端策略优化(PPO;[39]),或变体[34]。密切相关的工作利用对指令跟踪进行微调的LLM与人工反馈,为目标属性(如安全性或无害性)生成额外的合成偏好数据121.仅使用来自人类的弱监督,以LLM注释的文本标题的形式。这些方法代表了两项工作的融合:一项工作是针对各种目标进行强化学习的语言模型训练[35,29,48],另一项工作是针对人类偏好学习的一般方法[12,21]。尽管使用相对人类偏好很有吸引力,但通过强化学习对大型语言模型进行微调仍然是一个重大的实际挑战;这项工作提供了一种理论证明的方法来在没有RL的情况下优化相对偏好。
在语言语境之外,从偏好中学习策略已经在bandit和强化学习环境中进行了研究,并提出了几种方法。使用偏好或行动排名,而不是奖励,被称为上下文决斗强盗(CDB;[50,14])。在没有绝对回报的情况下,CDBs的理论分析用冯·诺依曼赢家替代了最优策略的概念,该策略相对于任何其他策略的预期胜率至少为50%[14]。然而,在CDB设置中,偏好标签是在线给出的,而在从人类偏好中学习时,我们通常从固定的一批离线偏好标注的动作对[49]中学习。类似地,基于偏好的强化学习(PbRL)从未知的"评分"函数而不是奖励生成的二进制偏好中学习[9,37]。存在各种用于PbRL的算法,包括可以重用策略外偏好数据的方法,但通常涉及首先显式估计潜在评分函数(即奖励模型),然后对其进行优化(16,9,12,36,21]。本文提出一种单阶段策略学习方法,直接优化策略以满足偏好。
3 开场白
我们将在Ziegleretal(以及稍后的[40.1,28])中查看RLHF管道。它通常包括三个阶段:1)有监督的微调(SFT);2)偏好采样和奖励学习和3)RL优化。
SFT:RLHF通常首先对预训练的LM进行微调,对感兴趣的下游任务(讨话、摘要等)的高质量数据进行监督学习,以获得一个模型![]() .奖励建模阶段:在第二阶段,SFT模型被提示x生成成对的答案
.奖励建模阶段:在第二阶段,SFT模型被提示x生成成对的答案![]() . 然后将这些内容呈现给人类标注者,他们表示对一个答案的偏好,表示为
. 然后将这些内容呈现给人类标注者,他们表示对一个答案的偏好,表示为![]() ,其中ym和yl分别表示在(y1,y2)中首选和不首选的完成。这些偏好被假定是由一些我们无法访问的潜在奖励模型r*(y,エ)生成的。有许多方法用于建模偏好,布拉德利-特里(BT)[5]模型是一个流行的选择(尽管更通用的Plackett-Luce排名模型[32,23]也与框架兼容,如果我们可以访问几个排名答案)。BT模型规定人类的偏好分布p*可以写成:
,其中ym和yl分别表示在(y1,y2)中首选和不首选的完成。这些偏好被假定是由一些我们无法访问的潜在奖励模型r*(y,エ)生成的。有许多方法用于建模偏好,布拉德利-特里(BT)[5]模型是一个流行的选择(尽管更通用的Plackett-Luce排名模型[32,23]也与框架兼容,如果我们可以访问几个排名答案)。BT模型规定人类的偏好分布p*可以写成:
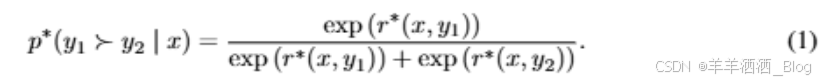
假设访问从![]() 采样的静态比较数据集
采样的静态比较数据集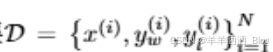 我们可以将奖励模型参数化
我们可以将奖励模型参数化![]() 并通过最大似然估计参数。假设问题为二分类问题,我们得到f负对数似然损失:
并通过最大似然估计参数。假设问题为二分类问题,我们得到f负对数似然损失:
![]()

4. 直接偏好优化
在将强化学习算法应用于大规模问题(如微调语言模型)的挑战的激励下,本文的目标是推导出一种直接使用偏好进行策略优化的简单方法。与之前的RLHF方法不同,之前的RLHF方法学习奖励,然后通过RL优化它,我们的方法leverages a particular choice of reward model parameterization that enables extraction of its optimal policy in closed form, without an RL training loop。正如我们接下来将详细描述的,我们的关键见解是利用从奖励函数到最优策略的分析映射,这使我们能够将奖励函数上的损失函数转换为策略上的损失函数。这种改变变量的方法avoids fitting an explicit, standalone reward model,同时仍然在现有的人类偏好模型下优化, 如布拉德利-特里模型。本质上, 策略网络代表了语言模型型和(implicit)奖励。
制定DPO目标。我们从与之前工作相同的RL目标开始, Eq.3,在一般奖励函数r下。以下之前的工作[31,30,19,15], 很容易表明Eq.3中kl约束奖励最大化目标的最优解采用以下形式:




评估。我们的实验使用了两种不同的评估方法。为了分析每种算法在优化约束奖励最大化目标方面的有效性,在受控情感生成环境下,通过其实现的奖励动前沿和与参考策略的kl-散度来评估每种算法:这个边界是可计算的,因为我们可以获得ground-truth奖励函数(情感分类器)。然而,在现实世界中,ground truth奖励函数是未知的;本文以相对于基线策略的胜率来评估算法,用GPT-4作为人工评估摘要质量和响应有用性的代理,分别在摘要和单回合对话设置中。对于摘要,我们使用测试集中的参考摘要作为基线;对于对话,我们使用测试数据集中的首选响应作为基线。虽然现有研究表明LMs可以成为比现有指标更好的自动评估器[10],但我们进行了一项人类研究,以证明我们在6.4节中使用GPT-4进行评估的可行性。GPT-4判断与人类有很强的相关性,人类与GPT-4的一致性通常类似或高于人类之间的标注者一致性。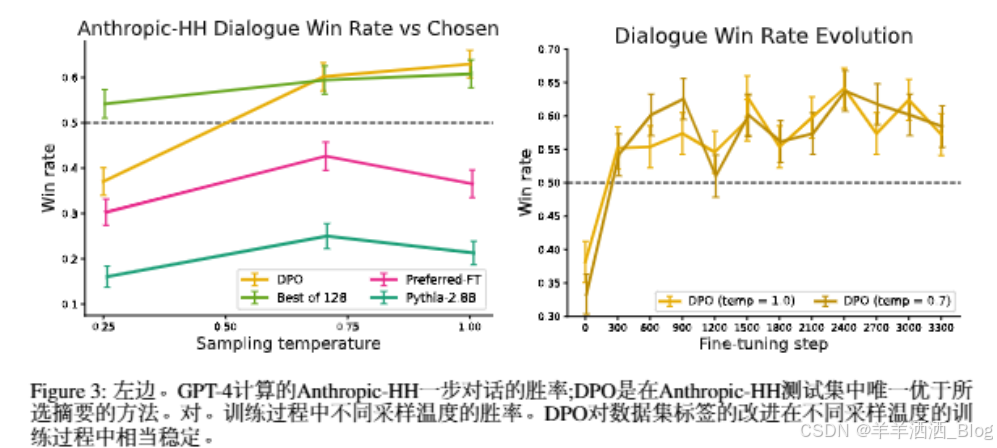
方法。除了DPO之外,本文评估了几种现有的训练语言模型的方法,以坚持人类的偏
好。最简单的是,我们在摘要任务中探索了GPT-J[45]的零样本提示,在对话任务中探索
了Pythia-2.8B[3]的2样本提示。评估了SFT模型和Preferred-FT, Preferred-FT是一个在SFT模
型(受控情感和摘要)或通用语言模型(单回合对话)中选择的完成度yw上通过监督学习进行微
调的模型。另一种伪监督方法是Unlikelihood[46],它只是优化策略以最大化分配给过的概率并最小化分配给yl的概率;我们在"不可能"一词上使用可选系数![]() 。我们还考虑使用从偏好数据中学习的奖励函数PPO[39]和PPO-gt,这是一个从受控情感设置中可用的地面真实奖励函数中学习的oracle。在我们的情感实验中,我们使用了PPO-gt的两个实现,一个是货架上的版本[44],以及一个修改版本将奖励规范化,并进一步调整超参数以提高性能(我们在运行具有学习奖励的"正常"PPO时也使用这些修改)。最后,我们考虑N基线的最好情况,从SFT模型(或对话中的Preferred-FT)中采样N响应,并根据从偏好数据集中学习的奖励函数返回得分最高的响应。这种高性能方法将奖励模型的质量与PPO优化解耦,但即使对于中等的N在计算上也是不切实际的,因为它在测试时需要为每个查询采样N完成。
。我们还考虑使用从偏好数据中学习的奖励函数PPO[39]和PPO-gt,这是一个从受控情感设置中可用的地面真实奖励函数中学习的oracle。在我们的情感实验中,我们使用了PPO-gt的两个实现,一个是货架上的版本[44],以及一个修改版本将奖励规范化,并进一步调整超参数以提高性能(我们在运行具有学习奖励的"正常"PPO时也使用这些修改)。最后,我们考虑N基线的最好情况,从SFT模型(或对话中的Preferred-FT)中采样N响应,并根据从偏好数据集中学习的奖励函数返回得分最高的响应。这种高性能方法将奖励模型的质量与PPO优化解耦,但即使对于中等的N在计算上也是不切实际的,因为它在测试时需要为每个查询采样N完成。
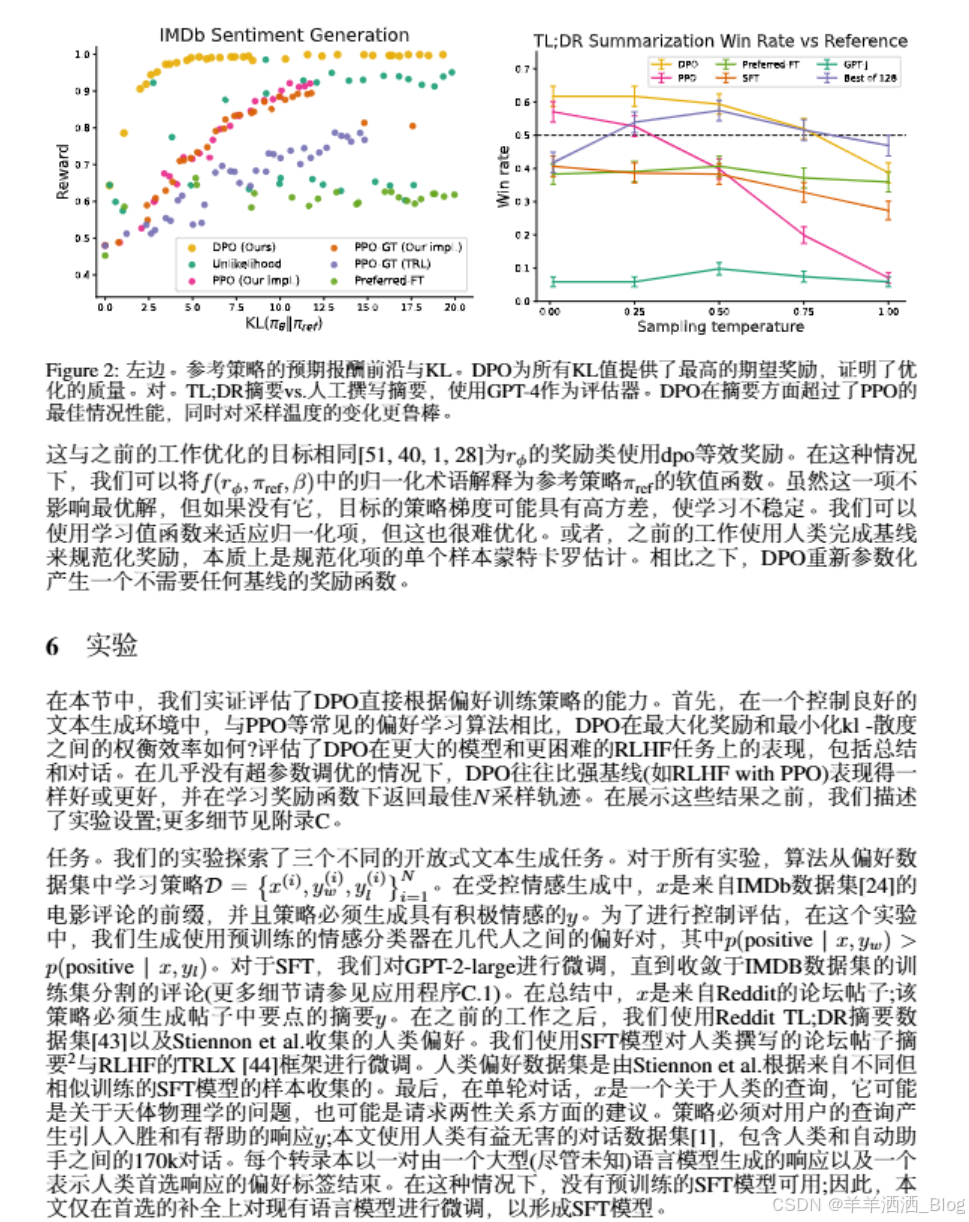
6.1 DPO如何优化RLHF目标?
典型RLHF算法中使用的kl约束奖励最大化目标在平衡奖励利用的同时限制策略远离参考策略。因此,在比较算法时,我们必须同时考虑所获得的奖励和KL差异;获得稍高的奖励但具有更高的KL并不一定令人满意。图2显示了情感设置中各种中算法的奖励-kl边界。我们对每个算法执行多次训练运行,在每次运行中使用不同的超参数来进行策略保守性(PPO的目标KL {3,6,9,12}, β {0.05,0.1,1,5},α {0.05,0.1,0.5,1}为不可能性,preferred-FT的随机种子)。这次扫描总共包括22次。在每100个训练步骤后直到收敛,我们在一组测试提示上评估每个策略,计算真实奖励函数下的平均奖励以及平均序列级KL3与参考策略KL(π || πref)。DPO产生了迄今为止最有效的前沿,实现了最高的奖励,同时仍然实现了低KL,这一结果因多种原因而特别显著。首先,DPO和PPO优化的目标相同,但DPO明显更高效:DPO的奖励/KL交易严格控制着PPO。其次,DPO比PPO取得了更好的前沿,即使PPO可以获得地面真相奖励(PPO-gt)。
6.2 DPO能扩展到真实的偏好数据集吗?
评估了DPO在摘要和单回合对话上的微调性能。总结一下,像ROUGE这样的自动评估指标与人类偏好的相关性很差[40],之前的工作已经发现,使用PPO对人类偏好进行微调的语言模型可以提供更有效的摘要。通过在TL:DR摘要数据集的测试分割上采样完成率来评估不同的方法,并计算测试集中相对于参考完成率的平均向胜率。所有方法的完成度在温度从0.0到1.0之间进行采样,获胜率如图2(右)所示。DPO,PPO和Preferred-FT都对相同的GPT-JSFT模型进行微调*。在0.0温度下,DPO的成功率约为61%,超过了PPO在0.0最优采样温度下57%的成功率。与最好的N基线相比,DPO还实现了更高的最大胜率。我们注意到,我们没有有意意义地调整DPO的β超参数,因此这些结果可能低估了DPO的潜力。此外,我们发现DPO对采样温度的鲁棒性比PPO更强,在高温下,PPO的性能可能会下降到基本GPT-J模型的性能。Preferred-FT与SFT模型相比并没有显著改善。在第6.4节中,还比较
了DPO和PPO的面对面人工评估,其中温度为0.25的DPO样本比温度为0的PPO样本优先选择58%在单回合对话中,通过一个人-辅助交互的步骤,在AnthropicHH数女据集[1]的测试分割子集上评估了不同的方法。GPT-4评估使用测试上的首选完成度作为参考来计算不同方法的胜率。由于这项任务没有标准的SFT模型,我们从预训练的Pythia-28B开始,使用Preferred FT在选定的补全上训练参考模型,使补全在模型的分布内然后使用DPO进行训练。还与128个首选fi完成中的最佳进行了比较(我们在该任务的128个完成中找到了N的最佳基线平台:请参阅附录图4)和两个版本的Pythia-2.8B基本模型,发现DPO对于每种方法的最佳性能温度表现同样好或更好。我们还评估了在知名来源的AnthropicHH数据集6上用PPO训练的RLHF模型,但无法找到一个比基本Pythia-2.8B模型性能更好的提示温度或采样温度。基于TL:DR的结果,以及两种方法优化的奖励函数相同的事实,我们认为Bestof 128是ppo级性能的粗略代理。总的来说,DPO是唯一一种计算高效的方法,优于AnthropicHH数据集中首选的补全方法,并提供了与128基线的最佳计算要求相似或更好的性能。最后,图3显示
了DPO相对较快地收敛到最佳性能。
6.3 对新输入分布的泛化(待补充)
6.4 用人工判断验证GPT-4判断(待补充)
7 讨论
从偏好中学习是一个强大的、可扩展的框架,用于训练有能力的、对齐的语言模型本文提出了DPO,一种简单的训练范式,用于从偏好中训练语言摸型,而不需要强化学习。DPO没有为了使用现成的强化学习算法而将偏好学习问题强制到标准的强化学习设置中,而是确定了语言模型策略和奖励函数之间的映射,仪更训练语言模型能够直接满足人类的偏好,具有简单的交叉嫡损失,而不需要强化学习或损失通用性。在几乎没有超参数调优的情况下,DPO的性能与现有的RLHF算法类似或更好,包括基于PPO的算法;因此,DPO有意义地降低了从人类偏好中训练更多语言模型的障碍。
局限性和未来工作。我们的结果为未来的工作提出了几个重要的问题。与从显式奖励函数中学习相比,DPO策略如何在分布外进行泛化?初步结果表明,DPO策略可以类似于基于ppo的模型推广,但还需要更全面的研究。例如,使用来自DPO策略的自标记进行训练是否可以同样有效地利用未标记的提示?在另一方面,奖励过度优化是如何在直接偏好优化设置中表现出来的,图3中的性能轻微下降是一个实例吗?在评估高达6B参数的模型时,探索将DPO扩展到最先进的模型的数量级是未来工作令人兴奋的方向。关于评估,发现GPT-4计算的胜率受到提示的影响;未来的工作可能会研究从自动化系统中引出高质量判断的最佳方法。最后,除了根据人类偏好训练语言模型外,DPO还有许多可能的应用,包括训练其他模态的生成模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









