







GC算法
标记整理
标记清除
缺点:和标记整理比,就是没有压缩的操作,会产生内存碎片,所以在后面的垃圾收集器大多都是使用标记整理
复制算法
分代收集算法
准确来讲,跟前面三种算法有所区别。分代收集算法就是根据对象的年代,采用上述三种算法来收集。
- 对于新生代:每次GC都有大量对象死去,存活的很少,常采用复制算法,只需要拷贝很少的对象。
- 对于老年代:常采用标整或者标清算法。
四种垃圾收集器
Java 8可以将垃圾收集器分为四类。
串行收集器Serial
为单线程环境设计且只使用一个线程进行GC,会暂停所有用户线程,不适用于服务器。就像去餐厅吃饭,只有一个清洁工在打扫。
并行收集器Parrallel
使用多个线程并行地进行GC,会暂停所有用户线程,适用于科学计算、大数据后台,交互性不敏感的场合。多个清洁工同时在打扫。
并发收集器CMS
用户线程和GC线程同时执行(不一定是并行,交替执行),GC时不需要停顿用户线程,互联网公司多用,适用对响应时间有要求的场合。清洁工打扫的时候,也可以就餐。
G1收集器
对内存的划分与前面3种很大不同,将堆内存分割成不同的区域,然后并发地进行垃圾回收。
默认垃圾收集器
默认收集器有哪些?
有Serial、Parallel、ConcMarkSweep(CMS)、ParNew、ParallelOld、G1。还有一个SerialOld,快被淘汰了。


查看默认垃圾修改器
使用java -XX:+PrintCommandLineFlags即可看到,Java 8默认使用-XX:+UseParallelGC。

七大垃圾收集器
体系结构
Serial、Parallel Scavenge、ParNew用户回收新生代;SerialOld、ParallelOld、CMS用于回收老年代。而G1收集器,既可以回收新生代,也可以回收老年代。

连线表示可以搭配使用,红叉表示不推荐一同使用,比如新生代用Serial,老年代用CMS。
Serial收集器
年代最久远,是Client VM模式下的默认新生代收集器,新生代使用复制算法,老年代使用标记整理算法
优点:单个线程收集,没有线程切换开销,拥有最高的单线程GC效率。
缺点:收集的时候会暂停用户线程。
使用-XX:+UseSerialGC可以显式开启,开启后默认使用Serial+SerialOld的组合。
ParNew收集器
也就是Serial的多线程版本,GC的时候不再是一个线程,而是多个,是Server VM模式下的默认新生代收集器,采用复制算法。老年代使用标记整理算法
使用-XX:+UseParNewGC可以显式开启,开启后默认使用ParNew+SerialOld的组合。但是由于SerialOld已经过时,所以建议配合CMS使用。
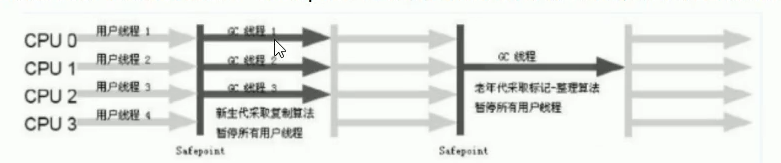
Parallel Scavenge收集器
ParNew收集器仅在新生代使用多线程收集,老年代默认是SerialOld,所以是单线程收集。而Parallel Scavenge在新、老两代都采用多线程收集。Parallel Scavenge还有一个特点就是吞吐量优先收集器,可以通过自适应调节,保证最大吞吐量。采用复制算法。
使用-XX:+UseParallelGC可以开启, 同时也会使用ParallelOld收集老年代。其它参数,比如-XX:ParallelGCThreads=N可以选择N个线程进行GC,-XX:+UseAdaptiveSizePolicy使用自适应调节策略。
SerialOld收集器
Serial的老年代版本,采用标整算法。JDK1.5之前跟Parallel Scavenge配合使用,现在已经不了,作为CMS的后备收集器。
ParallelOld收集器
Parallel的老年代版本,JDK1.6之前,新生代用Parallel而老年代用SerialOld,只能保证新生代的吞吐量。JDK1.8后,老年代改用ParallelOld。
使用-XX:+UseParallelOldGC可以开启, 同时也会使用Parallel收集新生代。
CMS收集器
并发标记清除收集器,是一种以获得最短GC停顿为目标的收集器。适用在互联网或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望停顿时间最短。是G1收集器出来之前的首选收集器。使用标清算法。在GC的时候,会与用户线程并发执行,不会停顿用户线程。但是在标记的时候,仍然会STW。
使用-XX:+UseConcMarkSweepGC开启。开启过后,新生代默认使用ParNew,同时老年代使用SerialOld作为备用。
由于并发进行,CMS在收集与应用线程会同时会增加对堆内存的占用,也就是说,CMS必须要在老年代准内存用尽之前完成垃圾回收,否则CMS回收失败时,将触发担保机制,串行老年代收集器将会以TW的方式进行一次GC,从而造成较大停顿时间
过程
- 初始标记:只是标记一下GC Roots能直接关联的对象,速度很快,需要STW。
- 并发标记:主要标记过程,标记全部对象,和用户线程一起工作,不需要STW。
- 重新标记:修正在并发标记阶段出现的变动,需要STW。
- 并发清除:和用户线程一起,清除垃圾,不需要STW。
优缺点
优点:停顿时间少,响应速度快,用户体验好。
缺点:
- 对CPU资源非常敏感:由于需要并发工作,多少会占用系统线程资源。
- 无法处理浮动垃圾:由于标记垃圾的时候,用户进程仍然在运行,无法有效处理新产生的垃圾。
- 产生内存碎片:由于使用标清算法,会产生内存碎片。
G1收集器
G1收集器与之前垃圾收集器的一个显著区别就是——之前收集器都有三个区域,新、老两代和元空间。而G1收集器只有G1区和元空间。而G1区,不像之前的收集器,分为新、老两代,而是一个一个Region,每个Region既可能包含新生代,也可能包含老年代。
G1收集器既可以提高吞吐量,又可以减少GC时间。最重要的是STW可控,增加了预测机制,让用户指定停顿时间。
区域化内存划片Region,整体编为了一些列不连续的内存区域,避免了全内存区的GC操作。
核心思想是将整个堆内存区域分成大小相同的子区域(Region),在JVM启动时会自动设置这些子区域的大小,
在堆的使用上,G1并不要求对象的存储一定是物理上连续的只要逻辑上连续即可,每个分区也不会固定地为某个代服务,可以按需在年轻代和老年代之间切换。启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB~32MB,且必 须是2的幂),默认将整堆划分为2048个分区。.
大小范围在1MB~32MB,最多能设置2048个区域,也即能够支持的最大内存为:32MB*2048=65536MB=64G的存
使用-XX:+UseG1GC开启,还有-XX:G1HeapRegionSize=n、-XX:MaxGCPauseMillis=n等参数可调。
特点
- 并行和并发:充分利用多核、多线程CPU,尽量缩短STW。
- 分代收集:虽然还保留着新、老两代的概念,但物理上不再隔离,而是融合在Region中。
- 空间整合:
G1整体上看是标整算法,在局部看又是复制算法,不会产生内存碎片。 - 可预测停顿:用户可以指定一个GC停顿时间,
G1收集器会尽量满足。
过程
与CMS类似。
- 初始标记。
- 并发标记。
- 最终标记。
- 筛选回收。

这些Region的一- 部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间。
这些Region的一部分包含 老年代,G1收集器通过将对象从-一个区域复制到另外一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有CMS内存碎片问题的存在了。
在G1中,还有一种特殊的区域,叫Humongous(巨大的)区域
如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象默认直接会被分配在年老代,但是如果.它是-个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专[存放巨型对象。如果一个H区装不下-一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。

针对Eden区进行收集,Eden区耗尽后会被触发,主要是小区域收集+形成连续的内存块,避免内存碎片*Eden区的数据移动到Survivor区,假如出现Survivor区空间不够,Eden区数据不会晋升到Old区
Survivor区的数据移动到新的Survivor区,部会数据晋升到Old区最后Eden区收拾干净了,GC结束, 用户的应用程序继续执行

附—Linux相关指令
top
主要查看%CPU、%MEM,还有load average。load average后面的三个数字,表示系统1分钟、5分钟、15分钟的平均负载值。如果三者平均值高于0.6,则复杂比较高了。当然,用uptime也可以查看。
vmstat
查看进程、内存、I/O等多个系统运行状态。2表示每两秒采样一次,3表示一共采样3次。procs的r表示运行和等待CPU时间片的进程数,原则上1核CPU不要超过2。b是等待资源的进程数,比如磁盘I/O、网络I/O等。
[root@ ~]# vmstat -n 2 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 173188 239748 1362628 0 0 0 3 17 8 0 0 99 0 0
0 0 0 172800 239748 1362636 0 0 0 0 194 485 1 1 99 0 0
1 0 0 172800 239748 1362640 0 0 0 0 192 421 1 1 99 0 0
pidstat
查看某个进程的运行信息。

free
查看内存信息。

df
查看磁盘信息。
iostat
查看磁盘I/O信息。比如有时候MySQL在查表的时候,会占用大量磁盘I/O,体现在该指令的%util字段很大。对于死循环的程序,CPU占用固然很高,但是磁盘I/O不高。

ifstat
查看网络I/O信息,需要安装。

CPU占用过高原因定位
先用top找到CPU占用最高的进程,然后用ps -mp pid -o THREAD,tid,time,得到该进程里面占用最高的线程。这个线程是10进制的,将其转成16进制,然后用jstack pid | grep tid可以定位到具体哪一行导致了占用过高。
JVM性能调优和监控工具
jps
Java版的ps -ef查看所有JVM进程。
jstack
查看JVM中运行线程的状态,比较重要。可以定位CPU占用过高位置,定位死锁位置。
jinfo/jstat
jinfo查看JVM的运行环境参数,比如默认的JVM参数等。jstat统计信息监视工具。
jmap
JVM内存映像工具。
OutOfMemoryError

StackOverflowError
栈满会抛出该错误。无限递归就会导致StackOverflowError,
是java.lang.Throwable→java.lang.Error→java.lang.VirtualMachineError下的错误。一般在递归中容易出现这种问题,当我们调用方法时就会在栈中开辟一个新的空间,
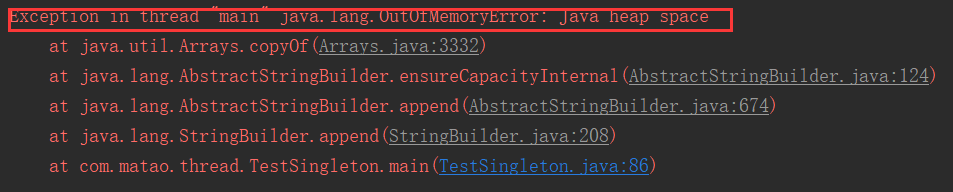
OOM—Java head space
堆满会抛出该错误。
public static void main(String[] args) {
String str = "adf";
while (true) {
str += str + new Random().nextInt(1111111) + new Random().nextInt(222222);
str.intern();
}
}
OOM—GC overhead limit exceeded
这个错误是指:GC的时候会有“Stop the World",STW越小越好,正常情况是GC只会占到很少一部分时间。但是如果用超过98%的时间来做GC,而且收效甚微,就会被JVM叫停。
OOM—GC Direct buffer memory
在写NIO程序的时候,会用到ByteBuffer来读取和存入数据。与Java堆的数据不一样,ByteBuffer使用native方法,直接在堆外分配内存。当堆外内存(也即本地物理内存)不够时,就会抛出这个异常
OOM—unable to create new native thread
在高并发应用场景时,如果创建超过了系统默认的最大线程数,就会抛出该异常。Linux单个进程默认不能超过1024个线程。
解决方法
要么降低程序线程数,
要么修改系统最大线程数vim /etc/security/limits.d/90-nproc.conf。
OOM—Metaspace
元空间满了就会抛出这个异常。
















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









