







本文是对NTIRE 2025 低照度图像增强第二名方案SG-LLIE的代码解读,原文解读请看NTIRE 2025 低照度图像增强第二名方案。
1、原文概要
SG-LLIE,是种结构先验引导的尺度感知 CNNTransformer 框架用于低光照图像增强。该方案基于 UNet 编码器 - 解码器架构,在各层级引入混合结构引导特征提取器(HSGFE)模块。HSGFE 模块通过光照不变边缘检测器提取稳定结构先验,借助结构引导 Transformer 块(SGTB)将其融入恢复过程,并结合扩张残差密集块(DRDB)和语义对齐尺度感知模块(SAM)实现多尺度特征融合。
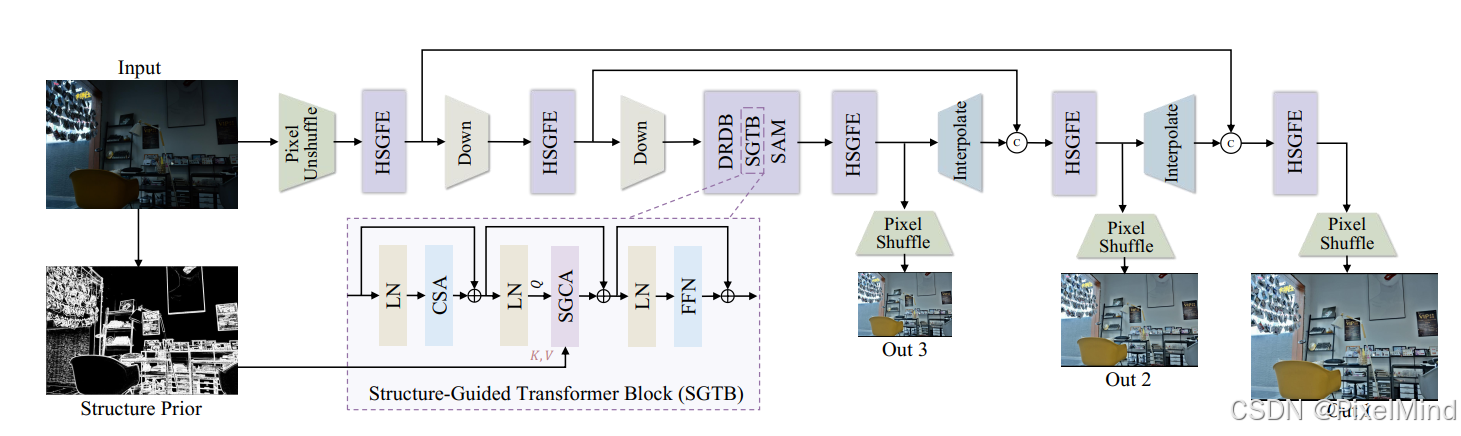
SG-LLIE的整体框架如上图所示。该结构是类似U-Net的架构。在编码器和解码器的每一层,采用了混合结构引导特征提取器(HSGFE)模块。在每个HSGFE中,包含了扩张残差密集块(DRDB)和语义对齐尺度感知模块(SAM),以及结构引导变压器块(SGTB)模块。采用Pixel Unshuffle进行下采样,Pixelshuffle进行上采样。SGTB模块中首先基于颜色不变边缘检测器提取结构先验,然后将这些先验作为Transformer的指导进行特征整合。
2、代码结构
代码整体结构如下:
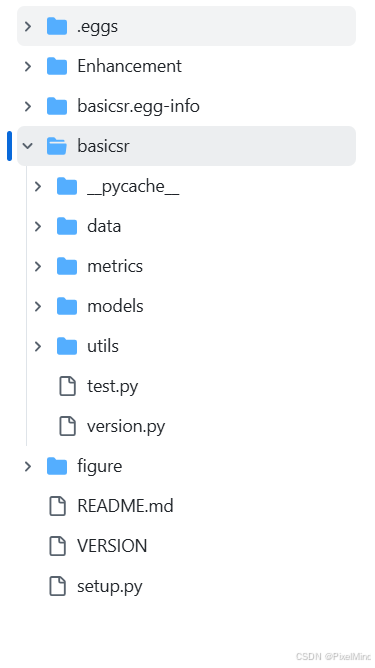
其中最主要的网络结构和损失函数文件定义在models文件夹下,网络结构主要定义在models文件夹下的archs文件夹下的UHDM_arch.py文件中。
3 、核心代码模块
UHDM_arch.py 文件
这个文件定义了整个网络结构的实现方式。我们首先对该文件做一个总体概览:
- UHDM 作为主类,调用 Encoder 和 Decoder
- Encoder 由多个 Encoder_Level 组成,下采样编码模块,每个层级包含:
- RDB:多尺度特征提取
- IGAB:条件(作者论文中提到的结构信息先验)信号整合
- SAM:多尺度特征融合
- Decoder 由多个 Decoder_Level 组成,结构与编码层级类似,但是是上采样
- SAM 模块内部使用 DB 进行特征提取,并通过 CSAF 进行注意力融合
- 所有卷积操作由 conv/conv_relu 辅助函数实现
下面我们将介绍具体每一个模块实现及功能。
1. UHDM 模型主类
class UHDM(nn.Module):
def __init__(self,
en_feature_num=48, # 编码器特征通道数
en_inter_num=32, # 编码器中间层通道数
de_feature_num=64, # 解码器特征通道数
de_inter_num=32, # 解码器中间层通道数
sam_number=2, # SAM模块数量
training = True # 训练模式标志
):
# 调用父类构造函数
super(UHDM, self).__init__()
# 初始化编码器,传入特征通道数、中间层通道数和SAM模块数量
self.encoder = Encoder(feature_num=en_feature_num, inter_num=en_inter_num, sam_number=sam_number)
# 初始化解码器,传入编码器特征数、解码器特征通道数、中间层通道数和SAM模块数量
self.decoder = Decoder(en_num=en_feature_num, feature_num=de_feature_num, inter_num=de_inter_num,
sam_number=sam_number)
def forward(self, x, s):
# 获取输入图像的尺寸
_, _, H, W = x.shape
# 定义下采样率(2^5=32),确保图像尺寸是32的倍数
rate = 2 ** 5
# 计算需要填充的高度和宽度
pad_h = (rate - H % rate) % rate
pad_w = (rate - W % rate) % rate
# 如果需要填充,则使用反射填充方式
if pad_h != 0 or pad_w != 0:
x = F.pad(x, (0, pad_w, 0, pad_h), "reflect")
# 通过编码器获取三个不同尺度的特征
y_1, y_2, y_3 = self.encoder(x, s)
# 通过解码器处理编码器特征,生成三个不同尺度的输出
out_1, out_2, out_3 = self.decoder(y_1, y_2, y_3, s)
# 裁剪输出到原始输入尺寸
out_1 = out_1[:,:,:H,:W] # 全尺寸输出
out_2 = out_2[:,:,:H//2,:W//2] # 1/2尺寸输出
out_3 = out_3[:,:,:H//4,:W//4] # 1/4尺寸输出
return out_1, out_2, out_3 # 返回三个不同尺度的输出结果
作用:
- 整体网络结构:编码器(
Encoder)和解码器(Decoder),构建完整的SG-LLIE网络层。 - 尺寸适配:对输入图像进行反射填充,确保尺寸为 (2^5=32) 的倍数,避免下采样时尺寸错位。
- 多尺度输出:返回原始尺寸(
out_1)、1/2尺寸(out_2)、1/4尺寸(out_3)的增强结果,支持多分辨率监督或特征融合这里对应作者损失函数采用多尺度进行监督。
2. 编码器类(Encoder)
class Encoder(nn.Module):
def __init__(self, feature_num, inter_num, sam_number):
# 调用父类构造函数
super(Encoder, self).__init__()
# 初始卷积层,将12通道输入转换为feature_num通道
# 使用5x5卷积核和padding=2保持空间尺寸不变
self.conv_first = nn.Sequential(
nn.Conv2d(12, feature_num, kernel_size=5, stride=1, padding=2, bias=True),
nn.ReLU(inplace=True)
)
# 第一级编码器,处理原始分辨率特征
self.encoder_1 = Encoder_Level(feature_num, inter_num, level=1, sam_number=sam_number)
# 第二级编码器,处理2倍下采样特征
self.encoder_2 = Encoder_Level(2 * feature_num, inter_num, level=2, sam_number=sam_number)
# 第三级编码器,处理4倍下采样特征
self.encoder_3 = Encoder_Level(4 * feature_num, inter_num, level=3, sam_number=sam_number)
def forward(self, x, s):
# 使用pixel_unshuffle将输入图像空间尺寸缩小一半,通道数扩展4倍
# 例如:[B, 3, H, W] -> [B, 12, H/2, W/2]
x = F.pixel_unshuffle(x, 2)
# 通过初始卷积层提取基础特征
x = self.conv_first(x)
# 第一级编码:生成本级特征和下采样特征
out_feature_1, down_feature_1 = self.encoder_1(x, s)
# 第二级编码:处理上一级下采样特征,生成中级特征和进一步下采样特征
out_feature_2, down_feature_2 = self.encoder_2(down_feature_1, s)
# 第三级编码:处理上一级下采样特征,生成高级特征(没有进一步下采样)
out_feature_3 = self.encoder_3(down_feature_2, s)
# 返回三个不同尺度的特征表示
return out_feature_1, out_feature_2, out_feature_3
作用:
- 特征下采样与分层提取:
- 通过
pixel_unshuffle将输入通道数扩大4倍(如3通道图像变为12通道),扩大初始感受野。 - 三级
Encoder_Level逐步下采样(层级1→2→3,分辨率依次为1/2、1/4、1/8),通道数翻倍,生成多尺度特征(out1, out2, out3)。
- 通过
- 条件信号集成:将全局结构引导特征
s传递给每个Encoder_Level,进行特征融合增强。
3. 编码层级类(Encoder_Level)
class Encoder_Level(nn.Module):
def __init__(self, feature_num, inter_num, level, sam_number):
# 调用父类构造函数
super(Encoder_Level, self).__init__()
# 残差密集块,用于特征提取,保持通道数不变
self.rdb = RDB(in_channel=feature_num, d_list=(1, 2, 1), inter_num=inter_num)
# 注释掉的归一化层和注意力机制(可能为调试或实验保留)
# self.norm = self.norm = nn.GroupNorm(num_groups=1, num_channels=feature_num)
# self.ig_msa = IG_MSA(dim=feature_num, dim_head=feature_num, heads=1)
# self.norm1 = nn.GroupNorm(num_groups=1, num_channels=feature_num)
# 交互式门控注意力块,结合输入特征和条件信息
self.igab = IGAB(dim=feature_num, dim_head=feature_num, heads=1)
# 创建多个SAM模块(空间注意力模块)
self.sam_blocks = nn.ModuleList()
for _ in range(sam_number):
sam_block = SAM(in_channel=feature_num, d_list=(1, 2, 3, 2, 1), inter_num=inter_num)
self.sam_blocks.append(sam_block)
# 只有前两级编码器需要下采样操作
if level < 3:
self.down = nn.Sequential(
# 步长为2的卷积,实现2倍下采样并通道数翻倍
nn.Conv2d(feature_num, 2 * feature_num, kernel_size=3, stride=2, padding=1, bias=True),
nn.ReLU(inplace=True)
)
self.level = level # 记录当前编码器层级
def forward(self, x, s):
# 通过残差密集块提取特征
out_feature = self.rdb(x)
# 根据当前层级对条件信息s进行下采样
scale_factor = 1 / (2 ** self.level)
s_ = F.interpolate(s, scale_factor=scale_factor, mode='bilinear', align_corners=False)
# 通过交互式门控注意力块融合特征和条件信息
out_feature = self.igab(out_feature, s_)
# 依次通过多个SAM模块增强特征表示
for sam_block in self.sam_blocks:
out_feature = sam_block(out_feature)
# 前两级编码器需要生成下采样特征
if self.level < 3:
down_feature = self.down(out_feature)
return out_feature, down_feature # 返回本级特征和下采样特征
return out_feature # 最后一级仅返回特征
作用:
- 多模块协作提取特征:
- RDB:通过膨胀卷积(膨胀率1, 2, 1)捕捉局部多尺度信息,密集连接增强特征复用。
- IGAB:利用全局结构引导特征
s进行全局注意力机制,抑制无关区域特征。 - SAM:通过多尺度下采样(原始、1/2、1/4尺度)和CSAF注意力融合,捕捉跨尺度上下文。
- 下采样控制:层级1和2通过步长2卷积将特征图尺寸减半、通道数翻倍。
4. 解码器类(Decoder)
class Decoder(nn.Module):
def __init__(self, en_num, feature_num, inter_num, sam_number):
# 调用父类构造函数
super(Decoder, self).__init__()
# 第三级特征预处理卷积,将4*en_num通道转换为feature_num通道
self.preconv_3 = conv_relu(4 * en_num, feature_num, 3, padding=1)
# 第三级解码器,处理最高层级特征
self.decoder_3 = Decoder_Level(feature_num, inter_num, sam_number, level=3)
# 第二级特征预处理卷积,融合编码器特征和上一级特征
self.preconv_2 = conv_relu(2 * en_num + feature_num, feature_num, 3, padding=1)
# 第二级解码器
self.decoder_2 = Decoder_Level(feature_num, inter_num, sam_number, level=2)
# 第一级特征预处理卷积,融合编码器特征和上一级特征
self.preconv_1 = conv_relu(en_num + feature_num, feature_num, 3, padding=1)
# 第一级解码器,生成最终输出
self.decoder_1 = Decoder_Level(feature_num, inter_num, sam_number, level=1)
def forward(self, y_1, y_2, y_3, s):
# 获取第三级编码器特征
x_3 = y_3
# 预处理第三级特征
x_3 = self.preconv_3(x_3)
# 通过第三级解码器生成输出和特征
out_3, feat_3 = self.decoder_3(x_3, s)
# 拼接第二级编码器特征和第三级解码器特征
x_2 = torch.cat([y_2, feat_3], dim=1)
# 预处理第二级特征
x_2 = self.preconv_2(x_2)
# 通过第二级解码器生成输出和特征
out_2, feat_2 = self.decoder_2(x_2, s)
# 拼接第一级编码器特征和第二级解码器特征
x_1 = torch.cat([y_1, feat_2], dim=1)
# 预处理第一级特征
x_1 = self.preconv_1(x_1)
# 通过第一级解码器生成最终输出(不输出特征)
out_1 = self.decoder_1(x_1, s, feat=False)
# 返回三个不同尺度的输出
return out_1, out_2, out_3
作用:
- 渐进式上采样:
- 层级3→2→1依次通过
pixel_shuffle(2)上采样,分辨率从1/8→1/4→1/2→原始尺寸,通道数从高维降至低维。
- 层级3→2→1依次通过
- 多尺度重建:生成原始尺寸(
out1)和低分辨率(out2,out3)结果,支持多分辨率监督。
5. 解码层级类(Decoder_Level)
class Decoder_Level(nn.Module):
def __init__(self, feature_num, inter_num, sam_number, level):
# 调用父类构造函数
super(Decoder_Level, self).__init__()
# 残差密集块,用于特征提取
self.rdb = RDB(feature_num, (1, 2, 1), inter_num)
# 交互式门控注意力块,融合特征与条件信息
self.igab = IGAB(dim=feature_num, dim_head=feature_num, heads=1)
# 创建多个SAM模块(空间注意力模块)
self.sam_blocks = nn.ModuleList()
for _ in range(sam_number):
sam_block = SAM(in_channel=feature_num, d_list=(1, 2, 3, 2, 1), inter_num=inter_num)
self.sam_blocks.append(sam_block)
# 卷积层,将特征通道转换为12通道(用于pixel shuffle)
self.conv = conv(in_channel=feature_num, out_channel=12, kernel_size=3, padding=1)
# 记录当前解码器层级
self.level = level
def forward(self, x, s, feat=True):
# 通过残差密集块提取特征
x = self.rdb(x)
# 根据当前层级对条件信息s进行下采样
scale_factor = 1 / (2 ** self.level)
s_ = F.interpolate(s, scale_factor=scale_factor, mode='bilinear', align_corners=False)
# 通过交互式门控注意力块融合特征和条件信息
x = self.igab(x, s_)
# 依次通过多个SAM模块增强特征表示
for sam_block in self.sam_blocks:
x = sam_block(x)
# 转换通道数为12,准备进行pixel shuffle上采样
out = self.conv(x)
# 使用pixel shuffle将通道数压缩为3,空间尺寸扩大2倍
# 例如:[B, 12, H, W] -> [B, 3, 2H, 2W]
out = F.pixel_shuffle(out, 2)
# 根据feat标志决定是否返回特征
if feat:
# 将特征上采样2倍,用于与上一层级特征融合
feature = F.interpolate(x, scale_factor=2, mode='bilinear')
return out, feature # 返回输出和上采样特征
else:
return out # 仅返回输出
作用:
- 与编码层级类对应:
与编码层级类结构对应,这里实现上采样,模块相似。
6. 尺度感知模块(SAM)
class SAM(nn.Module):
def __init__(self, in_channel, d_list, inter_num):
# 调用父类构造函数
super(SAM, self).__init__()
# 创建三个并行的密集块(DB),分别处理不同尺度的特征
self.basic_block = DB(in_channel=in_channel, d_list=d_list, inter_num=inter_num) # 原始尺度
self.basic_block_2 = DB(in_channel=in_channel, d_list=d_list, inter_num=inter_num) # 1/2尺度
self.basic_block_4 = DB(in_channel=in_channel, d_list=d_list, inter_num=inter_num) # 1/4尺度
# 特征融合模块,将三个不同尺度的特征进行融合
self.fusion = CSAF(3 * in_channel) # 输入通道数为3倍in_channel,因要拼接三个特征
def forward(self, x):
# 保存原始输入特征
x_0 = x
# 对输入特征进行下采样,得到1/2和1/4尺度的特征
x_2 = F.interpolate(x, scale_factor=0.5, mode='bilinear') # 下采样到1/2尺寸
x_4 = F.interpolate(x, scale_factor=0.25, mode='bilinear') # 下采样到1/4尺寸
# 分别通过三个密集块处理不同尺度的特征
y_0 = self.basic_block(x_0) # 处理原始尺度特征
y_2 = self.basic_block_2(x_2) # 处理1/2尺度特征
y_4 = self.basic_block_4(x_4) # 处理1/4尺度特征
# 将处理后的特征上采样回原始尺寸
y_2 = F.interpolate(y_2, scale_factor=2, mode='bilinear') # 上采样到原始尺寸
y_4 = F.interpolate(y_4, scale_factor=4, mode='bilinear') # 上采样到原始尺寸
# 通过跨尺度注意力融合模块(CSAF)融合三个不同尺度的特征
y = self.fusion(y_0, y_2, y_4)
# 残差连接,将融合后的特征与原始输入相加
y = x + y
return y # 返回增强后的特征
作用:
- 多尺度特征分解:将输入特征分解为原始、1/2、1/4三种尺度,分别通过密集块(
DB)提取不同粒度的细节(如纹理、结构)。 - 跨尺度注意力融合:利用
CSAF模块生成三尺度特征的自适应权重,抑制无关尺度的特征。 - 残差增强:融合后的特征与输入相加,构建一个残差模块,避免梯度消失,提升特征表达能力。
7. 跨尺度注意力融合模块(CSAF)
class CSAF(nn.Module):
def __init__(self, in_chnls, ratio=4):
# 调用父类构造函数
super(CSAF, self).__init__()
# 全局平均池化,将特征图压缩为1x1大小
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
# 第一层压缩卷积,减少通道数
self.compress1 = nn.Conv2d(in_chnls, in_chnls // ratio, 1, 1, 0)
# 第二层压缩卷积,进一步处理特征
self.compress2 = nn.Conv2d(in_chnls // ratio, in_chnls // ratio, 1, 1, 0)
# 激励卷积,将通道数恢复为原始数量
self.excitation = nn.Conv2d(in_chnls // ratio, in_chnls, 1, 1, 0)
def forward(self, x0, x2, x4):
# 对每个尺度的特征图进行全局平均池化
out0 = self.squeeze(x0) # [B, C, 1, 1]
out2 = self.squeeze(x2) # [B, C, 1, 1]
out4 = self.squeeze(x4) # [B, C, 1, 1]
# 在通道维度上拼接三个尺度的全局特征
out = torch.cat([out0, out2, out4], dim=1) # [B, 3C, 1, 1]
# 第一层压缩,减少通道数
out = self.compress1(out) # [B, 3C/ratio, 1, 1]
out = F.relu(out) # 应用ReLU激活函数
# 第二层压缩,保持通道数不变
out = self.compress2(out) # [B, 3C/ratio, 1, 1]
out = F.relu(out) # 应用ReLU激活函数
# 恢复通道数,为每个输入特征生成权重
out = self.excitation(out) # [B, 3C, 1, 1]
out = F.sigmoid(out) # 应用sigmoid函数将值约束在[0,1]
# 将输出通道分割为三个部分,分别作为三个输入的权重
w0, w2, w4 = torch.chunk(out, 3, dim=1) # 每个权重张量: [B, C, 1, 1]
# 对原始特征图应用注意力权重,然后相加融合
x = x0 * w0 + x2 * w2 + x4 * w4 # [B, C, H, W]
return x # 返回加权融合后的特征
作用:
- 全局特征感知:通过全局平均池化将三尺度特征压缩为通道向量,捕捉各尺度的全局统计信息。
- 自适应权重生成:通过两层卷积网络(类似SE模块)学习三尺度特征的重要性权重,解决不同场景下尺度依赖差异的问题(如小目标依赖1/4尺度,大纹理依赖原始尺度)。
- 特征精细化融合:根据权重动态调整各尺度特征的贡献,避免简单平均导致的细节模糊。
8. 残差密集块(RDB)
class RDB(nn.Module):
def __init__(self, in_channel, d_list, inter_num):
# 调用父类构造函数
super(RDB, self).__init__()
# 保存膨胀率列表,用于控制卷积层的感受野
self.d_list = d_list
# 创建密集连接的卷积层列表
self.conv_layers = nn.ModuleList()
c = in_channel # 初始通道数为输入通道数
# 为每个膨胀率创建一个卷积层,并逐步增加通道数
for i in range(len(d_list)):
dense_conv = conv_relu(
in_channel=c, # 当前输入通道数
out_channel=inter_num, # 输出通道数为中间通道数
kernel_size=3, # 3x3卷积核
dilation_rate=d_list[i], # 设置膨胀率
padding=d_list[i] # 保持特征图尺寸不变
)
self.conv_layers.append(dense_conv)
c = c + inter_num # 通道数增加,体现密集连接的特性
# 1x1卷积,用于整合所有特征并恢复原始通道数
self.conv_post = conv(
in_channel=c, # 输入通道数为所有中间特征的总和
out_channel=in_channel, # 恢复为原始输入通道数
kernel_size=1 # 使用1x1卷积
)
def forward(self, x):
t = x # 保存输入特征作为初始值
# 逐层处理,每一层的输出与之前所有层的输出拼接
for conv_layer in self.conv_layers:
_t = conv_layer(t) # 应用当前卷积层
t = torch.cat([_t, t], dim=1) # 在通道维度上拼接当前输出和之前的特征
# 通过1x1卷积整合所有特征并恢复原始通道数
t = self.conv_post(t)
# 残差连接,将处理后的特征与原始输入相加
return t + x
作用:
- 密集特征复用:每层卷积的输出与输入拼接,形成前馈式密集连接,最大化特征流动效率。
- 膨胀卷积采样:通过不同膨胀率(如1, 2, 1)的卷积核捕捉多感受野特征,等效于空洞卷积的多分支结构,但参数更少。
- 残差连接:缓解深层网络的梯度消失问题,支持模块堆叠。
9. 密集块(DB)
class DB(nn.Module):
def __init__(self, in_channel, d_list, inter_num):
# 调用父类构造函数
super(DB, self).__init__()
# 保存膨胀率列表(用于控制空洞卷积的感受野)
self.d_list = d_list
# 创建密集连接的卷积层列表
self.conv_layers = nn.ModuleList()
c = in_channel # 初始通道数为输入通道数
# 遍历膨胀率列表,为每个膨胀率创建一个卷积层
for i in range(len(d_list)):
# 定义带ReLU激活的空洞卷积层
dense_conv = conv_relu(
in_channel=c, # 当前输入通道数(逐层累加)
out_channel=inter_num, # 输出通道数固定为中间通道数
kernel_size=3, # 使用3x3卷积核
dilation_rate=d_list[i], # 设置空洞率(控制感受野大小)
padding=d_list[i] # 保持特征图尺寸不变(padding=膨胀率)
)
self.conv_layers.append(dense_conv)
c = c + inter_num # 通道数逐层累加(密集连接特性)
# 1x1卷积层:用于整合所有密集连接的特征并恢复原始通道数
self.conv_post = conv(
in_channel=c, # 输入通道数为所有卷积层输出的总和
out_channel=in_channel, # 输出通道数恢复为原始输入通道数
kernel_size=1 # 使用1x1卷积进行跨通道交互
)
def forward(self, x):
t = x # 保存输入特征,作为密集连接的初始值
# 按顺序通过每个卷积层,逐层进行密集连接
for conv_layer in self.conv_layers:
_t = conv_layer(t) # 对当前特征应用卷积和激活
t = torch.cat([_t, t], dim=1) # 在通道维度拼接当前输出与历史特征
# 通过1x1卷积整合所有通道的特征并恢复原始通道数
t = self.conv_post(t)
# 返回处理后的特征(无残差连接,仅密集特征融合)
return t
作用:
- 基础多尺度特征提取:与RDB结构类似,但不含残差连接,用于SAM模块的多尺度分支中,轻量化提取局部特征。
- 密集连接增强:通过拼接操作保留所有中间层特征,避免浅层信息丢失。
10. IG_MSA(交互式全局多头自注意力模块)
class IG_MSA(nn.Module):
def __init__(
self,
dim, # 输入特征维度
dim_head=64, # 每个注意力头的维度
heads=8, # 注意力头的数量
):
super().__init__()
self.num_heads = heads
self.dim_head = dim_head
# 线性投影层:将输入特征映射到查询(Q)、键(K)和值(V)空间
self.to_q = nn.Linear(dim, dim_head * heads, bias=False)
self.to_k = nn.Linear(dim, dim_head * heads, bias=False)
self.to_v = nn.Linear(dim, dim_head * heads, bias=False)
# 可学习的注意力缩放参数,用于调整注意力矩阵的强度
self.rescale = nn.Parameter(torch.ones(heads, 1, 1))
# 输出投影层:将多头注意力的输出重新投影回原始维度
self.proj = nn.Linear(dim_head * heads, dim, bias=True)
# 空间位置编码模块:通过深度可分离卷积捕获局部空间信息
self.pos_emb = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1, bias=False, groups=dim),
GELU(),
nn.Conv2d(dim, dim, 3, 1, 1, bias=False, groups=dim),
)
self.dim = dim
def forward(self, x_in):
"""
x_in: [b,h,w,c] # 输入特征图
return out: [b,h,w,c] # 输出特征图(保持与输入相同的形状)
"""
# 获取输入特征的形状
b, h, w, c = x_in.shape
# 将特征图展平为序列:[b,h,w,c] -> [b,h*w,c]
x = x_in.reshape(b, h * w, c)
# 生成查询(Q)、键(K)和值(V)矩阵
q_inp = self.to_q(x)
k_inp = self.to_k(x)
v_inp = self.to_v(x)
# 将QKV矩阵分割为多个注意力头,并调整维度
# 从 [b,n,heads*dim_head] 变为 [b,heads,n,dim_head]
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.num_heads),
(q_inp, k_inp, v_inp))
# 对Q、K矩阵进行维度转置和L2归一化,提高注意力计算的稳定性
q = q.transpose(-2, -1) # [b,heads,dim_head,n]
k = k.transpose(-2, -1) # [b,heads,dim_head,n]
v = v.transpose(-2, -1) # [b,heads,dim_head,n]
q = F.normalize(q, dim=-1, p=2) # L2归一化
k = F.normalize(k, dim=-1, p=2) # L2归一化
# 计算注意力矩阵:键(K)与查询(Q)的点积,得到注意力权重
# 形状从 [b,heads,dim_head,n] × [b,heads,n,dim_head] -> [b,heads,dim_head,dim_head]
attn = (k @ q.transpose(-2, -1))
# 应用可学习的缩放参数,调整注意力矩阵的强度
attn = attn * self.rescale
# 对注意力矩阵进行softmax操作,将值归一化为概率分布
attn = attn.softmax(dim=-1)
# 通过注意力矩阵加权聚合值(V)矩阵
# 形状从 [b,heads,dim_head,dim_head] × [b,heads,dim_head,n] -> [b,heads,dim_head,n]
x = attn @ v
# 调整维度顺序并重塑,将多头结果合并
x = x.permute(0, 3, 1, 2) # [b,n,heads,dim_head]
x = x.reshape(b, h * w, self.num_heads * self.dim_head)
# 通过线性投影将特征维度恢复为原始维度,得到内容相关的特征
out_c = self.proj(x).view(b, h, w, c)
# 应用空间位置编码:对值矩阵应用深度可分离卷积,捕获局部空间信息
out_p = self.pos_emb(v_inp.reshape(b, h, w, c).permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
# 将内容特征和位置特征相加,融合全局上下文和局部空间信息
out = out_c + out_p
return out
作用:
典型的多头注意力模块。
11. IGAB(交互式全局注意力块)
class IGAB(nn.Module):
def __init__(
self,
dim, # 输入特征维度
dim_head=64, # IG_MSA中每个头的维度
heads=8, # 注意力头的数量
num_blocks=2, # 块的数量(每个块包含一组子模块)
):
super().__init__()
self.blocks = nn.ModuleList() # 存储多个注意力块
# 构建每个注意力块,包含IG_MSA、层归一化、交叉注意力、前馈网络
for _ in range(num_blocks):
self.blocks.append(nn.ModuleList([
IG_MSA(dim=dim, dim_head=dim_head, heads=heads), # IG_MSA模块
LayerNorm(dim), # 层归一化
Cross_attention(dim, num_heads=heads, bias=False), # 交叉注意力模块
PreNorm(dim, FeedForward(dim=dim)) # 带归一化的前馈网络
]))
# 条件信号s的处理模块:卷积+层归一化
self.s_conv = nn.Conv2d(3, dim, kernel_size=3, stride=1, padding=1) # 假设s是3通道图像(如光照图)
self.s_norm = LayerNorm(dim) # 归一化条件信号特征
def forward(self, x, s):
"""
x: [b, c, h, w] 输入特征图(通道优先格式)
s: [b, 3, h, w] 条件信号(如光照图,3通道)
"""
# 处理条件信号s:卷积+归一化,转为维度[dim]的特征图
s = self.s_conv(s) # [b, 3, h, w] -> [b, dim, h, w]
s = self.s_norm(s) # 层归一化,适配后续交叉注意力计算
# 将输入x转为通道最后格式([b, h, w, c])以适配IG_MSA输入要求
x = x.permute(0, 2, 3, 1) # [b, c, h, w] -> [b, h, w, c]
# 依次通过每个注意力块
for (attn, cross_norm, cross_attn, ff) in self.blocks:
# 1. 自注意力分支:IG_MSA + 残差连接
x = attn(x) + x # 输入与IG_MSA输出相加,保留原始特征
# 2. 交叉注意力分支:处理条件信号s与特征x的交互
# - 将x转回通道优先格式,归一化后输入交叉注意力
x_cross = x.permute(0, 3, 1, 2) # [b, h, w, c] -> [b, c, h, w]
x_cross = cross_norm(x_cross) # 层归一化
# - 计算x与s之间的交叉注意力
x = cross_attn(x_cross, s) + x # 交叉注意力输出与当前x相加
# 3. 前馈网络分支:非线性变换 + 残差连接
x = ff(x) + x # 前馈网络输出与当前x相加
# 将输出转回通道优先格式([b, c, h, w])
out = x.permute(0, 3, 1, 2)
return out
class Cross_attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Cross_attention, self).__init__()
self.num_heads = num_heads # 注意力头的数量
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1)) # 可学习的温度参数,调整注意力锐度
# 条件信号s的键(K)和值(V)生成器:1x1卷积+深度可分离卷积
self.kv = nn.Conv2d(dim, dim*2, kernel_size=1, bias=bias) # 生成KV初始特征
self.kv_dwconv = nn.Conv2d(dim*2, dim*2, kernel_size=3, stride=1, padding=1, groups=dim*2, bias=bias) # 深度可分离卷积增强空间信息
# 输入特征x的查询(Q)生成器:1x1卷积+深度可分离卷积
self.q = nn.Conv2d(dim, dim, kernel_size=1, bias=bias) # 生成Q初始特征
self.q_dwconv = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim, bias=bias) # 深度可分离卷积增强空间信息
# 输出投影层:将交叉注意力输出映射回原始维度
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x, s):
"""
x: [b, c, h, w] 输入特征图(查询Q,通道优先格式)
s: [b, c, h, w] 条件信号(键K和值V,通道优先格式)
"""
b, c, h, w = x.shape # 获取输入尺寸
# 1. 生成条件信号s的键(K)和值(V)
kv = self.kv(s) # [b, c, h, w] -> [b, 2c, h, w](KV共享通道)
kv = self.kv_dwconv(kv) # 深度可分离卷积提取空间特征
k, v = kv.chunk(2, dim=1) # 拆分为K和V,形状均为 [b, c, h, w]
# 2. 生成输入特征x的查询(Q)
q = self.q(x) # [b, c, h, w] -> [b, c, h, w]
q = self.q_dwconv(q) # 深度可分离卷积提取空间特征
# 3. 调整维度:从通道优先转为序列格式,并分割多头
# - K/V形状:[b, c, h, w] -> [b, head, c/head, h*w]
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
# - Q形状:[b, c, h, w] -> [b, head, c/head, h*w]
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
# 4. 归一化查询和键(L2归一化,增强稳定性)
q = torch.nn.functional.normalize(q, dim=-1) # 对序列维度归一化
k = torch.nn.functional.normalize(k, dim=-1)
# 5. 计算交叉注意力矩阵
attn = (q @ k.transpose(-2, -1)) * self.temperature # 点积×温度参数
attn = attn.softmax(dim=-1) # 归一化为概率分布
# 6. 通过注意力矩阵聚合值(V)
out = (attn @ v) # [b, head, c/head, h*w] × [b, head, c/head, h*w] -> [b, head, c/head, h*w]
# 7. 调整维度并投影回原始格式
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w) # 合并多头
out = self.project_out(out) # 投影回dim通道
out = out.permute(0, 2, 3, 1) # 转为通道最后格式 [b, h, w, c]
return out
作用:
自注意力(IG_MSA):建模输入特征 x 的全局依赖关系。
交叉注意力(Cross_attention):建模输入特征 x 与条件信号 s 的交互关系。
前馈网络(FeedForward):引入非线性变换,增强特征表达能力。
这种网络结构具有如下特点:
- 捕获多尺度特征
- 整合条件信号(如本文的结构信息先验)
- 通过注意力机制聚焦关键区域
- 高效地进行特征复用和传播
需要注意的是,本文作者所述的提取稳定结构先验的代码暂未开源,后续开源之后将做进一步解读。
3、总结
代码实现核心的部分讲解完毕,总体来看该代码结合了Retinexformer代码的思想,但是相较于Retinexformer采用了更加精细的特征提取策略。该文章也在NTIRE 2025低照度图像增强中取得了第二名的成绩。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









