







为什么要做这个东西呢?
爬虫也写了不少了,因为比较懒,所以一直以来,都想要有一个这样的爬虫:
- 只需要用户提供url
- 只需要用户提供目标数据的样本
剩下的工作(多线程并发,容错,重联,隐藏,分布式。。。)由爬虫自己完成,相当于给爬虫一个方向,剩下的事情就是喝茶了。换句话来说,具有高度模块化的特点,无需复杂的定制。想了一下,工作量有些庞大,所以就先从简单的小的模块做起吧,先定一个小目标,比如做它一个线程池。
一个线程池,有什么呢?
- 一堆工作线程
- 一个(或几个?)调度线程
- 一个(或几个?)监测线程
- 任务队列
- 结果队列
有点抽象,那就换个说法:
一个工厂,有什么呢?
- 很多工人
- 一个或几个厂长(副厂长),负责工人的工作的安排,监测员工状态,以及员工的开除与招聘
- 一个或几个质检员,检测产品的质量
- 原料(任务)流水线
- 产品(结果)流水线
大概能想到的就这些,剩下的边写边想。先画个图,更加直观清晰
初始模型
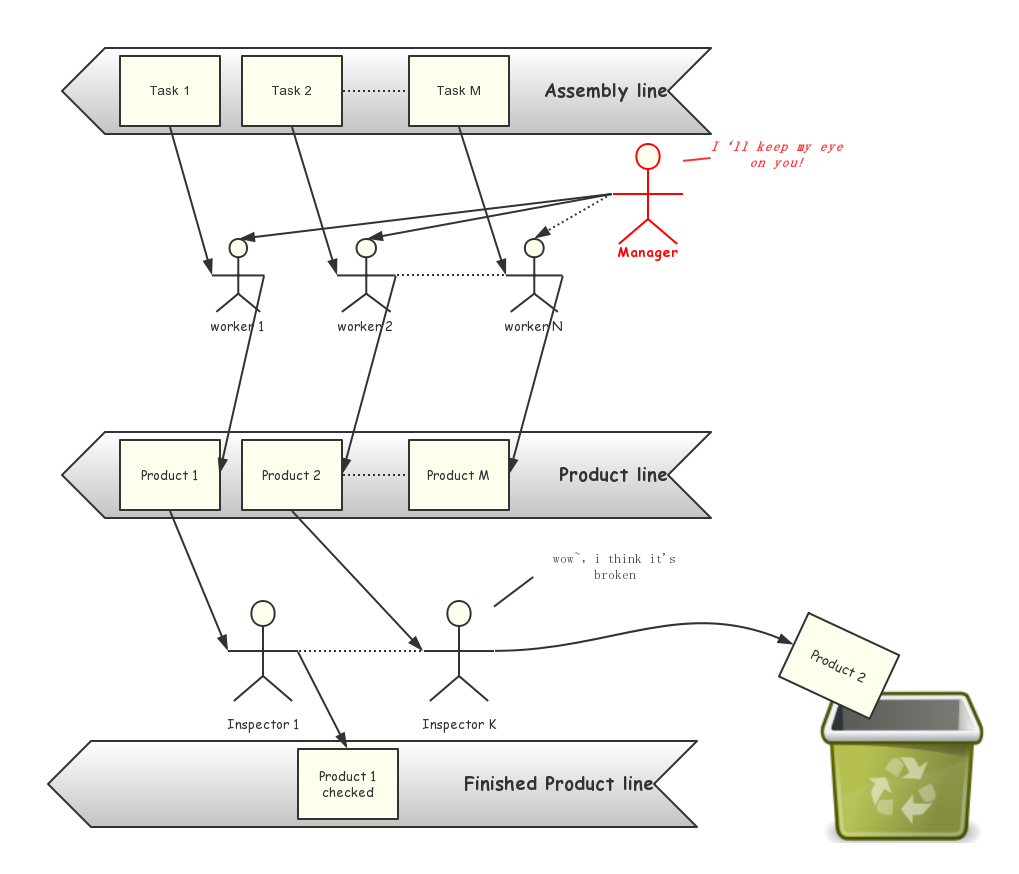
现在回顾一下我们上面的模型,可以看到,对一个任务,我们经过工人的加工后形成产品,在经过质检员的检查,确认无误后,最后送到成品队列上。工人接受经理的监管,经理同时负责工人的招聘与解雇,对失败的产品,将其丢弃。
第一轮的设计基本结束,现在再回过来从头到尾过一下,我们可以发现这个模型不完备的几点:
- Task从哪儿来,并没有指明task的来源与形式
- 工人干什么,怎么样对原料(task)加工形成产品?
- 对失败的产品,如何检测?
- 只要失败,就将其丢弃,这样是否合理?如果任务要求必须全部完成呢?
对上面的疑问,我们一个一个来解决:
Q1:Task从哪儿来?
在现实生活中,工厂的订单就是它的task,往往是以客户部的形式存在,不断的接订单,再部署到工厂的流水线上,所以我们需要一个类似客户部的存在,来生成taskQ2:工人干什么?怎么样把原料变成产品
如果我们简单的认为工人就是生产者,那么对工厂的生产关系的模块化定制就不够了,在现代生产中,机器才是第一生产者,工人通过操作机器完成产品的生产,在生产方式变化时,工人只需要学习新机器的使用,真正的生产方法由机器实现。所以,我们需要一个类似机器的存在,来真正完成task到product的过程,机器由工人驱动。Q3:对失败的产品,如何检测?
在Q2中,我们添加了机器这一角色,自然产品的检测可以由机器完成,换句话说,生产员和质检员都可以抽象成“工人”+“机器”的集合Q4:“只要失败就丢弃”是否合理?
在一定状况下,是可以的,例如在登录成功率的测试上。当然我们也可以加入一个垃圾回收机制,对失败的任务进行回收。考虑到成本,对一个task的回收次数要设置一个上限
针对我们的需求,进行第一轮原型迭代

原型建立完成,现在可以开始分割模块了,根据我们上面的图(从上至下),我们的线程池,或者说线程工厂可以分成一下几个模块:
- 任务生成器(taskprouducer)
- 工人线程(workerthread)
- 机器实例(machine) //在我们的爬虫中对应spyder
- 经理(taskmanager) //在我们的爬虫中对应threadfactory
- 质检员线程(inspector) //在我们的爬虫中对应resultprocessor
- 废品回收器(garbagecollector) //写代码的时候命名为了junkcollector,懒得改了
- 垃圾箱(trashcan)
- 配置文件(config) //第一版用的ini做配置文件,后来改成了py文件
- 任务队列(taskqueue)
- 产品队列(productqueue) //在我们的代码里面写成了resultqueue
- 成品队列(Finished Product Queue)//在我们的代码里面和产品合为一个队列(因为工人和质检员在同一个生产车间)
- 垃圾队列(garbagequeue) //junkqueue,原因同上
下面就是针对各个模块进行功能分类和coding了,以我们的爬虫线程池为例。
任务生成器(taskproducer)
功能:
从配置文件中读取参数信息,生成task,并将task放入taskqueue,根据我们之前的模型,生成器应该是主线程的一个守护线程。
# coding=utf8
# author=PlatinumGod
# created on
import threading
import UrlIterator
import urlparse
import spyder
import logging
import Queue
import config
import ConfigParser
class taskProducer(threading.Thread):
"""
任务生成器,从配置文件中读取数据,并不断的向任务队列中添加任务
"""
def __init__(self, taskqueue):
"""
:param taskqueue:任务队列
:param inipath: 配置文件路径
"""
super(taskProducer, self).__init__()
self.setDaemon(True)
self.taskqueue = taskqueue
self.base = []
for target in config.targets:
self.base.append(
(target['baseurl'],
target['firstpattern'],
target['secondpattern'],
target['iterator'],
target['fpstrict'],
target['spstrict'])
)
# print self.base
self.start()
def getbool(self, str):
if str == 'True':
return True
else:
return False
def run(self):
# 配置文件中的每个section对应一个task迭代器,依次
# 轮询迭代器,将task放入taskqueue
generators = []
for item in self.base:
generators.append(self.task(item))
while True:
for generator in generators:
try:
item = generator.next()
except:
break
targeturls = item[0]
pattern = item[1]
strict = item[2]
for targeturl in targeturls:
task = {
'func': spyder.getinfo,
'args': {
'url': targeturl,
'pattern': pattern,
'strict': strict},
'callback': spyder.infocheck}
self.taskqueue.put(task)
def _urliterator(self, baseurl, maxnum=100):
for i in xrange(1, maxnum):
yield urlparse.urljoin(baseurl, str(i))
def urliterator(self, flag, baseurl):
# url迭代器,通过一个种子url生成许多url
# 如果没有自己写的url迭代器,则调用默认自带的迭代器
if not flag:
return self._urliterator(baseurl)
else:
return UrlIterator.myurliterator(baseurl)
def task(self, base):
# 通过一个section(即参数base),生成一个任务迭代器
baseurl = base[0]
targeturl = base[1]
pattern = base[2]
flag = base[3]
fpstrict = base[4]
spstrict = base[5]
urls = self.urliterator(flag, baseurl)
for url in urls:
try:
targeturls = spyder.getfinfo(
{'url': url, 'pattern': targeturl, 'strict': fpstrict})
except:
logging.error("Unable to get " + url)
continue
yield targeturls, pattern, spstrict
if __name__ == '__main__':
a = Queue.Queue()
tp = taskProducer(a)
tp.join()
因为暂时还没有写道自动生成url的功能,所有先自建一个urliterator凑合着用。
工人线程
我们可以将质检员和生产员抽象成“工人”+“机器”
功能:
从任务队列获取任务,利用“机器(machine)“生产,将完成的产品放入产品队列,失败的任务放入垃圾回收队列。
# coding=utf-8
# author=PlatinumGod
# created on 2016/9/18
import threading
import logging
class worker(threading.Thread):
"""
工作线程,继承threading.Thread类并重写其run方法
从任务队列中取出任务,并将结果放入结果队列,对未完成的任务,将其放入垃圾回收队列
"""
def __init__(self, taskqueue, resultqueue, junkqueue, threadname):
"""
:param taskqueue:任务队列
:param resultqueue: 结果队列
:param junkqueue: 垃圾回收队列
:param threadname: 线程名
"""
super(worker, self).__init__()
self.setDaemon(True) # 设置为守护线程
self.taskqueue = taskqueue
self.resultqueue = resultqueue
self.junkqueue = junkqueue
self.name = threadname
self.start()
def run(self):
while True:
try:
# 从taskqueue取任务
task = self.taskqueue.get()
func = task.get('func')
args = task.get('args')
callback = task.get('callback')
if callback:
result = callback(func(args))
flag = result[1]
# 任务执行失败,任务放入垃圾回收队列
if flag == 0:
logging.debug("Catch a junk result! --" + result[0])
self.junkqueue.put(result[0])
# 任务执行成功,结果放入结果队列
elif flag == 1:
logging.info("Put result to resultqueue!")
self.resultqueue.put(result[0])
# 出现未解决错误,记录任务
else:
logging.error(
"Unhandled error happend while processing " + result[0])
# 线程死亡
else:
print "No callback, please check your taskProducer!"
raise RuntimeError
except:
continue
if __name__ == "__main__":
pass
可以看到,这里的生产员和质检员的机器分别对应代码里的’func‘和‘callback’。
机器实例(machine)
功能:
封装生产过程(爬取),结果检测过程,为worker提供接口
# coding=utf8
# author=PlatinumGod
# created on 2016/9/18
import requests
import re
import logging
import urlparse
"""
这是worker线程实际工作的函数库
"""
# http请求头伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
# 获取目标网页,并利用正则匹配出相应信息
def getfinfo(kwrgs):
url = kwrgs['url']
pattern = kwrgs['pattern']
strict = kwrgs['strict']
try:
logging.info("Start Getting " + url)
html = requests.get(url, timeout=10, headers=headers).content
except:
logging.error("Failed to Get " + url)
return kwrgs
if strict:
regex = re.compile(pattern)
else:
regex = re.compile(pattern, re.S)
infolist = regex.findall(html)
return infolist
def getinfo(kwrgs):
url = kwrgs['url']
pattern = kwrgs['pattern']
strict = kwrgs['strict']
try:
logging.info("Start Getting " + url)
html = requests.get(url, timeout=10, headers=headers).content
except:
logging.error("Failed to Get " + url)
return kwrgs
if strict:
regex = re.compile(pattern)
else:
regex = re.compile(pattern, re.S)
infolist = regex.findall(html)
title = ''.join(infolist[0])
dict = []
if len(infolist) > 1:
for i in range(1, len(infolist)):
dict.append(infolist[i][1] + ':' + infolist[i][2])
x = len(dict)
line = '\t'.join(dict)
dirname = urlparse.urlsplit(url).hostname
return dirname, str(x)+'-'+title, line
# 检查信息是否有效,合法
def infocheck(infomation):
if isinstance(infomation, dict):
return infomation, 0
elif isinstance(infomation, tuple):
return infomation, 1
return infomation, 2
经理(TaskManager)
功能:
负责工人线程的调度与执行,工人线程状态的检测,新线程的添加和死线程的删除,线程池状态的汇报,
# coding=utf8
# author=PlatinumGod
# created on 2016/9/18
import worker
class threadfactory:
"""
线程工厂,为worker线程指配任务,维护线程池,维护垃圾回收队列
"""
def __init__(self, taskqueue, resultqueue, junkqueue, workernum):
"""
:param taskqueue: 任务队列,worker从中取出工作任务
:param resultqueue: 结果队列,worker将任务结果放入
:param junkqueue: 垃圾回收队列,对于因为异常而未被成功处理的task,将其放入
:param workernum: worker线程数量
"""
self.taskqueue = taskqueue
self.resultqueue = resultqueue
self.junkqueue = junkqueue
self.threadnum = workernum
self.threadpool = [] # 线程池
self.start()
def start(self):
"""
启动线程池中所有的worker线程
"""
for i in range(self.threadnum):
self.threadpool.append(
worker.worker(
self.taskqueue,
self.resultqueue,
self.junkqueue,
'worker-' +
str(i)))
def addthread(self, taskqueue, resultqueue, junkqueue, threadname):
"""
向线程池中添加一个线程
"""
self.threadpool.append(
worker.worker(
taskqueue,
resultqueue,
junkqueue,
threadname))
def deletethread(self, threadname):
"""
删除一个线程池中的线程
"""
for i in range(len(self.threadpool)):
if self.threadpool[i].name == threadname:
self.threadpool.pop(i)
print "Delete ", threadname
def status(self):
"""
返回线程池状态函数
"""
return self._checkstatus()
def refresh(self):
"""
监测线程池中的线程状态,若线程死亡,则将其移出线程池,再向线程池中添加新的线程
"""
for thread in self.threadpool:
if thread.isAlive():
continue
else:
threadname = thread.name
self.threadpool.remove(thread)
self.threadpool.append(
worker.worker(
self.taskqueue,
self.resultqueue,
self.junkqueue,
threadname))
def _checkstatus(self):
"""
返回线程池状态
"""
worknum = 0
for i in range(self.threadnum):
if self.threadpool[i].isAlive():
worknum += 1
else:
continue
if worknum <= self.threadnum / 2:
self.refresh()
return (
# "=============================================================\n"
"worker线程活动数:%d\t"
"任务队列长度:%d\t结果队列长度:%d\t"
# "=============================================================\n" %
% (worknum, self.taskqueue.qsize(), self.resultqueue.qsize()))
if __name__ == "__main__":
pass
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









