






1.PySpark介绍
PySpark 是 Apache Spark 的 Python API,它结合了 Python 的简洁语法和 Spark 强大的分布式计算能力,广泛应用于大规模数据处理、机器学习、实时数据流分析和图计算等场景。通过 DataFrame、RDD 和 Dataset 等丰富的数据处理接口,PySpark 支持高效的数据操作和分析,并且能够无缝集成 Hadoop、Hive、Kafka 等大数据生态系统。它基于 Spark 的分布式架构,具备高性能和可扩展性,同时借助活跃的社区支持和丰富的文档,PySpark 为数据工程师和科学家提供了一个易用且功能强大的工具,适用于从数据探索到模型训练的多种任务,是处理海量数据的核心选择。
2. 环境准备
2.1 安装Miniconda/Anaconda
-
Miniconda:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
-
Anaconda:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
说明:Miniconda 是 Anaconda 的轻量级版本,仅包含 Python 和 Conda 管理工具,不预装其他包,因此占用空间小且灵活性高,适合对磁盘空间有限制或需要高度定制环境的用户;而 Anaconda 是一个完整的 Python 发行版,预装了大量科学计算和数据分析相关的包,安装文件较大,但适合初学者或需要快速搭建完整开发环境的用户,能够节省大量安装和配置时间。
2.2安装步骤
2.2.1以安装Anaconda为例:
-
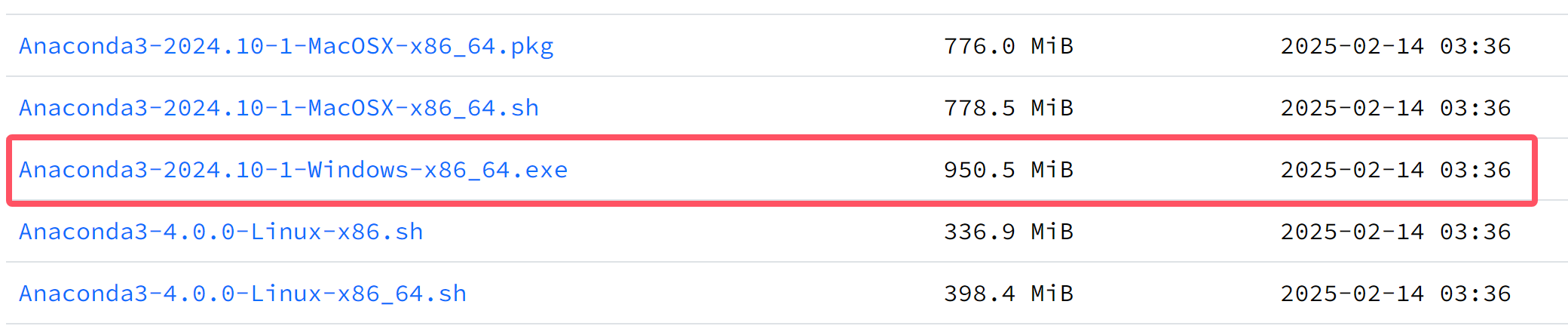
访问清华镜像源,并下载
Anaconda3-2024.10-1-Windows-x86_64.exe
-
下载完成后,根据安装向导完成安装
-
建议勾选
Add to PATH选项 -
完成安装后验证:
conda --version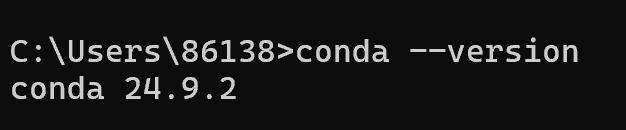
-
注意:如果没有显示conda的版本,则需检查环境变量是否配置。
2.3配置镜像源
2.3.1conda清华镜像配置
# 添加主渠道清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
# 添加conda-forge清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
# 设置显示频道URL
conda config --set show_channel_urls yes
2.3.2 验证配置
conda config --show channels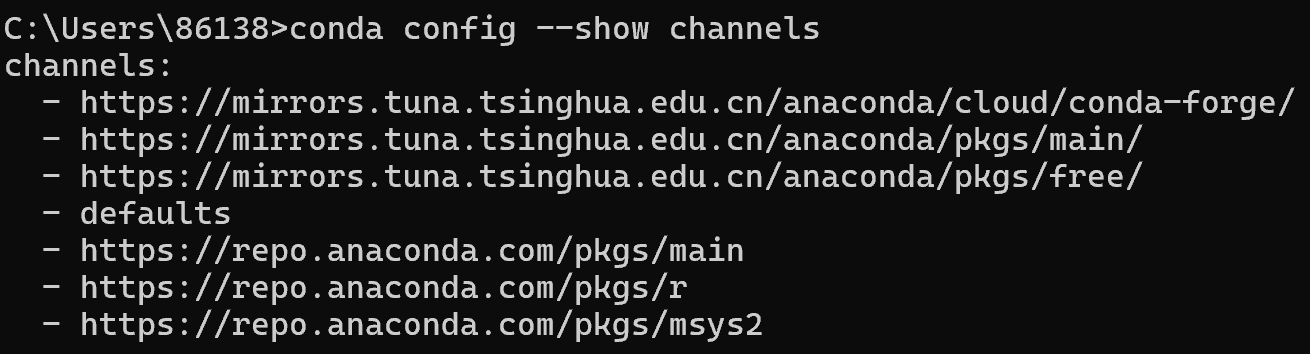
2.3.3恢复默认源:
conda config --remove-key channels3. Conda环境管理
3.1 创建PySpark环境
conda create --name pyspark_env python=3.8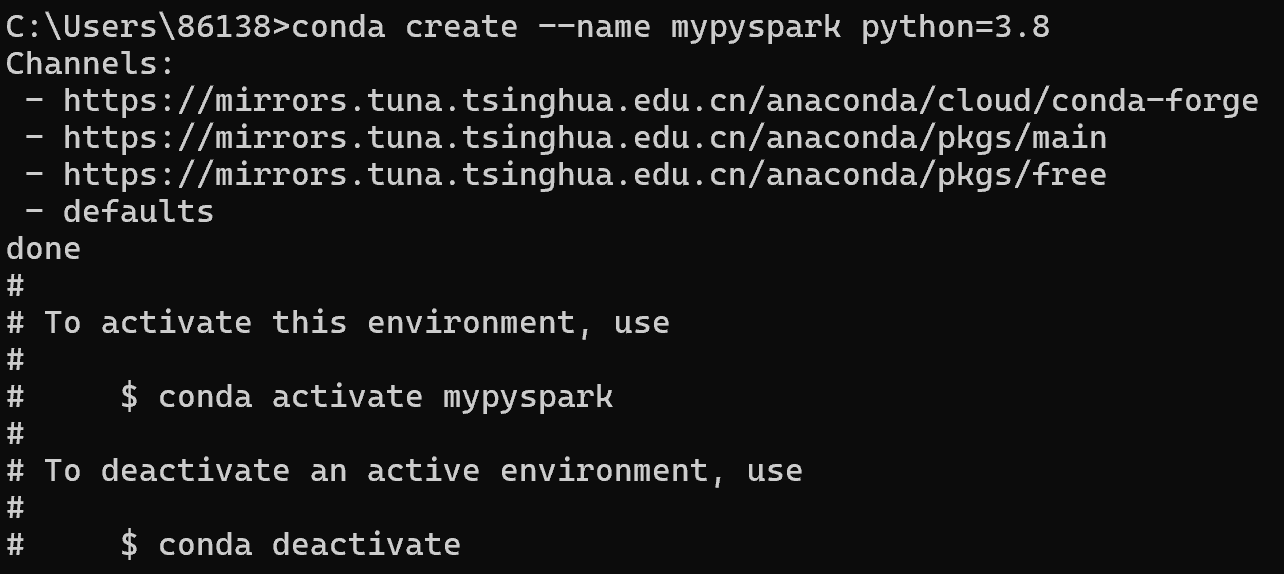
3.2列出所有环境:
conda env list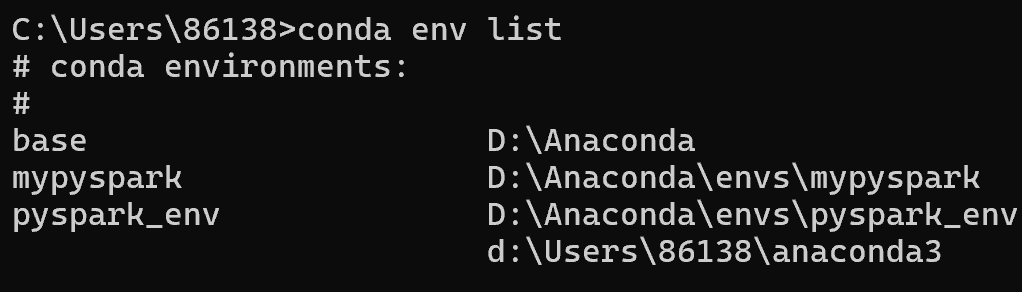
3.3激活环境:
conda activate mypyspark
3.4退出当前环境:
conda deactivate3.5删除环境:
conda env remove --name mypyspark4. PySpark安装
4.1 安装PySpark
pip install pyspark==3.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple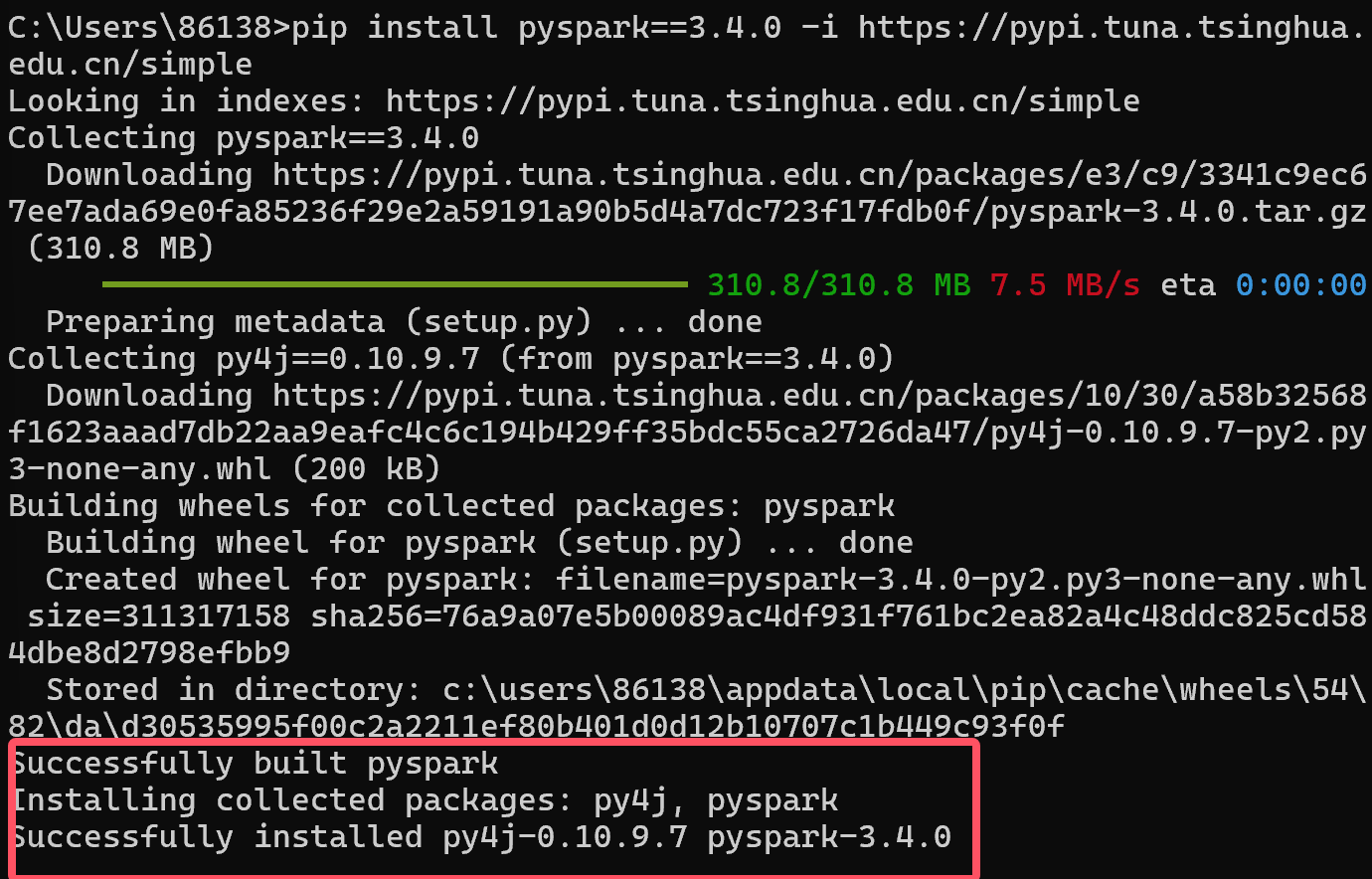
4.2 验证安装
-
安装pyspark库
pip install pyspark -
验证安装


5. PySpark应用开发
5.1 创建PyCharm工程
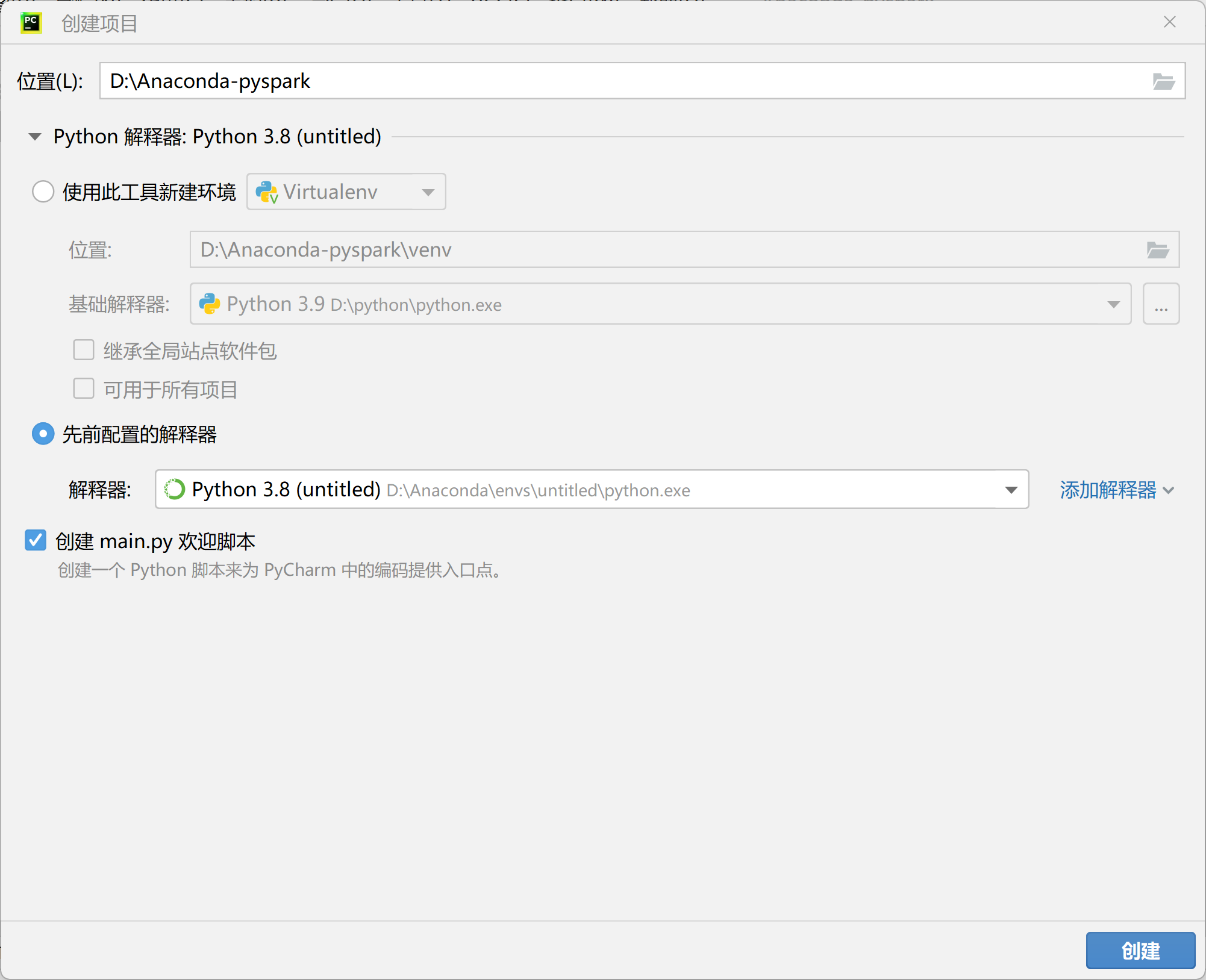
5.2 准备测试数据
-
创建
words.txt:

5.3 WordCount示例代码
-
使用
conda env list查找 pyspark_env 的路径
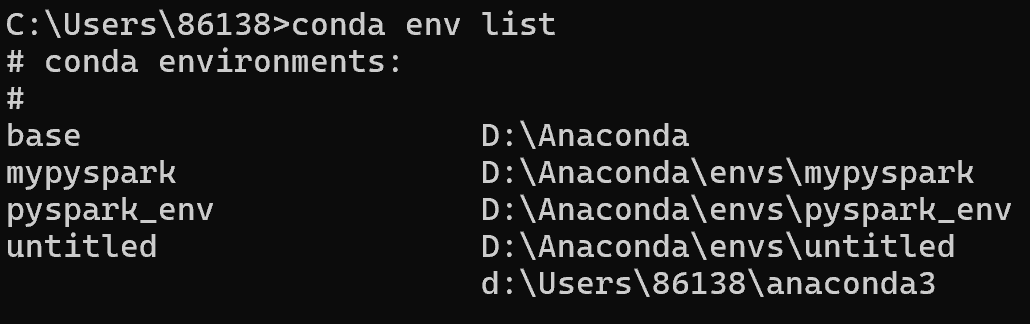
-
词频统计代码
from pyspark import SparkConf, SparkContext
import os
# 配置Python解释器路径(根据实际路径修改)
os.environ['PYSPARK_PYTHON'] = r"D:\Anaconda\envs\pyspark_env\python.exe"
# 初始化Spark上下文
conf = SparkConf().setAppName("WordCount").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 获取当前工作目录
cwd = os.getcwd()
# 文件路径处理
input_file = "file:///" + os.path.join(cwd, "words.txt")
# WordCount计算流程
word_counts = (
sc.textFile(input_file)
.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
.collect()
)
# 打印结果
print("Word Count Results:")
for (word, count) in word_counts:
print(f"{word}: {count}")
# 停止Spark上下文
sc.stop()5.4 运行程序
查看运行结果
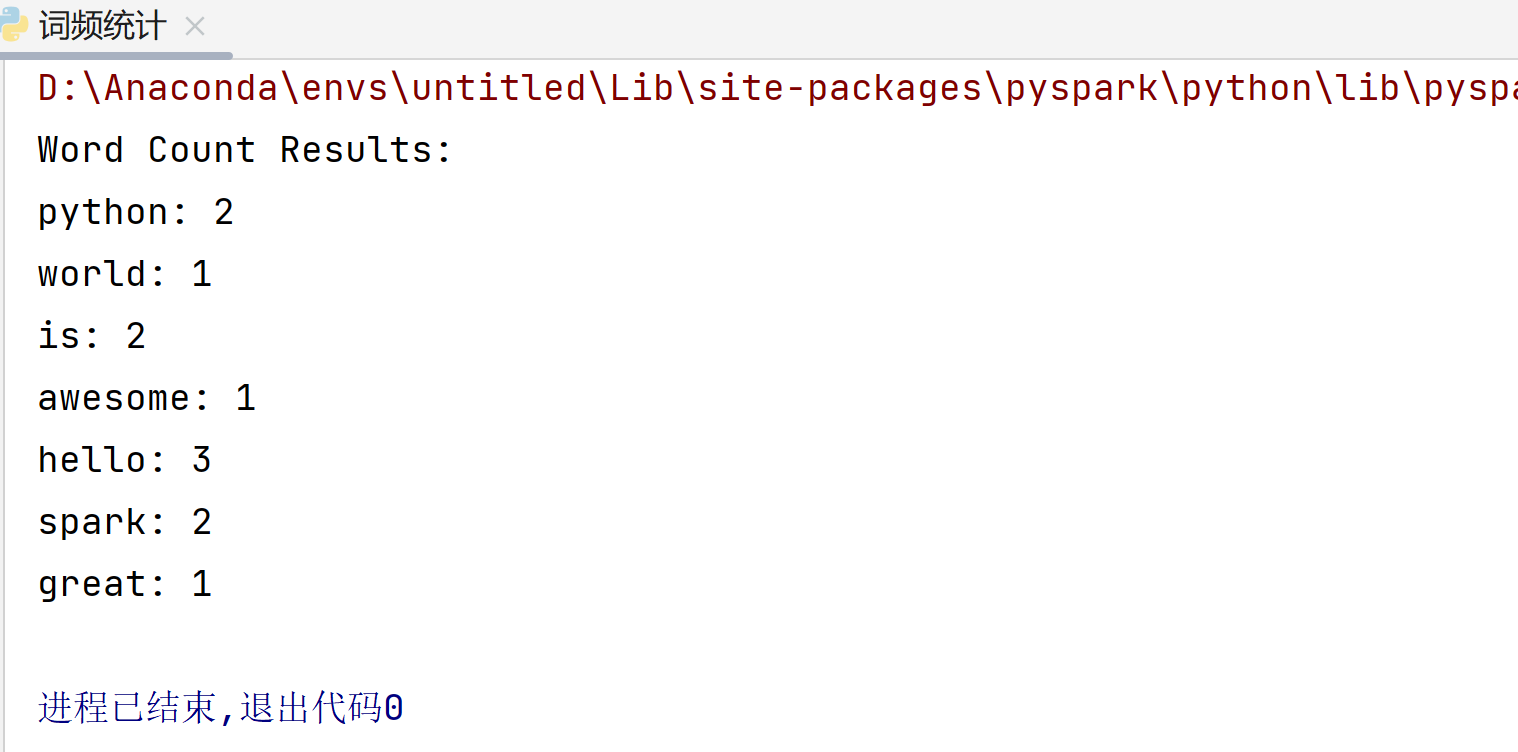


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









