文章目录 LSTM代码 双向LSTM,需要修改哪几个参数? LSTM代码 import numpy as np import matplotlib.pyplot as plt import torch import torch.nn as nn import torch.optim as optim import torch<








 超级会员免费看
超级会员免费看
 本文介绍了如何在PyTorch中使用双向LSTM进行时间序列分类,并详细说明了如何修改参数以适应双向结构,包括隐藏层状态的初始化和全连接层输入特征数的调整。
本文介绍了如何在PyTorch中使用双向LSTM进行时间序列分类,并详细说明了如何修改参数以适应双向结构,包括隐藏层状态的初始化和全连接层输入特征数的调整。
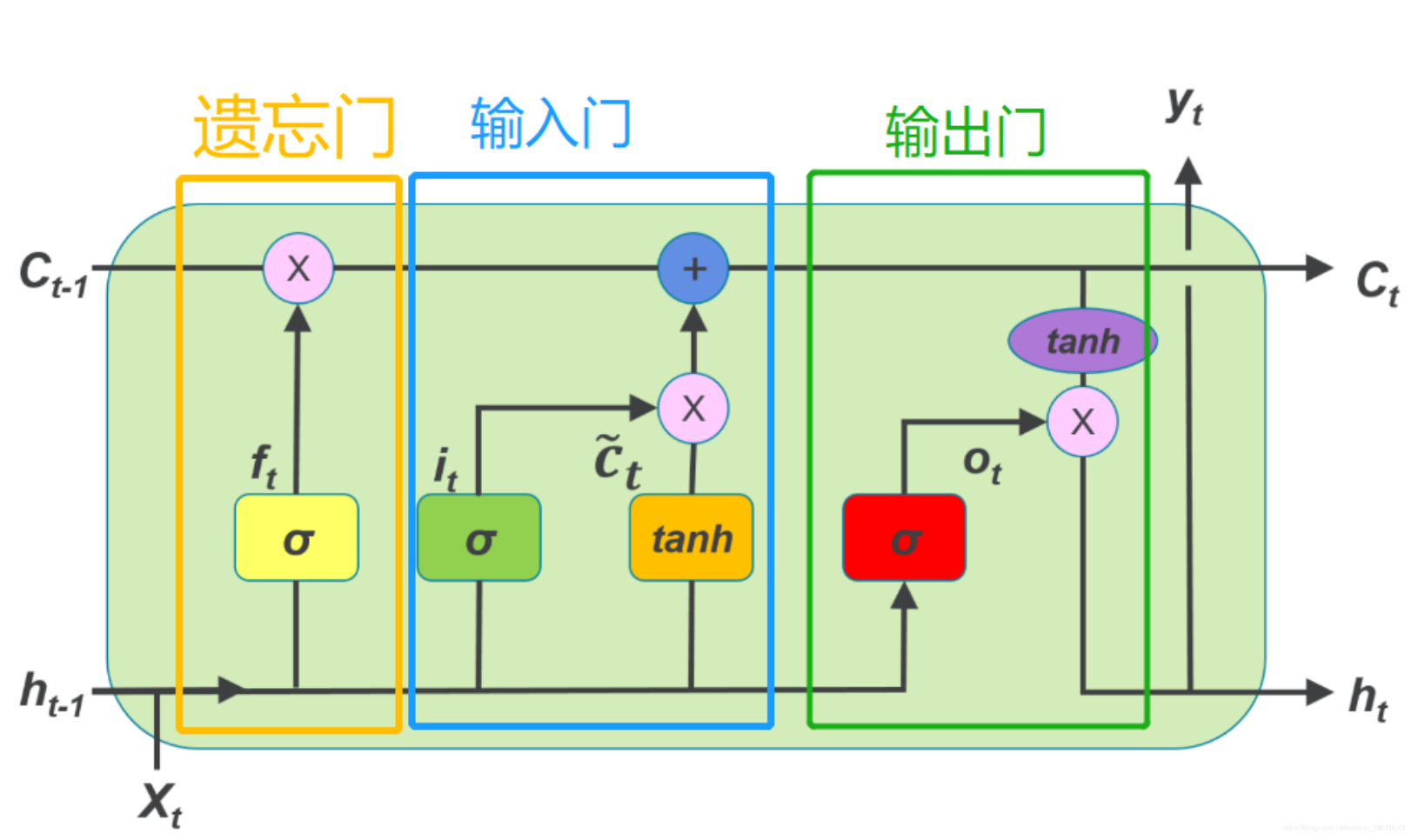

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








