







前言
在2024年年底的时候,AI圈里流传着一种说法:“Scaling Law is hitting a wall”。作为一名AI小白,笔者不禁好奇,这个神奇的Scaling Law究竟是什么?为什么有人认为它会“撞墙”?它似乎是推动AI发展的核心动力,但这种动力是否真的在减弱?
Scaling Law,简单来说,它描述了模型性能如何随着模型规模、数据量和计算资源的增加而提升。它曾被认为是AI进步的“魔法公式”,但随着模型越来越大,训练成本越来越高,有人开始怀疑它的可持续性。

然而,最近发布的Claude 3.7和Grok 3(本文将以Grok 3为主进行讲解)却给出了不同的答案。这些新模型的出色表现有力地证明,至少在目前,我们还没有真正“撞墙”。
这篇文章的目标很简单:为像我一样的初学者揭开Scaling Law的面纱,解释它是什么、为什么重要,以及Grok 3如何证明它还未走到尽头。让我们一起走进这个AI世界的核心法则,探索它的魔力与争议。
Scaling Law是什么?
Scaling Law在AI中,尤其是深度学习中,是经验性观察,描述了机器学习模型性能如何随着关键因素的缩放而变化。这些因素包括:
- 模型大小:模型中的参数数量。
- 训练数据集大小:用于训练模型的数据量。
- 训练成本(计算资源):训练过程中使用的计算能力。
这可以类比为学习一门语言:更多的词汇(数据)、更强的记忆力(模型大小)和更多练习时间(计算资源)会让你更流利。而Scaling Law表明,这些因素与模型性能之间存在可预测的关系,通常遵循幂律关系。
幂律关系
In machine learning, a neural scaling law is an empirical scaling law that describes how neural network performance changes as key factors are scaled up or down. These factors typically include the number of parameters, training dataset size, and training cost.
简单来讲,就是一个
y
=
a
x
k
y = a x^k
y=axk 函数,没有什么新奇的地方,而这样一个函数,就是Scaling Law的本质。
像下图说明了在AI模型训练和测试中,计算资源(如FLOPs)与模型性能之间的关系。更多的计算资源通常能带来更高的准确率,这对于理解有效利用计算资源来优化AI模型的性能具有重要意义。

图片来源: Ethan Mollick
两张图横轴都表示训练时的计算量(以对数尺度显示),单位是FLOPs(浮点运算次数)。纵轴表示在训练过程中模型的准确率(pass@1 accuracy),即模型在训练数据上达到正确答案的比例。左侧图表示训练时的 Scaling Law 随着训练时计算量的增加,模型的准确率也相应提高。这表明更大的计算资源投入可以带来更好的训练效果。右侧图与左侧图表类似,测试时的准确率也随着计算量的增加而提高。意味着进一步增加计算资源可能会继续提升模型的测试表现。
Scaling Law的重要性
More compute, More training data and More parameters makes a Better AI model.
在深度学习中,较大的模型(更多参数)能学习更复杂的模式。更多的训练数据提供了更丰富、多样的学习示例,有助于模型更好地泛化。增加计算资源允许更深入、更长时间的训练,帮助模型找到更好的解决方案。
例如,在大型语言模型(LLM)中,增加参数数量和训练数据量显著提升了它们生成连贯、上下文相关文本的能力。
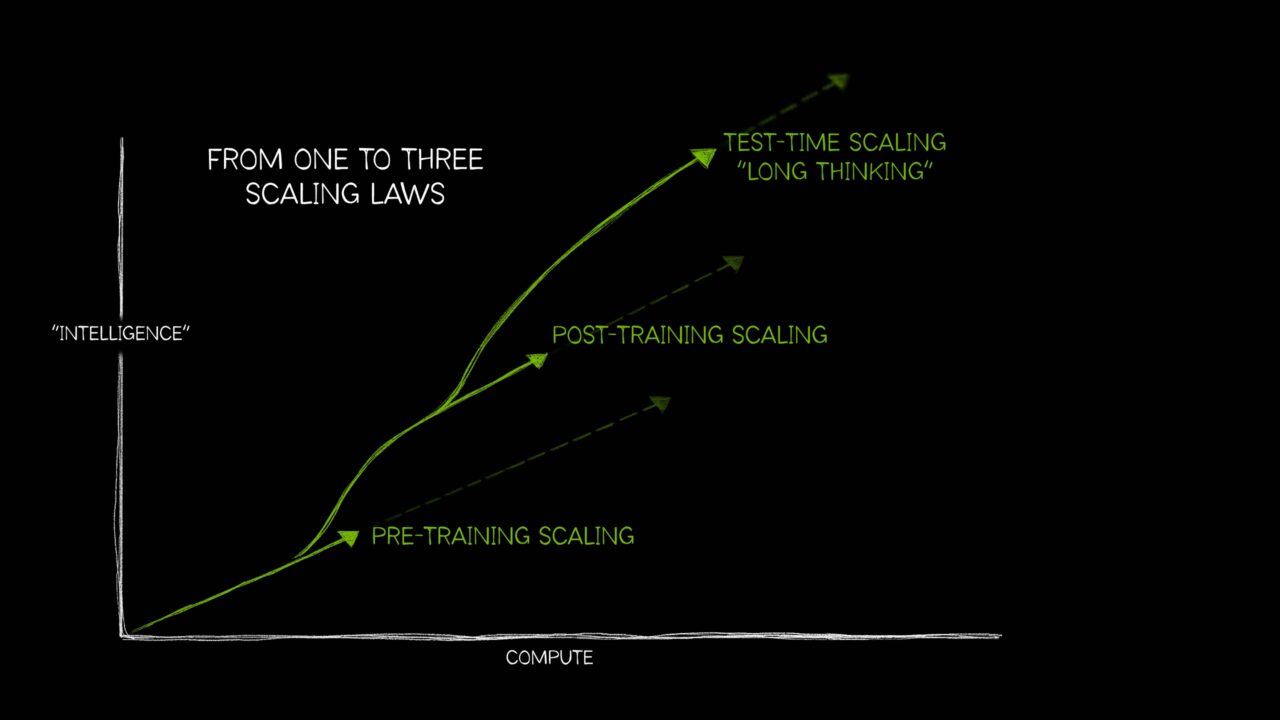
图片来源:NVIDIA博客:Scaling Law如何推动更智能、更强大的AI
Scaling Law 不仅揭示了AI模型性能提升的规律,还为研究人员和企业提供了科学的指导,帮助他们高效地分配资源,设计更强大的模型。简单来说,Scaling Law是AI世界的“指南针”,告诉我们如何通过增加模型大小、数据量和计算资源来实现更好的结果。
-
Scaling Law 提供了一个可预测的框架。它描述了模型性能一般会遵循幂律关系随着训练数据量、模型参数数量和计算资源的增加而改善。这意味着,开发者可以提前估算出增大模型规模或投入更多计算资源的回报。例如,当更大的模型被喂以更多数据时,性能会显著提升,而这需要强大的加速计算资源来支持训练过程。这种可预测性让企业能够更有信心地投资于大规模AI项目,避免资源浪费。
-
Scaling Law 推动了AI能力的突破性进展。Pretraining Scaling Law(预训练扩展法则)催生了拥有数十亿甚至万亿参数的transformer models(变换器模型)。这些模型在自然语言处理、图像生成和多模态任务中取得了前所未有的成功。例如,像Grok 3这样的模型,正是通过遵循 Scaling Law,利用更多计算能力和数据,达到了超越前代的表现(这个在后文会提到)。这种突破不仅提升了AI的实用性,还拓展了它在医疗、金融、自动驾驶等领域的应用可能性。
-
Scaling Law 还催生了多样化的AI技术生态。除了预训练阶段,Scaling Law 还包括post-training(后训练)和test-time scaling(测试时扩展),这些方法进一步增强了模型的灵活性和针对性。比如,通过 post-training 技术,一个预训练模型可以被微调为特定任务(如情感分析或医学诊断),从而更高效地服务于特定行业。这些技术的发展表明,Scaling Law不仅是“更大更好”的简单逻辑,而是为AI的多场景应用提供了系统性支持。
-
Scaling Law 对AI基础设施的需求提出了明确要求。NVIDIA指出,无论是预训练阶段的巨大模型,还是推理阶段的复杂问题解决,都需要更多的计算能力来支撑。这直接推动了加速计算硬件(如NVIDIA的GPU)的创新和普及,为AI的广泛部署奠定了基础。例如,企业需要扩展其计算资源,以支持下一代AI推理工具,这些工具能在编码、多步骤规划等复杂任务中表现出色。可以说,扩展法则是连接AI理论与现实应用的桥梁。
挑战与未来方向
虽然Scaling Law在推动AI进步方面非常成功,但也存在挑战和局限:
- 收益递减:随着模型变大,每单位增加的大小、数据或计算资源的性能提升可能会减少。
- 计算成本:训练超大型模型需要大量计算能力,这既昂贵又耗能。
- 数据质量和多样性:仅仅拥有更多数据并不总是有益,数据的质量和多样性也很关键。
鉴于这些挑战,研究人员正在探索超越传统Scaling Law的新方法,包括:
- 测试时计算:在推理时使用更多计算资源来提升性能。
- 更好的模型架构:开发更高效、有效的模型设计,以更少资源实现更高性能。
- 迁移学习和微调:利用预训练模型,并通过较少数据和计算资源适配特定任务。
Grok3
笔者选择Grok3为说明是因为作为免费AI,笔者主观判断上,使用Grok3的感觉确实比GPT-4o,DeepSeek-R1要流畅,推理部分也很舒服
Grok3由xAI开发,是Scaling Law应用的一个典型例子。xAI声称,Grok3的训练使用了比其前身Grok2约10倍的计算能力,并包括扩展的训练集,涵盖了更广泛的数据,如法庭案件文件。
xAI宣称Grok3在各种基准测试中优于其他领先的AI模型,这进一步支持了Scaling Law的有效性。
Grok3如何维持Scaling Law
Grok3的开发
Grok3 由 xAI 于2025年2月发布,据称是迄今为止最先进的模型,融合了卓越的推理能力和广泛的预训练知识。根据xAI博客,Grok3的训练使用了约10倍于Grok2的计算能力,涉及200,000个Nvidia H100 GPU,并包括扩展的训练集,涵盖法庭案件文件等数据。
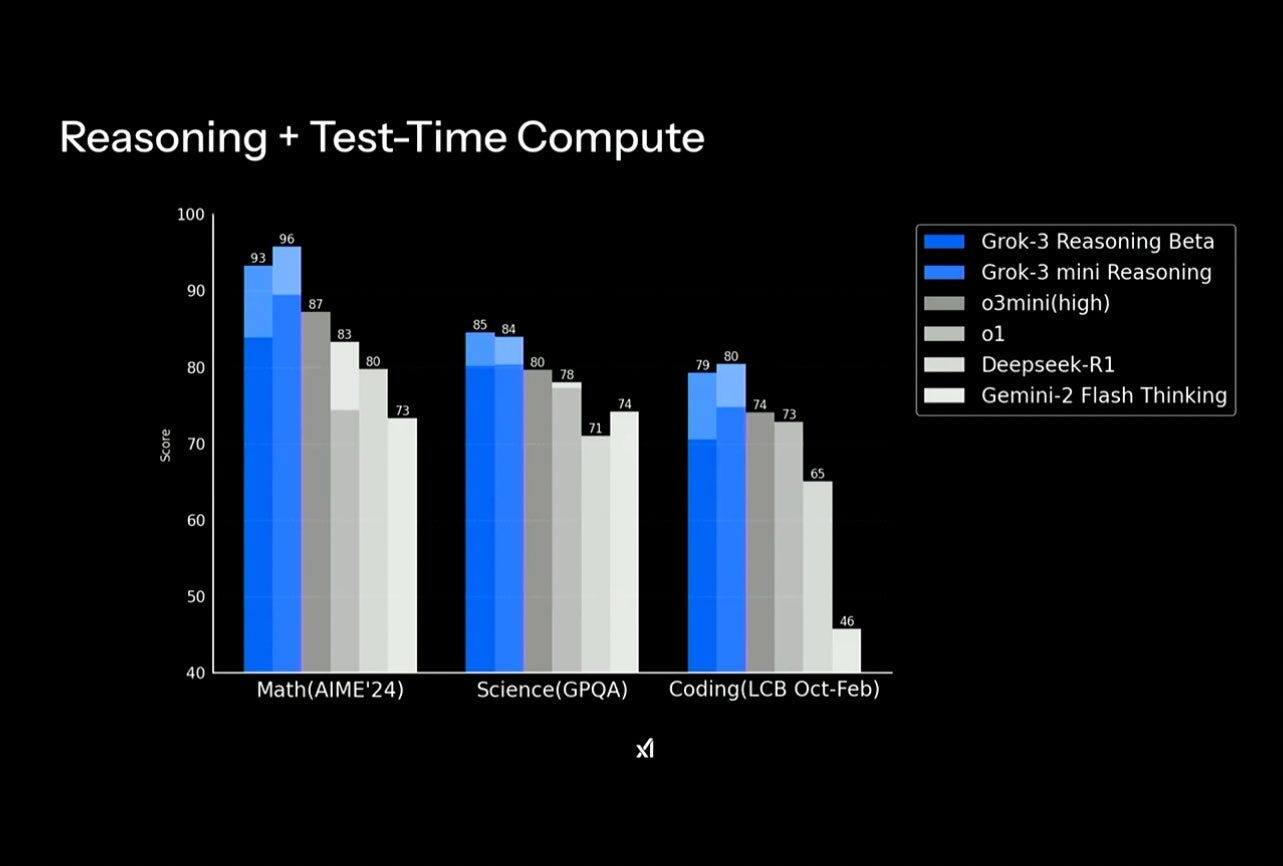
这种显著增加的计算能力和数据量与Scaling Law直接吻合,预测较大模型在更多数据上的训练将表现出更好的性能。xAI声称Grok3在学术基准和现实用户偏好上表现领先,达到Chatbot Arena的Elo得分1402,优于如GPT-4o和DeepSeek-V3的竞争对手。同时,TechCrunch报道,Grok3在数学、科学和编码基准上击败了OpenAI的GPT-4o和Alphabet的Gemini。
Grok3和Scaling Law
Grok3通过遵循传统Scaling Law的策略维持了这些法则:
- 计算规模化:使用200,000个GPU的超级计算机训练,显著增加了计算资源,符合Scaling Law的预测。
- 数据扩展:包括法庭案件文件在内的扩展训练集,提供了更丰富的数据来源,增强了模型的泛化能力。
- 性能提升:据称的基准测试表现优于前代和竞争对手,验证了规模化带来的性能改进。
然而,争议在于是否所有观察都支持Scaling Law。例如,Hixx.ai博客提到,Grok3的发布延迟可能反映了Scaling Law收益递减的迹象,埃隆·马斯克在采访中表达了不确定性,暗示可能需要新的技术突破。
尽管如此,Grok3的成功案例(如彭博社报道的基准测试结果)表明,Scaling Law在某些情况下仍有效,尤其对于xAI的模型。
Scaling Law 到达极限的影响
说到底,为什么这么多人都害怕 Scaling Law 失效呢?
-
性能提升变慢(收益递减)
当到达极限时,每增加一倍的模型参数、数据或计算资源带来的性能提升会显著减少。例如,一个模型从10亿参数扩展到100亿参数时可能大幅提高能力,但从1000亿到2000亿参数时,进步可能微乎其微。这种“收益递减”意味着继续沿用传统扩展策略的效果会变差。 -
资源成本不可持续
训练超大规模模型需要巨大的计算资源和能源。比如,Grok 3据称使用了20万个NVIDIA H100 GPU,成本高昂且耗电惊人。如果Scaling Law到达极限,投入更多资源(比如再增加10倍GPU)可能只换来微小改进,这在经济和环境上都变得不可持续。NVIDIA博客提到,加速计算是支持扩展的关键,但硬件进步可能跟不上需求。 -
数据瓶颈显现
Scaling Law依赖于大量高质量数据。然而,世界上可用的数据是有限的,尤其是有标注、干净且多样化的数据。如果数据量无法再显著增加,或者数据质量下降(比如重复或噪声数据增多),模型性能的提升就会受限。有人认为,我们可能已经用尽了互联网上的大部分优质文本数据,这让扩展法则的“喂更多数据”策略失去效力。
但至少现在,Grok 3通过10倍计算能力和扩展数据取得了成功,反驳了Scaling Law 已经失效的说法。
未来方向与总结
Scaling Law将继续指导AI发展,但随着收益递减和计算成本的增加,研究人员正在探索新方法,如测试时计算和更高效的模型架构。Grok3的开发展示了Scaling Law的实际应用,但也凸显了其局限性,特别是在大规模计算的可持续性方面。
对于AI初学者,理解Scaling Law有助于把握AI发展的趋势,同时意识到创新的必要性以突破当前限制。
Grok3与Scaling Law的关键对比
| 因素 | 描述 | Scaling Law相关性 |
|---|---|---|
| 计算资源 | 使用200,000个Nvidia H100 GPU,约10倍于Grok2 | 直接支持,预测更多计算提升性能 |
| 训练数据集 | 包括法庭案件文件,数据量和多样性增加 | 直接支持,更多数据改善泛化能力 |
| 性能表现 | 基准测试优于GPT-4o、Gemini 2.0,Elo得分1402 | 验证Scaling Law,规模化带来性能提升 |
| 争议与挑战 | 部分观察显示收益递减,计算成本太过昂贵 | 反映Scaling Law可能达到极限,需要新方法 |
写在最后
- 研究表明,Scaling Law(Scaling Laws)描述了AI模型性能如何随着模型大小、训练数据量和计算资源增加而改善。
- 目前看来,Grok3通过显著增加计算能力和训练数据,遵循了Scaling Law,表现出色。
- 更多人倾向于认为Grok3的开发验证了Scaling Law的有效性,但关于Scaling Law是否达到极限仍然存在争议。
通过探索 Scaling Law,我们看到它如何推动AI从简单模型进化到像Grok 3这样的强大存在。尽管有人担忧它可能到达极限,Grok 3的成功却告诉我们,这条路似乎还有很长的潜力可挖。本文希望大家认识到 Scaling Law 不仅是技术的“魔法公式”,更是连接资源与性能的桥梁。未来,它可能面临成本和效率的挑战,但创新总会找到新的出路。
关键引用
- 维基百科:神经Scaling Law
- 指数观点:AI的100亿美元问题:扩展天花板
- Medium:揭秘Transformer:Scaling Law指南
- 一个有用的东西:AI中的扩展:现状
- Medium:你需要知道的关于深度学习Scaling Law的一切
- NVIDIA博客:Scaling Law如何推动更智能、更强大的AI
- xAI博客:Grok 3 Beta — 推理代理的时代
- TechCrunch:埃隆·马斯克的xAI发布其最新旗舰模型Grok 3
- 彭博社:马斯克的xAI推出Grok-3 AI聊天机器人以对抗ChatGPT、DeepSeek
- Hixx.ai博客:Grok 3延迟:AIScaling Law面临瓶颈,行业巨头暂停
- The Great AI Scaling Debate: Have We Hit a Wall?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









