









背景
最近同事线上提交发布了一个变更,导致平响涨了几ms,仔细看了变更后发现只是一个map的put和get逻辑,这里使用的方式有点奇怪,key为string类型,但是其实是一个枚举转换而来,value是Double类型
验证
这里怀疑map是string类型导致,因为这里key是一个枚举转换而来,所以感觉是使用enummap类来使用性能更好,但是这里毕竟只是猜想,所以需要科学的数据来验证 , 这里就搭了下JMH环境来验证,分别来验证几种类型的性能情况:
- Hashmap , key=string, value = Double
- HashMap , key=enum,value = Double
- EnumMap, key=enum, value = Double
环境搭建可以参考:https://zhuanlan.zhihu.com/p/381283590
具体验证代码:
import com.google.common.collect.Maps;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Param;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.EnumMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Benchmark)
public class EnumTests {
@Param({"1", "100", "10000", "1000000"})
public int size;
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(EnumTests.class.getSimpleName())
.warmupIterations(1)
.measurementIterations(1)
.forks(1)
.build();
new Runner(opt).run();
}
@Benchmark
public void testString() {
Item item = new Item();
for (int i = 0; i < size; i++) {
item.setStirngScores(Maps.newHashMapWithExpectedSize(5));
item.getStirngScores().put("CTR_SCORE", 0.00312D);
item.getStirngScores().put("GMV_SCORE", 0.00312D);
item.getStirngScores().put("CTRCVR_SCORE", 0.00312D);
item.getStirngScores().put("CPM_SCORE", 0.00312D);
item.getStirngScores().put("DIVERSITY_SCORE", 0.00312D);
item.getStirngScores().get("CTR_SCORE");
item.getStirngScores().get("GMV_SCORE");
item.getStirngScores().get("CTRCVR_SCORE");
item.getStirngScores().get("CPM_SCORE");
item.getStirngScores().get("DIVERSITY_SCORE");
}
}
@Benchmark
public void testEnum() {
Item item = new Item();
for (int i = 0; i < size; i++) {
item.setScores(Maps.newHashMapWithExpectedSize(5));
item.getScores().put(ScoreType.CTR_SCORE, 0.00312D);
item.getScores().put(ScoreType.GMV_SCORE, 0.00312D);
item.getScores().put(ScoreType.CTRCVR_SCORE, 0.00312D);
item.getScores().put(ScoreType.CPM_SCORE, 0.00312D);
item.getScores().put(ScoreType.DIVERSITY_SCORE, 0.00312D);
item.getScores().get(ScoreType.CTR_SCORE);
item.getScores().get(ScoreType.GMV_SCORE);
item.getScores().get(ScoreType.CTRCVR_SCORE);
item.getScores().get(ScoreType.CPM_SCORE);
item.getScores().get(ScoreType.DIVERSITY_SCORE);
}
}
@Benchmark
public void testEnumMap() {
Item item = new Item();
for (int i = 0; i < size; i++) {
item.setEnumScores(new EnumMap<>(ScoreType.class));
item.getEnumScores().put(ScoreType.CTR_SCORE, 0.00312D);
item.getEnumScores().put(ScoreType.GMV_SCORE, 0.00312D);
item.getEnumScores().put(ScoreType.CTRCVR_SCORE, 0.00312D);
item.getEnumScores().put(ScoreType.CPM_SCORE, 0.00312D);
item.getEnumScores().put(ScoreType.DIVERSITY_SCORE, 0.00312D);
item.getEnumScores().get(ScoreType.DIVERSITY_SCORE);
item.getEnumScores().get(ScoreType.DIVERSITY_SCORE);
item.getEnumScores().get(ScoreType.DIVERSITY_SCORE);
item.getEnumScores().get(ScoreType.DIVERSITY_SCORE);
item.getEnumScores().get(ScoreType.DIVERSITY_SCORE);
}
}
private class Item {
public Item() {
}
Map<ScoreType, Double> scores;
Map<String, Double> stirngScores;
EnumMap<ScoreType, Double> enumScores;
public EnumMap<ScoreType, Double> getEnumScores() {
return enumScores;
}
public void setEnumScores(EnumMap<ScoreType, Double> enumScores) {
this.enumScores = enumScores;
}
public Map<ScoreType, Double> getScores() {
return scores;
}
public void setScores(Map<ScoreType, Double> scores) {
this.scores = scores;
}
public Map<String, Double> getStirngScores() {
return stirngScores;
}
public void setStirngScores(Map<String, Double> stirngScores) {
this.stirngScores = stirngScores;
}
}
private enum ScoreType {
GMV_SCORE,
CTR_SCORE,
CTRCVR_SCORE,
CPM_SCORE,
DIVERSITY_SCORE;
}
}
最终结果:
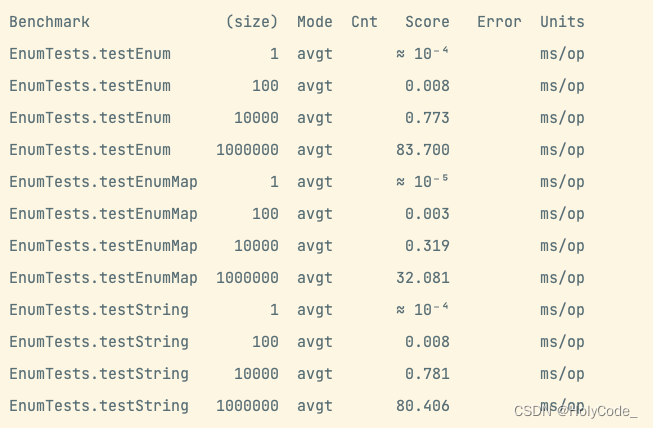
结论
可以看出来,随着操作数的增长, 如果是key为枚举类型的情况下,使用enummap是最优的
注意
test类如果放在test目录下的话,需要如下配置:
testImplementation ‘org.openjdk.jmh:jmh-core:1.33’
testAnnotationProcessor ‘org.openjdk.jmh:jmh-generator-annprocess:1.33’















 1594
1594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









