







|
首先看看堆栈
堆: 是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。
栈:是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是 thread safe的。每个C ++对象的数据成员也存在在栈中,每个函数都有自己的栈,栈被用来在函数之间传递参数。操作系统在切换线程的时候会自动的切换栈,就是切换 SS/ESP寄存器。栈空间不需要在高级语言里面显式的分配和释放。
然后看一下Linux的内存空间模型,这个图在很多地方都看过。
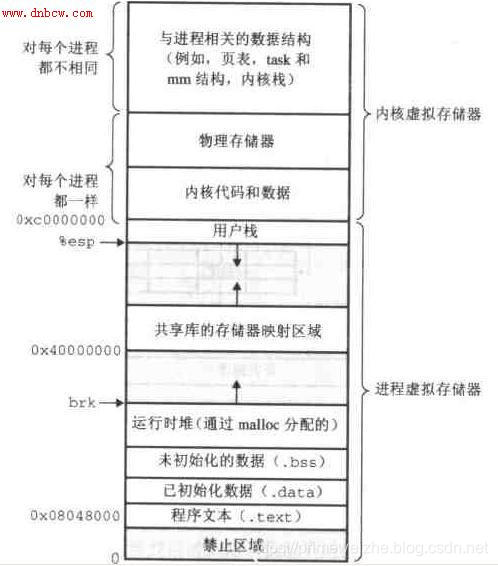
从上图可提取以下三点信息:
因此,对于以LinuxThread实现的多线程而言,要区分以下两种情况:
另外,msdn forum上面有个回答。 When we create a new thread, a new stack is allocated by CLR, with 1MB memory space, the stack is used to store method local variable, or parameters passed to next method.// CLR分配线程栈
A stack is the snapshot of a thread's execution, from the stack, we can know what a thread is doing, which method the thread is now executing; Generally, different threads have different Method Call Sequence, so their stacks store different data.//不同的线程有不同的线程栈
If we use synchronization logic in our code (for example, use lock keyword), supposing thread A has entered the critical area, thread A's stack will keep on growing (because of calling other methods or allocating more local variables); when thread B trying to enter same area, a data structure in the Heap will be checked, the data structure can tell that the critical area is occupied by thread A, so thread B will wait there.//堆里面的一个数据结构会检查,告诉临界区已经属于A,所以B会等待。
Threads are scheduled by OS (according to the priority), so thread A can create/start thread B, but thread A cannot assign CPU time to thread B. from the perspective of OS, all threads are same with each other, no primary, no secondary.//线程可以创建线程,但是不能分配cpu时间,因为这是由操作系统干的 1.进程和线程有什么区别? 这个一个最常见,却最不好回答的问题,csdn上面一位博主给出的解答和另一位cnblog博主的解答稍微清晰些一些,总结起来,就是一下的几个区别: a.进程是资源分配的基本单位,线程是cpu调度,或者说是程序执行的最小单位。在Mac、Windows NT等采用微内核结构的操作系统中,进程的功能发生了变化:它只是资源分配的单位,而不再是调度运行的单位。在微内核系统中,真正调度运行的基本单位是线程。因此,实现并发功能的单位是线程。 b.进程有独立的地址空间,比如在linux下面启动一个新的进程,系统必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种非常昂贵的多任务工作方式。而运行一个进程中的线程,它们之间共享大部分数据,使用相同的地址空间,因此启动一个线程,切换一个线程远比进程操作要快,花费也要小得多。当然,线程是拥有自己的局部变量和堆栈(注意不是堆)的,比如在windows中用_beginthreadex创建一个新进程就会在调用CreateThread的同时申请一个专属于线程的数据块(_tiddata)。 c.线程之间的通信比较方便。统一进程下的线程共享数据(比如全局变量,静态变量),通过这些数据来通信不仅快捷而且方便,当然如何处理好这些访问的同步与互斥正是编写多线程程序的难点。而进程之间的通信只能通过进程通信的方式进行。 d.由b,可以轻易地得到结论:多进程比多线程程序要健壮。一个线程死掉整个进程就死掉了,但是在保护模式下,一个进程死掉对另一个进程没有直接影响。 e.线程的执行与进程是有区别的。每个独立的线程有有自己的一个程序入口,顺序执行序列和程序的出口,但是线程不能独立执行,必须依附与程序之中,由应用程序提供多个线程的并发控制。 2. 什么是线程安全?(2012年5月百度实习生面试) 如果多线程的程序运行结果是可预期的,而且与单线程的程序运行结果一样,那么说明是“线程安全”的。 3. 秒杀多线程中的题目 解答 另外,这个网址里面讲操作系统的知识倒是挺详实的,还有另外一种解释线程概念 b.多线程的几种实现方法分别是什么? 这个貌似在java面试中会出现,我是专注于c++的,无视掉,但是不得不说,秒杀多线程面试题系列真心是个好总结 c.多线程同步与互斥有几种实现方法?都是什么?(C++) 临界区(CS:critical section)、事件(Event)、互斥量(Mutex)、信号量(semaphores),需要注意的是,临界区是效率最高的,因为基本不需要其他的开销,二内核对象涉及到用户态和内核态的切换,开销较大,另外,关键段、互斥量具有线程所有权的概念,因此只可以用于线程之间互斥,而不能用到同步中。只有互斥量能完美解决进程意外终止所造成的“遗弃问题”。 d.多线程同步和互斥有何异同,在什么情况下分别使用他们?举例说明 所谓同步,表示有先有后,比较正式的解释是“线程同步是指线程之间所具有的一种制约关系,一个线程的执行依赖另一个线程的消息,当它没有得到另一个线程的消息时应等待,直到消息到达时才被唤醒。”所谓互斥,比较正式的说明是“线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步。”表示不能同时访问,也是个顺序问题,所以互斥是一种特殊的同步操作。 举个例子,设有一个全局变量global,为了保证线程安全,我们规定只有当主线程修改了global之后下一个子线程才能访问global,这就需要同步主线程与子线程,可用关键段实现。当一个子线程访问global的时候另一个线程不能访问global,那么就需要互斥。 e.以下多线程对int型变量x的操作,哪几个需要进行同步: 答案是ABC,显然,y的写入与x读y要同步,x++和++x都要知道x之前的值,所以也要同步。 f.多线程中栈与堆是公有的还是私有的 A:栈公有, 堆私有 B:栈公有,堆公有 C:栈私有, 堆公有 D:栈私有,堆私有 答案是C,栈一般存放局部变量,而程序员一般自己申请和释放堆中的数据(详见堆与栈的区别)。 g.在Windows编程中互斥量与临界区比较类似,请分析一下二者的主要区别。 针对这个题目的话,答案主要有以下几点: 1)互斥量是内核对象,所以它比临界区更加耗费资源,但是它可以命名,因此可以被其它进程访问 2)从目的是来说,临界区是通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。 h.一个全局变量tally,两个线程并发执行(代码段都是ThreadProc),问两个线程都结束后,tally取值范围。
当两线程串行时,结果最大为100,当某个线程运行结束,而此时另外一个线程刚取出0,还未计算时,结果最小为50。
【参考资料】
|

















02-15
 2094
2094
2094
09-05
939
939
03-11
7297
7297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









