







一、hadoop2.0原理
Hadoop是Apache软件基金会旗下的一个分布式系统基础架构。Hadoop2的框架最核心的设计就是HDFS,MapReduce,YARN。为海量的数据提供了存储和计算。其中,HDFS为分布式存储系统,为海量数据提供存储,不适合应用于以下场景:1.低延迟数据访问,2.大量的小文件,3.多用户写入文件;MapReduce用户分布式计算;YARN为资源管理器,Hadoop2.0之后才开始出现。以下为Hadoop1.0和Hadoop2.0结构的对比:

从以上图中可以看到hadoop2.0之后多了YARN和Others。
为什么要引入YARN呢?主要是因为Hadoop1.0存在以下弊端:
1.扩展性差,JobTracker同时负责了资源管理和作业分布,导致了扩展性差
2.可靠性差,JobTracker是MapReduce运行的重心,一旦出现故障会导致整个集群不可用
3.资源利用率低,Hadoop1.0中以Slot为单位,极大的浪费了资源,Hadoop2.0中以内存为单位
4.无法支持多种计算框架,Hadoop1.0只支持mapreduce等离线作业处理,不支持内存计算,流式计算等
于是,引入YARN,YARN为一个通用的资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。YARN的主要设计思想是将Hadoop中JobTracker拆分成两个独立的服务分别负责资源管理和任务调度,他们是:ResourceManager和ApplicationMaster,ResourceManager负责整个系统的资源管理和分配,ApplicationMaster负责单个应用程序的管理。YARN里面还有NodeManager和Container,NodeManager为YARN的slave,主要负责监控单个的应用程序,与ResourceManager形成两个Master和Slave的关系;Container则是一个动态的资源单位,主要作为资源的隔离。结构如下图所示:

Hadoop2.0主要改进表现在以下方面:
1.引入YARN,实现资源的管理和分配,从而提高资源利用率,可实现更多类型的编程模型,计算框架。
2.实现了NameNode 的HA,保证了集群的高可用性。
3.实现了HDFS Federation,提高了整个集群的可扩展性。
4.Hadoop RPC系列化可扩展性好。
二、环境搭建
系统:centos6.8,
hadoop版本:hadoop2.7.3,
java版本:java1.7
1.在vmware中安装centos6.8系统,根据自己的需求选择下一步,centos系统比ubuntu系统多一些选项,选择的时候仔细些。我这边选择了安装有桌面版的。
2.选择网络连接方式,我这边选择桥接模式,设置主机名为hadoop
vim /etc/hosts
添加:127.0.0.1 hadoop
vim /etc/sysconfig/network
修改:HOSTNAME=hadoop
重启网络:service network restart
3.设置ssh免密码登录
为了安全,会为hadoop新建一个一般用户hadoop,之后的操作都是在hadoop用户之下。
su hadoop(切换到hadoop用户下)
ssh-keygen -t rsa(生成密钥.位置在~/.ssh下)
cat id_rsa.pub >> authorized_keys (将生成的密钥拷贝到authorized_keys中)
chmod 600 authorized_keys (更改文件的权限)
设置好密钥之后,还需要更改系统的配置,位置:/etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
尝试ssh localhost,如果免输密码,则配置成功
4.安装java1.7(可用root用户)
将jdk1.7安装包拷贝到虚机中,安装的文件放置在/usr/java下
解压缩:tar -xzvf jdk-7u25-linux-x64.tar.gz 得到jdk1.7.0_25文件夹
配置环境变量:这里配置全局环境变量,路径在/etc/profile

使环境变量生效:source /etc/profile
在命令终端,输入:java -version 验证java是否安装配置成功
5.安装hadoop2.7.3(用一般用户hadoop)
将hadoop安装包拷贝到虚机中,文件放置/usr下
解压缩:tar -xzvf hadoop-2.7.3.tar.gz 得到hadoop-2.7.3文件夹,删除安装包
配置环境变量:这里配置hadoop用户下环境变量,
vim ~/.bashrc

是环境变量生效: source ~/.bashrc
6.接下来就是配置hadoop下的各种文件了,一共需要配置的文件如下:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
(1) hadoop-env.sh hadoop的基本配置,路径配置,在这里需要修改java的路径即可。
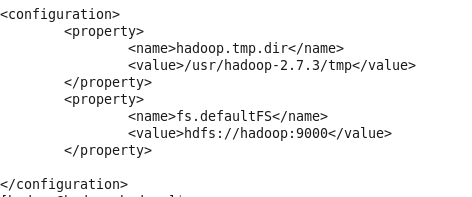
(2) core-site.xml 配置系统默认分布式URI,与hadoop1.x版本略不同
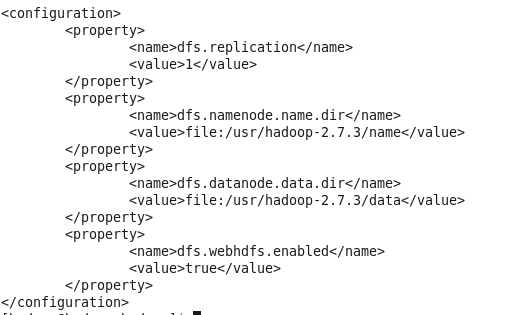
(3) hdfs-site.xml 配置datanode和namenode的路径以及数据副本数
dfs.replication,数据副本数,若为伪分布式,值为1
(4) mapred-site.xml mapreduce相关配置,这里主要配置MapReduce第三方框架和服务
mapreduce.framework,name:mapreduce第三方框架使用YARN,YARN是hadoop2.x之后出现的资源管理器
mapreduce.jobhistory.address:jobhistory监控地址及端口号
mapreduce.jobhistory.webapp.address: jobhistory网页端监控地址及端口号,启动jobhistory之后在网页端能够看到相关日志

(5) yarn-site.xml YARN的相关配置
这里主要配置了nodemanager和resourcemanager
yarn.nodemanager.aux-services:nodemanager的第三方服务,配置成maprefuce_shufflle可运行mapreduce程序
yarn.resourcemanager.webapp.address:配置resourcemanager的地址和端口号,启动对应服务之后,可在网页端查看。

7.启动hdfs:./start-dfs.sh
启动yarn:./start-yarn.sh
启动historyserver:mr-jobhistory-daemon.sh start historyserver
在浏览器中分别输入:http://hadoop:50070 (hdfs地址)
http://hadoop:8099 (yarn地址)
http://hadoop:19888 (jobhistory)















 4401
4401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









