







SQL
SQL简介
SQL 是用于访问和处理数据库的标准的计算机语言。
- SQL,指结构化查询语言,全称是 Structured Query Language;
- SQL 是一种 ANSI(American National Standards Institute 美国国家标准化组织)标准的计算机语言;
- SQL 让您可以访问和处理数据库,但SQL决不仅仅是一个查询工具,还用于控制DBMS提供给用户的所有功能;
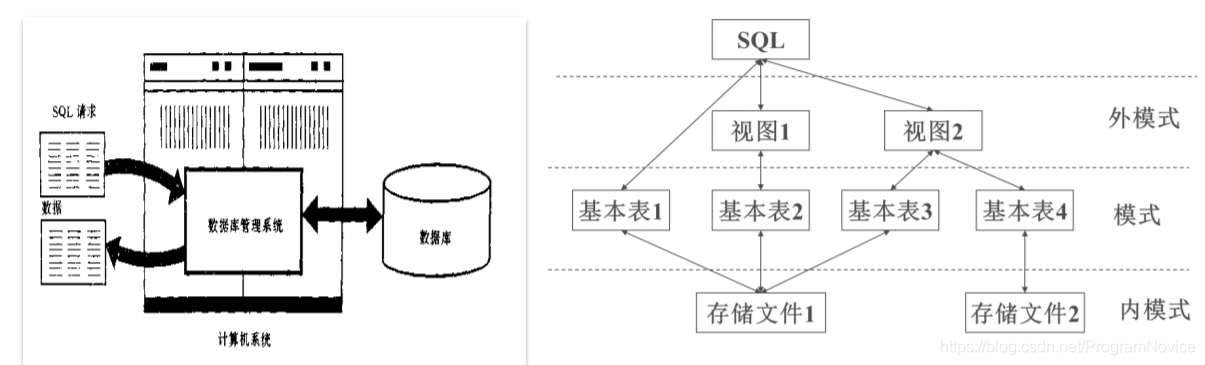
- SQL支持三级模式。
SQL特性
综合统一
- 集DDL、DML、DCL的功能于一体;
- 可以在运行后根据需要随时修改模式;
- 数据操作符统一。
高度非过程化
- 只需提出“做什么”,而无需指明“怎么做”;
- 无需了解存取路径,存取路径的选择以及SQL语句的操作过程由系统自动完成。
面向集合的操作方式
- 操作对象和结果均为集合
以同一种语法结构提供两种使用方法
- 既是自含式语言,又是嵌入式语言。
语言简洁
核心功能只需9个动词:
- DDL:CREATE、DROP、ALTER
- DML: SELECT、INSERT、UPDATE、DELETE
- DCL:GRANT、REVOKE
数据库操作
数据库是包含多个对象的集合,包含了相关的基表、视图、索引、存储过程、与数据库安全性有关的控制机制及其他对象。
SQL SERVER使用一组操作系统文件映射数据库。所有数据和对象(如表、视图等)都存储3种操作系统文件中:
- 主文件:扩展名为mdf,包含数据库的启动信息及数据信息。每个数据库都有一个主文件。
- 次要文件(从文件):扩展名为ndf,含有主文件以外的所有数据。作用是提高数据访问效率。
- 事务日志:扩展名为ldf,包含用于恢复数据库的日志信息。每个数据库都必须至少有一个日志文件。
创建数据库
为了创建数据库,用户必须是系统管理员或者被授权使用CREATE DATABASE语句,语法形式如下:
CREATE DATABASE <数据库名>
[<On Primary>
% 一个数据库可建多个档案文件,主档案文件是会有一个,默认在主档案文件
([Name = 系统使用的逻辑名],
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
[<Log On>
([Name = 系统使用的逻辑名],
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[FileGrowth = 系统的扩展文件量])]
修改数据库
语法形式如下:
ALTER DATABASE <数据库名>
[<Add File>
(<Name = 系统使用的逻辑名>,
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
[<Modify File>
(<Name = 系统使用的逻辑名>,
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
[<Remove File> <系统使用文件的逻辑名>,…]
[<Add Log File>
(<Name = 系统使用的逻辑名>,
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
删除数据库
语法形式如下:
DROP DATABASE 需要删除的数据库名
数据库删除之后,该数据库的文件及其数据都从服务器的磁盘删除。当数据库被删除,它即被永久删除,并且不能进行检索,除非使用以前的备份。
不能删除系统数据库msdb,master,model和tempdb。
选择数据库
语法形式如下:
USE 数据库名
数据表操作
SQL Server的数据类型、功能及特点

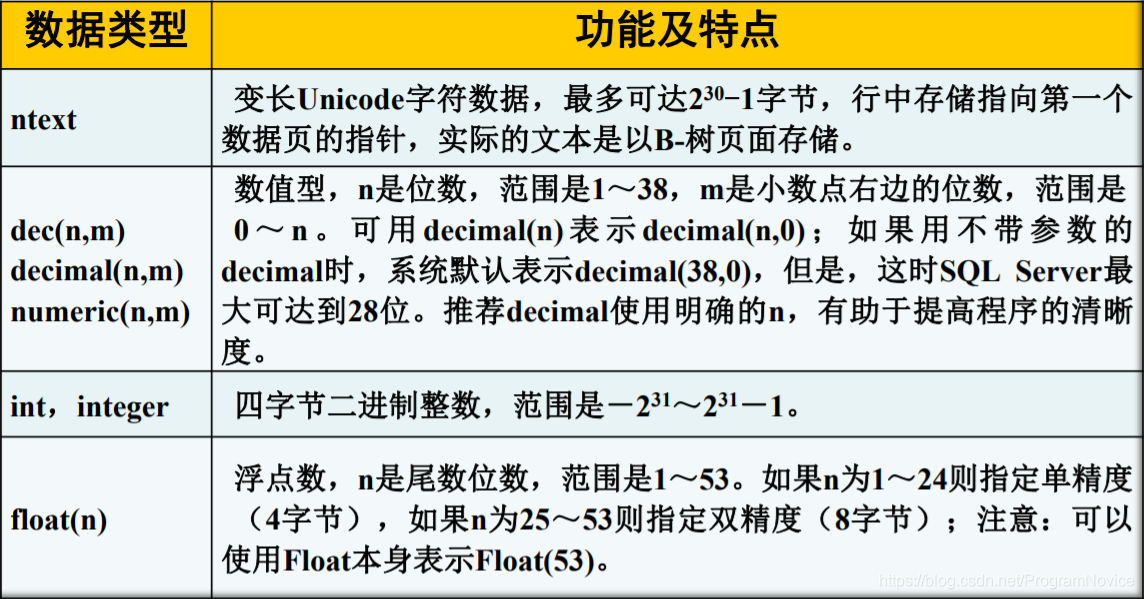
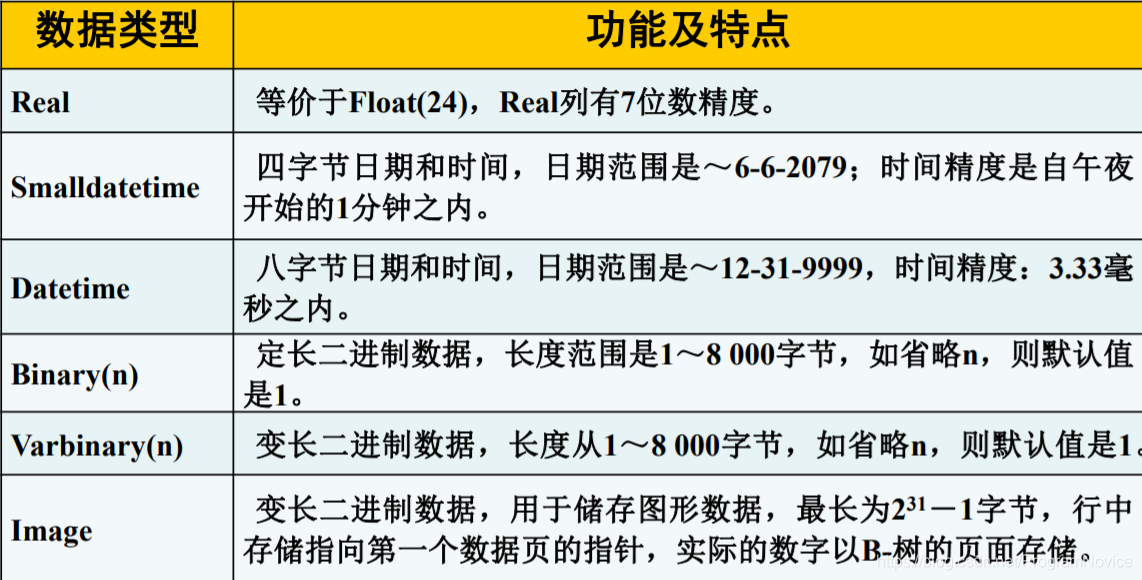
菜鸟教程:MySQL 数据类型
创建数据表
以下为创建MySQL数据表的SQL通用语法:
CREATE TABLE table_name (column_name column_type);
举例:
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
解析:
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错;
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1;
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔;
- ENGINE 设置存储引擎,CHARSET 设置编码。
修改数据表
语法格式:
ALTER TABLE 〈表名〉
[ ALTER COLUMN <列名> <数据类型>],
[ ADD <新列名> <数据类型> <约束规则>],
[ DROP <列名>],
[ DROP <约束规则>];
- <表名>:要修改的基本表;
- ADD子句:增加新列和新的完整性约束条件;
- DROP子句:删除指定的完整性约束条件;
- ALTER子句:用于修改列名和数据类型。
注意:
使用ALTER TABLE语句在表中增加列,如果新增列定义为NOT NULL列,必须用Default子句指定缺省值,否则,没有指定缺省值,当给表增加新列时,表中原有记录的新增列将自动为NULL,这样就会违背NOT NULL的定义而出错。
删除数据表
以下为删除MySQL数据表的通用语法:
DROP TABLE table_name ;
数据操作
SELECT
SELECT 语句用于从数据库中选取数据。结果被存储在一个结果表中,称为结果集。
SQL SELECT 语法:
SELECT column_name,column_name FROM table_name;
与
SELECT * FROM table_name;
菜鸟教程:表的别名
SELECT DISTINCT
在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。
DISTINCT 关键词用于合并查询结果中的重复记录,返回唯一不同的值。
SQL SELECT DISTINCT 语法:
SELECT DISTINCT column_name,column_name FROM table_name;
WHERE
WHERE 子句用于提取那些满足指定条件的记录。
SQL WHERE 语法:
SELECT column_name,column_name FROM table_name
WHERE column_name operator value;
WHERE 子句中的运算符:
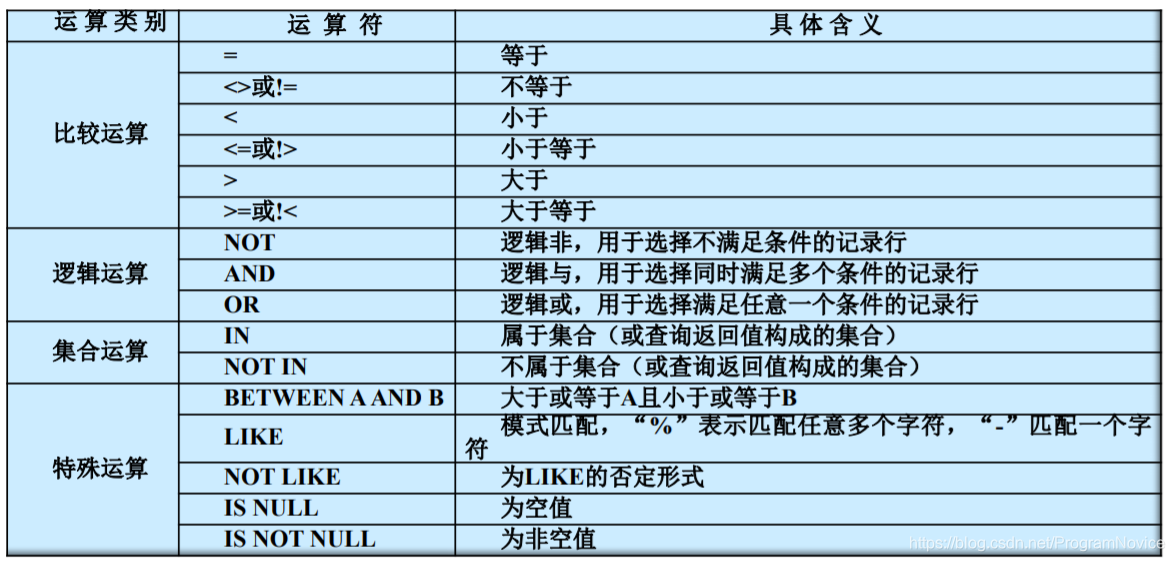
条件运算符的优先级顺序:
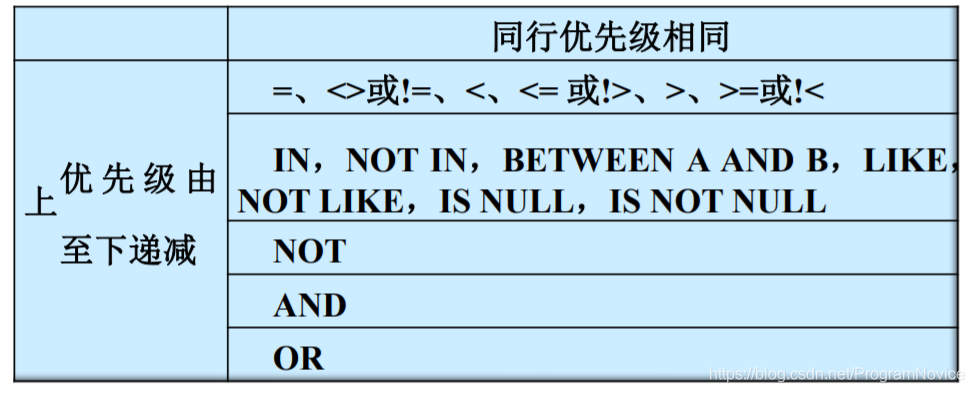
横向同行优先级相同,在具体的运算表达式中在左边者优先。
如有括号则括号优先。
IN
IN 操作符允许您在 WHERE 子句中规定多个值。
SQL IN 语法:
SELECT column_name(s) FROM table_name
WHERE column_name IN (value1,value2,...);
举例:
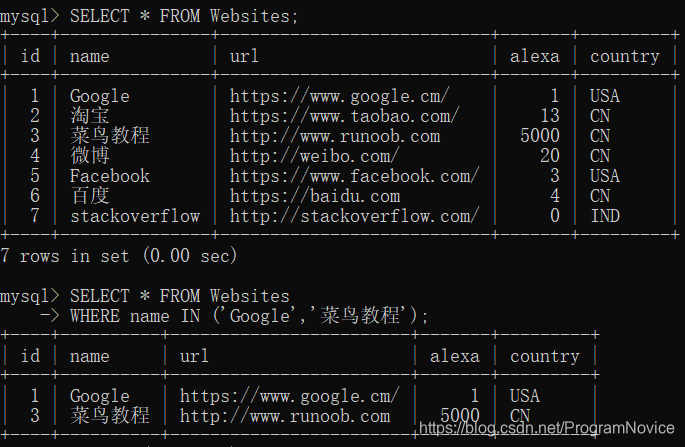
ORDER BY
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键字。
SQL ORDER BY 语法:
SELECT column_name,column_name FROM table_name
ORDER BY column_name,column_name ASC|DESC;
带聚集函数的统计查询

GROUP BY
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
SQL GROUP BY 语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
举例:
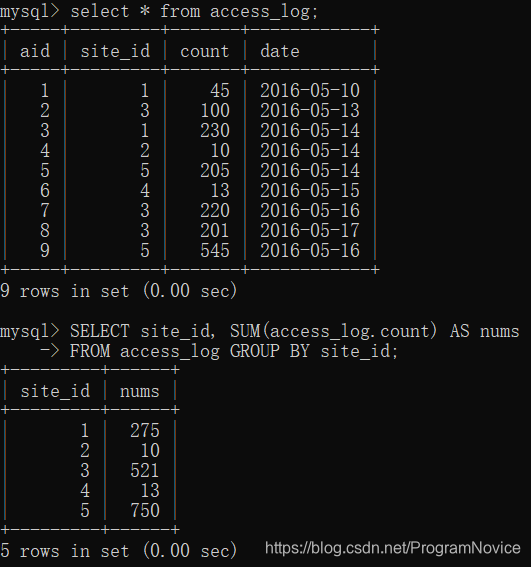
HAVING
HAVING 子句可以让我们筛选分组后的各组数据。
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
SQL HAVING 语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
举例:
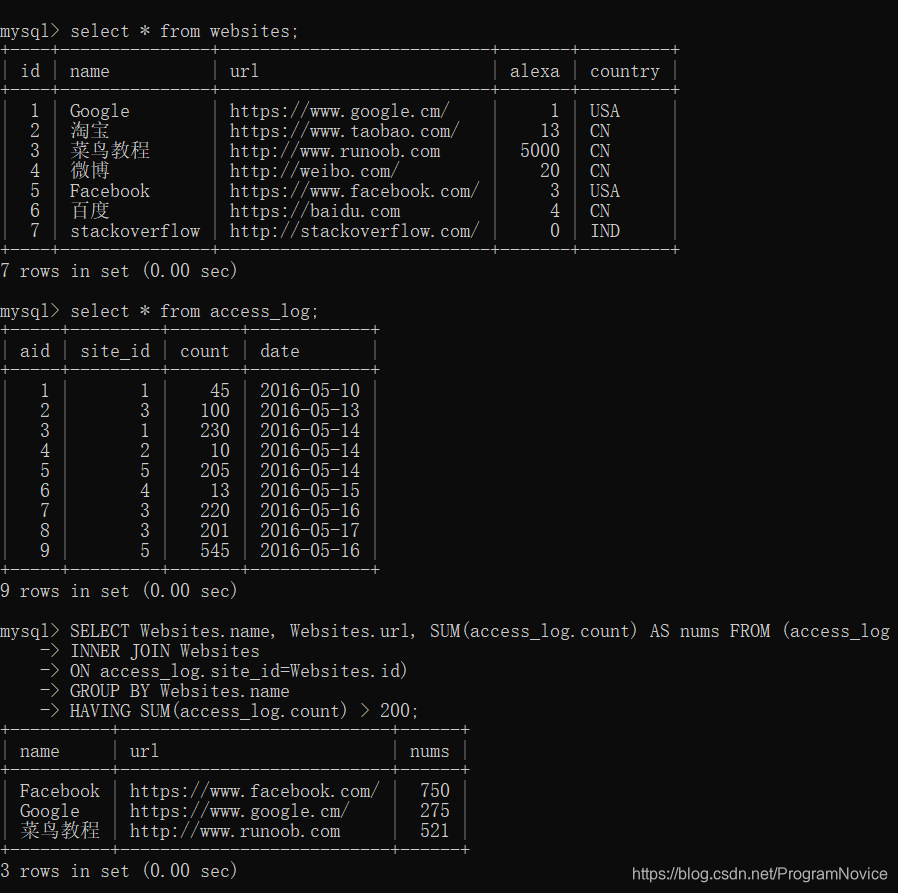
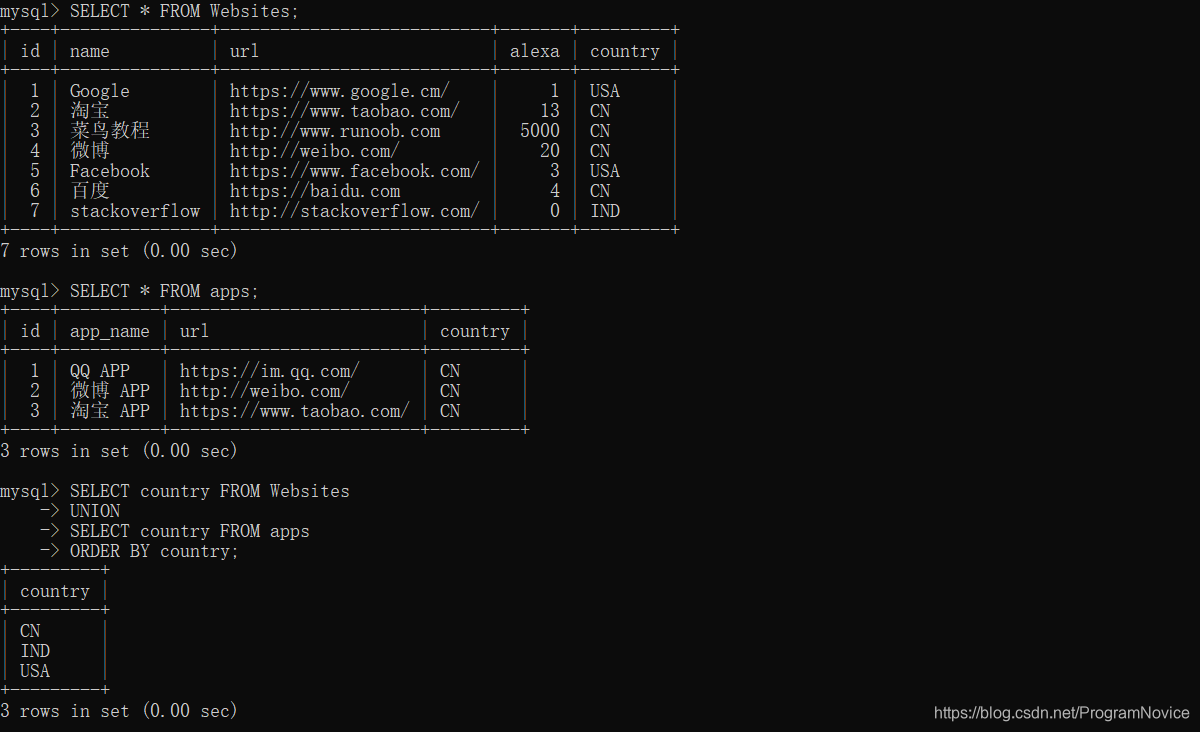
UNION
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SQL UNION 语法:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
举例:
UNION ALL
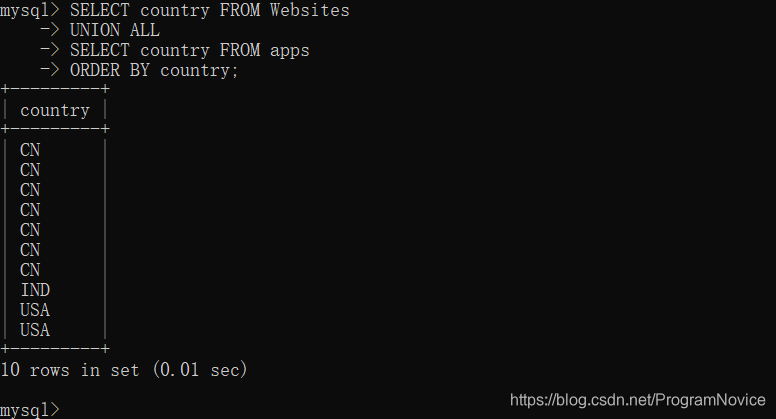
SQL UNION ALL 语法:
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
举例:
INSERT INTO
INSERT INTO 语句用于向表中插入新记录。
SQL INSERT INTO 语法:
INSERT INTO 语句可以有两种编写形式。
第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);
第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
举例:

UPDATE
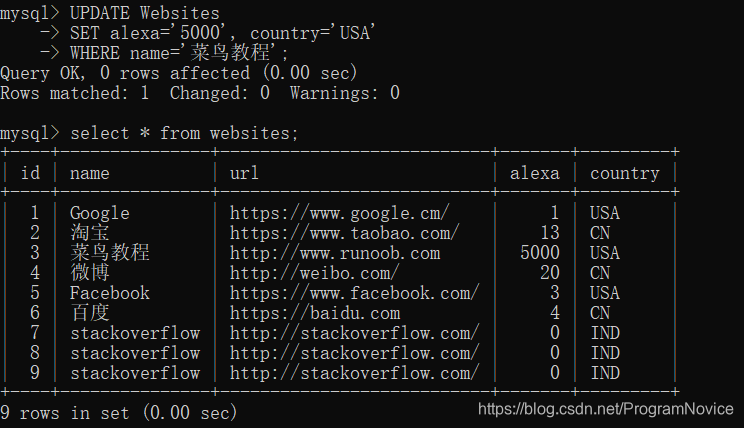
UPDATE 语句用于更新表中已存在的记录。
SQL UPDATE 语法:
UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;
举例:
DELETE
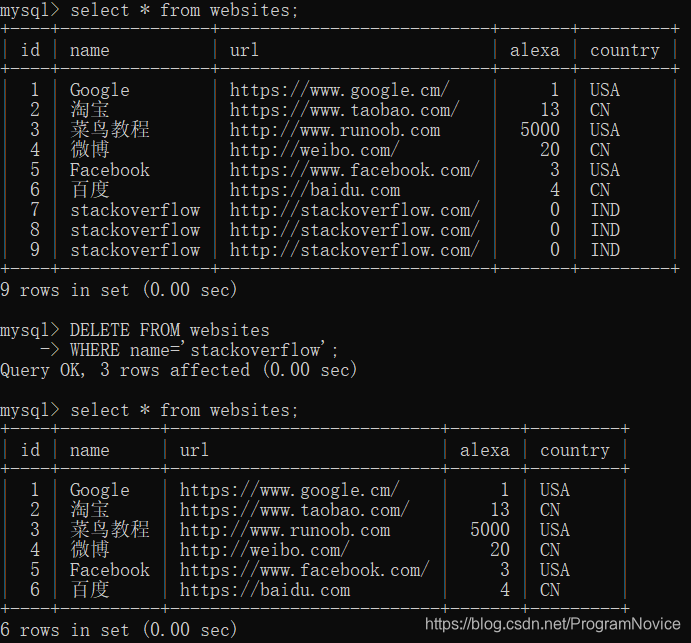
DELETE 语句用于删除表中的行。
SQL DELETE 语法:
DELETE FROM table_name
WHERE some_column=some_value;
举例:
视图(Views)
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
视图的特点:
- 虚表,是从一个或几个基本表(或视图)导出的表;
- 只存放视图的定义,不会出现数据冗余;
- 基表中的数据发生变化,从视图中查询出的数据也随之改变;
- 当视图建立后,用户可以象基表一样对视图进行数据查询,在某些特殊情况下,还可以对视图进行修改和插入操作。
视图的作用:
- 视图能够简化用户的操作;
- 视图使用户能以多种角度看待同一数据;
- 视图能够对机密数据提供安全保护;
- 利用视图可以清晰地表达查询;
- 视图对重构数据库提供了一定程度的逻辑独立性。
视图的优点: - 限制用户直接存取基表的某些列或记录,从而为基表带来附加的安全性;
- 视图可定义在多个基表上或其他视图上,通过视图可得到多个表经计算后的数据,从而隐藏数据的复杂性。
视图的缺点:
- 增加了数据库的维护成本;
- 视图只是简化了查询,但是并不能加快查询的速度。
CREATE VIEW
SQL CREATE VIEW 语法:
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
举例:
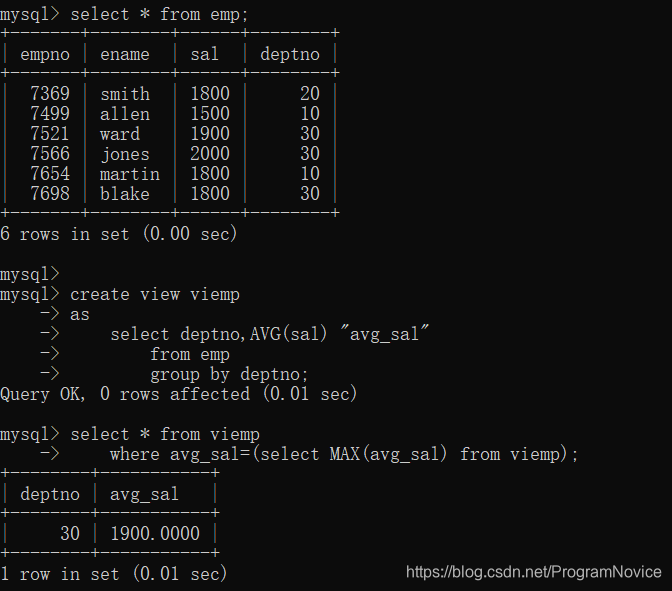
CREATE OR REPLACE VIEW
SQL CREATE OR REPLACE VIEW 语法:
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
DROP VIEW
SQL DROP VIEW 语法:
DROP VIEW view_name
举例:

索引
概念
索引类似于词典的索引,索引是关于数据位置信息的关键字表。数据库中的索引是一个表中所包含的值的列表,其中注明了表中包含各个值的记录所在的存储位置。索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
索引由DBMS内部实现,属于内模式范畴。
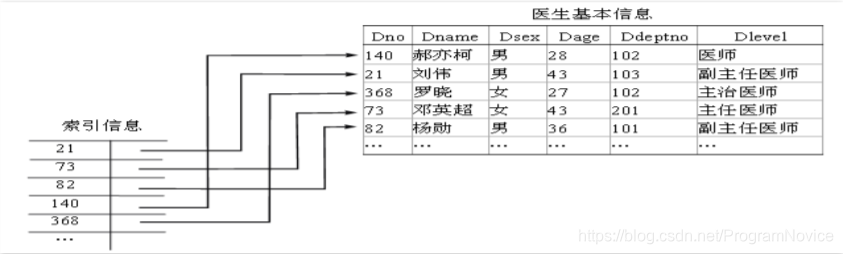
索引的优点:
数据库系统检索数据时,根据索引提供的信息,可以直接找到与该条件临近的数据区,而不是一条一条记录地比较,因此可提高查询速度。
索引的缺点:
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
普通索引
创建索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
CREATE INDEX indexName ON mytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
或者创建表的时候直接指定:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
修改表结构(添加索引):
ALTER table tableName ADD INDEX indexName(columnName)
删除索引
DROP INDEX [indexName] ON mytable;
唯一索引
它与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
CREATE UNIQUE INDEX indexName ON mytable(username(length))
或者创建表的时候直接指定:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
UNIQUE [indexName] (username(length))
);
修改表结构:
ALTER table mytable ADD UNIQUE [indexName] (username(length))
使用ALTER 命令添加和删除索引
有四种方式来添加数据表的索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list)
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list)
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list)
添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)
该语句指定了索引为 FULLTEXT ,用于全文索引。
显示索引信息
使用 SHOW INDEX 命令来列出表中的相关的索引信息。可以通过添加 \G 来格式化输出信息。
SHOW INDEX FROM table_name; \G


















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











