







机器学习系列专栏
选自 Python-Machine-Learning-Book On GitHub
作者:Sebastian Raschka
翻译&整理 By Sam
这个系列的文章写得也是够长时间的了,不过总算是写完了,今晚就把之前的内容做一次汇总,同时也把相关code打包share出来。
由于文章较长,所以我还是先把目录提前。
一、认识管道流
1.1 数据导入
1.2 使用管道创建工作流
二、K折交叉验证
2.1 K折交叉验证原理
2.2 K折交叉验证实现
三、曲线调参
3.1 模型准确度
3.2 绘制学习曲线得到样本数与准确率的关系
3.3 绘制验证曲线得到超参和准确率关系
四、网格搜索
4.1 两层for循环暴力检索
4.2 构建字典暴力检索
五、嵌套交叉验证
六、相关评价指标
6.1 混淆矩阵及其实现
6.2 相关评价指标实现
6.3 ROC曲线及其实现
一、认识管道流
今天先介绍一下管道工作流的操作。
“管道工作流”这个概念可能有点陌生,其实可以理解为一个容器,然后把我们需要进行的操作都封装在这个管道里面进行操作,比如数据标准化、特征降维、主成分分析、模型预测等等,下面还是以一个实例来讲解。
1.1 数据导入与预处理
本次我们导入一个二分类数据集 Breast Cancer Wisconsin,它包含569个样本。首列为主键ID,第2列为类别值(M=恶性肿瘤,B=良性肿瘤),第3-32列是实数值的特征。
先导入数据集:
1# 导入相关数据集
2import pandas as pd
3import urllib
4try:
5 df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases'
6 '/breast-cancer-wisconsin/wdbc.data', header=None)
7except urllib.error.URLError:
8 df = pd.read_csv('https://raw.githubusercontent.com/rasbt/'
9 'python-machine-learning-book/master/code/'
10 'datasets/wdbc/wdbc.data', header=None)
11print('rows, columns:', df.shape)
12df.head()
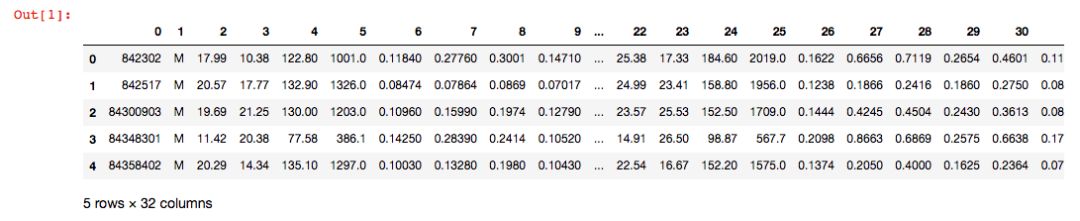
使用我们学习过的LabelEncoder来转化类别特征:
1from sklearn.preprocessing import LabelEncoder
2X = df.loc[:, 2:].values
3y = df.loc[:, 1].values
4le = LabelEncoder()
5# 将目标转为0-1变量
6y = le.fit_transform(y)
7le.transform(['M', 'B'])
划分训练验证集:
1## 创建训练集和测试集
2from sklearn.model_selection import train_test_split
3X_train, X_test, y_train, y_test = \
4 train_test_split(X, y, test_size=0.20, random_state=1)
1.2 使用管道创建工作流
很多机器学习算法要求特征取值范围要相同,因此需要对特征做标准化处理。此外,我们还想将原始的30维度特征压缩至更少维度,这就需要用到主成分分析,要用PCA来完成,再接着就可以进行logistic回归预测了。
Pipeline对象接收元组构成的列表作为输入,每个元组第一个值作为变量名,元组第二个元素是sklearn中的transformer或Estimator。管道中间每一步由sklearn中的transformer构成,最后一步是一个Estimator。
本次数据集中,管道包含两个中间步骤:StandardScaler和PCA,其都属于transformer,而逻辑斯蒂回归分类器属于Estimator。
本次实例,当管道pipe_lr执行fit方法时:
1)StandardScaler执行fit和transform方法;
2)将转换后的数据输入给PCA;
3)PCA同样执行fit和transform方法;
4)最后数据输入给LogisticRegression,训练一个LR模型。
对于管道来说,中间有多少个transformer都可以。管道的工作方式可以用下图来展示(一定要注意管道执行fit方法,而transformer要执行fit_transform):
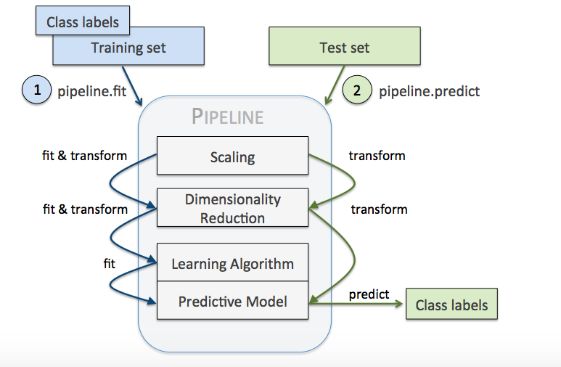
上面的代码实现如下:
1from sklearn.preprocessing import StandardScaler # 用于进行数据标准化
2from sklearn.decomposition import PCA # 用于进行特征降维
3from sklearn.linear_model import LogisticRegression # 用于模型预测
4from sklearn.pipeline import Pipeline
5pipe_lr = Pipeline([('scl', StandardScaler()),
6 ('pca', PCA(n_components=2)),
7  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









