






优秀文章分享
作者:数据不吹牛
公众号:数据不吹牛
“你是个好人,但我绝不会接受一个连热门口红品牌色号都分不清的好直男”。
情人节告白被拒历历在目,小Z觉得,作为一个做数据分析的直男,有必要让数据来解决自己的困惑——什么是热门的口红色号。
一来呢是为自己正名,二来是把数据分析思路和结果公之于众,为直男圈做一点点微小的贡献。
小Z攥紧了拳头暗暗发誓:“哥要用数据来找到热门的口红品牌和HOT色号!”
小Z原本天真的以为口红色号就像鞋码一样,每个品牌都是通用的,43码就是43码,阿迪并没有比阿迪王高贵,只需要一视同仁的爬取和统计数据就OK了。
但口红用残酷的现实啪啪打醒了他。
不同的品牌,甚至同一个品牌的不同系列,就算颜色看起来一毛一样,色号也是不同的。
“没关系,那我就先找出热门品牌,再分析不同品牌的热门色号”小Z早已百折不挠。“淘宝(包括天猫)是走量最大的平台,那这次分析就从淘宝入手吧”。
Part 1 热门口红品牌初体验
说干就干,小Z先在淘宝搜索“口红”,按销量排序,明确第一步目标:先爬下TOP200产品的标题、收货人数(这里不完全是销量,是30天内确认收货的人数,这个数据和评价[因为评价都是收到货之后才评价]结合效果更好)、价格、店铺名称和地址。
仔细观察发现,第一步我们需要的所有数据都在静态网页中,直接requests网址即可。
(之所以只拿下TOP200,是因为他在电商浅耕多年的直觉:一个销量可观的行业,TOP200产品的特征已经能够代表行业的趋势了。)
一顿操作猛如虎,一看结果有眉目:
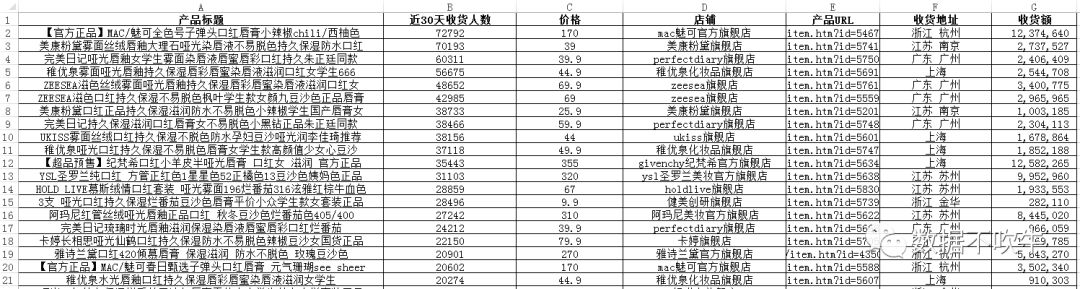 基本字段齐活了,还缺什么呢?第一步不是要分析品牌吗?品牌在哪里?
基本字段齐活了,还缺什么呢?第一步不是要分析品牌吗?品牌在哪里?
要通过产品标题或者店铺名称来清洗出品牌未免也太太太麻烦了,不慌,小Z发现每款产品详情页记录着关于品牌的信息:

恰好我们第一步记录了每个产品的URL,这一步的数据也藏在静态网址中,只需要依次访问爬取就好了

数据源已备好,在分析前小Z很明确分析的最终目的:送妹!!!!!!
如果按照销量排名来看品牌热度,难免有些单纯走量的品牌跻身前10,所以,后面的分析主要基于金额排序:
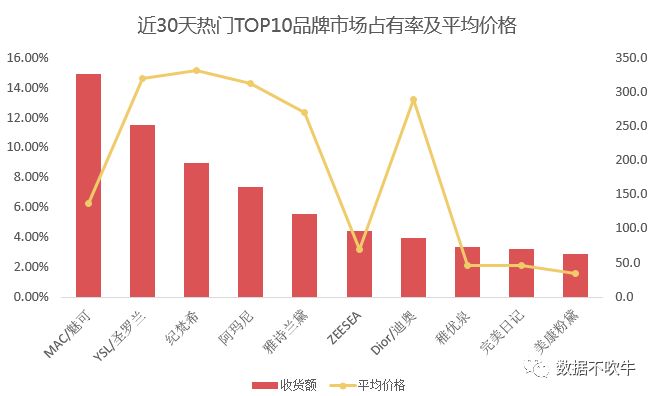
1、近30天TOP10品牌出炉,MAC(这可不是电脑的那个MAC)以14.96%的市场占有率独占鳌头,YSL、纪梵希紧随其后。不难看出,前10个品牌(TOP200产品中共计85个品牌)累计占据了66.35%的市场份额。更进一步,20%的品牌占据了78.89%的收货额,二八法则可谓诚不欺我小Z。
2、从平均价格来看,热门品牌可以分为三个梯队,第一梯队是高端线:纪梵希、YSL、阿玛尼、DIOR和雅诗兰黛,平均价格都在270以上;MAC以136元的平均价格独占第二梯队;第三梯队则是亲民品牌,ZEESEA、完美日记、稚优泉与美康粉黛,平均价格不超过50元。
至此,热门品牌和价格梯队划分完成,下面就是死磕不同品牌的色号了。
Part 2 不同品牌的热门色号
这一步的操作小Z决定继续细分,围绕数据爬取——清洗——分析的流程来进行。
一、数据爬取
所有关于商品色号的信息,都藏在商品评论里:
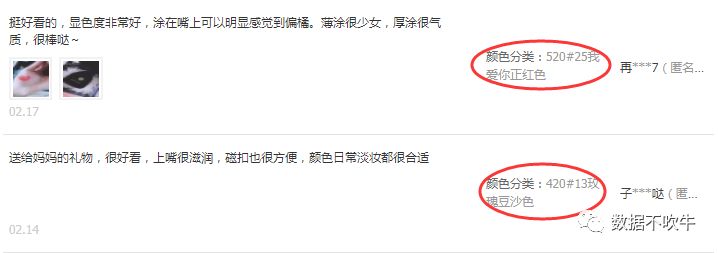
从消费心理学角度来看,购买之后且愿意评论的人虽是少数,但这些评论者本身受到产品触动,具有强烈的表达意愿,他们所购买的产品色号就更具备参考价值。
小Z决定从高、中梯队抽取每一个品牌的爆款(TOP1)产品,进行评价抓取。(同志,毕竟是送妹,先放过亲民线品牌)
敲黑板,页面前端展示评价数都是成千上万,但实际爬取过程中,最多只有99页(20*99条)的权限。
另外,评论内容是以动态形式存放在详情的JS网页中,以list_detail_rate开头,访问后是JSON格式,灰常简单:
小Z先网罗了纪梵希、YSL、阿玛尼、DIOR、雅诗兰黛和MAC官方旗舰店爆款(总销量TOP1)产品:

再分别爬取之,最终拿到合计10953条评价,还有买家昵称、评论时间以及我们最喜欢的色号信息:
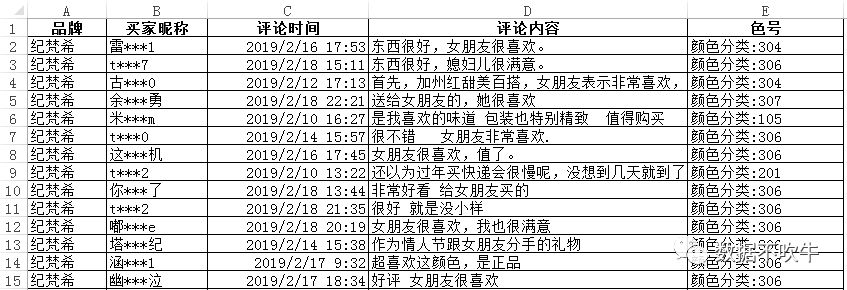
二、数据清洗
数据还挺全,那岂不是直接做一个分类统计就知道什么色号火了!小Z想想都觉得激动。
BUT!TOO YOUNG TOO SIMPLE!
小Z突然想到曾经的自己,只有两种情况才会主动评价,一种是吹到爆的好物(或者觉得东西不错商家还好评送红包);一种是烂到不行,感觉智商受到侮辱必须奋起反击,揭不义于公众。
“如果无差别的统计色号,万一,有一款谁买谁骂的色号在统计中排名靠前,而我又向旁友们推荐了这款色号!!!这可是犯罪啊!”
所以,小Z作为一个严谨的数据分析师,做色号之前先对评价进行清洗:
1、简单去噪,发现评价中有部分“此用户没有填写评论”,这一类无意义的评价必须剔除(其实还有一些是评价模板,旁友们自己尝试的时候可以细化,这里只是思路,暂不展开)。
2、对每条评价情感打分,只留下偏正向(积极)的评价,再统计色号。
由于评价都是中文,小Z这次用了PYTHON中的SnowNLP库,用法很简单,举个例子:

sentiments方法返回的是一个0-1之间的情感分值,越接近1表明情感越积极,越靠近0则越消极。
小Z批量对评价进行情感判定,剔除掉没有评论的评价,并且只留下分值大于等于0.6(偏积极)的结果。

经过清洗之后,10953条评价还剩9116条,看来口红绝大部分评价都是偏正向(炫耀)的。
三、数据分析
1、不同品牌色号数量分布:
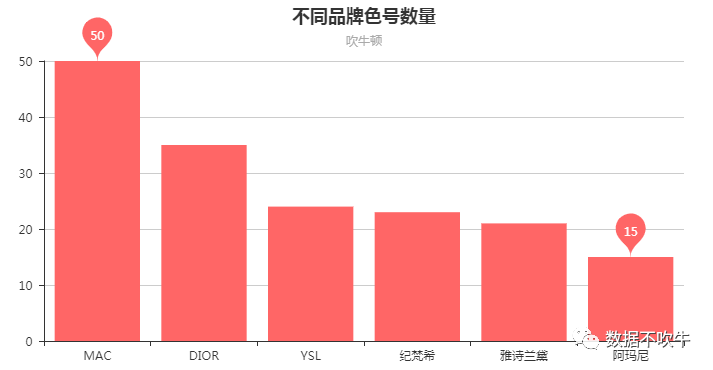
从爆款产品色号数量来看,MAC可谓全面,评论中竟然涉及到50个色号。随后是DIOR的35个色号,YSL、纪梵希、雅诗兰黛色号数量比较接近,都在21左右。阿玛尼则比较高冷,只有15个色号供选择。但色号数量只能看一个总览,各品牌色号集中度是一个什么样的情况呢?
2、各品牌色号集中度:
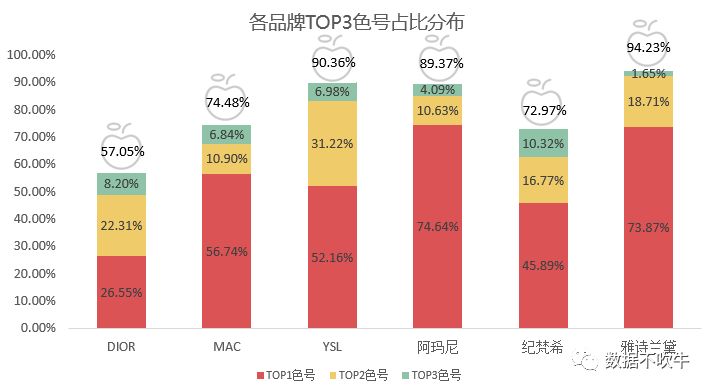
通过各品牌TOP3色号占比和累计占比来分析色号集中度。
YSL、阿玛尼、雅诗兰黛TOP3色号累计占比非常之高,达到了90%左右,其中阿玛尼和雅诗兰黛以一个爆款色号俾睨天下,他俩TOP1色号占比高达73%+,YSL算是两驾马车并驾齐驱。MAC和纪梵希集中度在72%+,仍是依靠TOP1色号这个ADC的强大输出控场;DIOR呈现出百花齐放的态势,TOP3色号累计占比仅57.05%,TOP1、TOP2色号分布均匀,消费者在色号选择方面较为自主和独立。
3、最热门色号推荐:
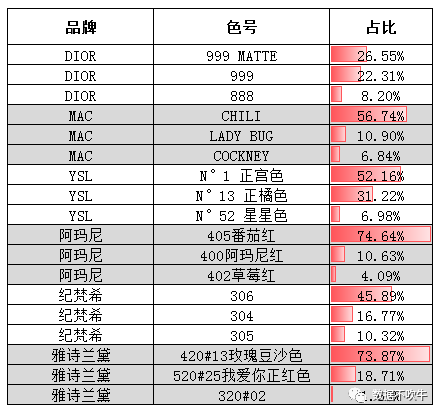
啊!DIOR的999 MATTE,MAC的CHILI,YSL的N°1正宫色,阿玛尼的405番茄红,纪梵希的306还有雅诗兰黛的420#13玫瑰豆沙色。“结论如此一目了然,以至于不用再多分析了”。
附录:
本文主要针对特定品牌特定产品做了评价爬取和分析,感兴趣的旁友们可以结合自己兴趣去做分析,最后附上评论爬取和清洗代码抛砖引玉:
import requests
import pandas as pd
import os
import time
import json
from snownlp import SnowNLP
#定义一个解析单页评论内容的函数
def parse_page(url,headers,cookies):
result = pd.DataFrame()
html = requests.get(url,headers = headers,cookies = cookies)
bs = json.loads(html.text[25:-2])
#循环解析,结果放在result中
for i in bs['rateList']:
content = i['rateContent']
time = i['rateDate']
sku = i['auctionSku']
name = i['displayUserNick']
df = pd.DataFrame({'买家昵称':[name],'评论时间':[time],'内容':[content],'SKU':[sku]})
result = pd.concat([result,df])
return result
#构造网页,需要输入基准的网址和商品总评价数量
def format_url(base_url,num):
urls = []
#如果小于99页,则按照实际页数来循环构造
if (num / 20) < 99:
for i in range(1,int(num / 20) + 1):
url = base_url[:-1] + str(i)
urls.append(url)
#如果评论数量大于99页能容纳的,则按照99页来爬取
else:
for i in range(1,100):
url = base_url[:-1] + str(i)
urls.append(url)
#最终返回urls
return urls
#输入基准网页,以及有多少条评论
def main(url,num):
#定义一个存所有内容的变量
final_result = pd.DataFrame()
count = 1
#构造网页,循环爬取并存储结果
for u in format_url(url,num):
result = parse_page(u,headers = headers,cookies = cookies)
final_result = pd.concat([final_result,result])
print('正在疯狂爬取,已经爬取第 %d 页' % count)
#设置一个爱心的等待时间,文明爬取
count += 1
time.sleep(5.2)
print('为完成干杯!')
return final_result
#情感筛选,只留下大于等于0.6分值的结果
def filter_emotion(df,min_ = 0.6):
scores = []
#判断情感分值
for text in df['内容']:
ob = SnowNLP(text)
score = ob.sentiments
scores.append(score)
df_scores = pd.DataFrame({'情感分值':scores})
df.index = df_scores.index
result = pd.concat([df,df_scores],axis = 1)
#剔除掉没有评论的用户
result = result.loc[result['内容'].str.find('此用户没有填写评论') == -1,:]
#留下大于0.6的分值
result = result.loc[result['情感分值'] >= min_,:]
return result
if __name__ == "__main__":
#找到基准网址,在网页JS文件中找到填写就OK
url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=585140124323&spuId=1136244482&sellerId=3102239719&order=3¤tPage=1'
#伪装headers按照实际情况填写
headers = {'User-Agnet':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6'}
#伪装cookies,最近反爬比较严,最好填入登录的值,并且文明爬取,设置合理的间隔时间
cookies = {'cookie':'这个地方输入自己的cookies'}
#最终执行,这个产品目前只有265条评价,大家根据实际情况酌情填写
df = main(url,num = 265)
#用情感分值来进行清洗
df = filter_emotion(df,min_ = 0.6)
#最后可以把结果存为excel文件的形式
#df.to_excel('XXXX.xlsx')















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









