







BigData,顾名思义就是大数据专栏了,主要是介绍常见的大数据相关的原理与技术实践,从基础到进阶,逐步带大家入门大数据。
? 前情回顾
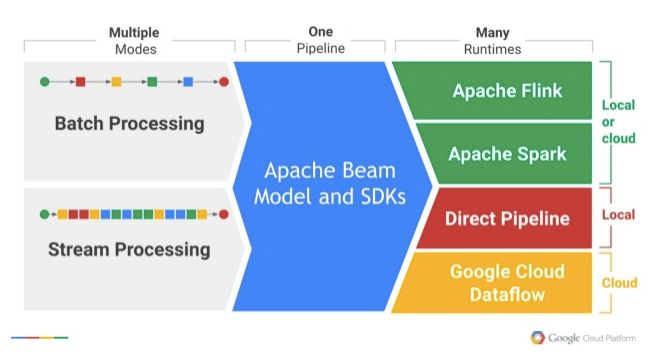
在一开始接触到PCollection的时候,也是一脸懵逼的,因为感觉这个概念有点抽象,除了PCollection,还有PValue、Transform等等,在学习完相关课程之后,也大致有些了解。
首先,PCollection的全称是 Parallel Collection(并行集合),顾名思义那就是可并行计算的数据集,与先前的RDD很相似(输入和输出单元,而且PCollection的创建完全取决于需求,此外,它有比较明显的4个特性(无序性、无界性、不可变性、Coders实现)。
01 无序性
PCollection是无序的,这和它的分布式本质相关,一旦PCollection被分配到不同的机器上执行,为了保证最大的处理输出,不同机器都是独立运行的,因此处理的顺序也就无从得知,因此PCollection并不像我们常用的列表、字典什么等等的有索引,比如list[1]、dict[1]等,
02 无界性
因为Beam设计的初衷就是为了统一批处理和流处理,所以也就决定了它是无界的,也就是代表无限大小的数据集。事实上PCollection是否有界限,取决于它是如何产生的:
-
有界:比如从一个文件、一个数据库里读取的数据,就会产生有界的PCollection
-
无界:比如从Pub/Sub或者Kafka中读取的数据,就会产生无界的PCollection
而数据的有无界,也会影响数据处理的方式,对于有界数据,Beam会使用批处理作业来处理;对于无界数据,就会用持续运行的流式作业来处理PCollection,而如果要对无界数据进行分组操作,会需要一个window来辅助完成统计,这个窗口工具十分常用。
03 不可变性
PCollection是不可变的,也就是说被创建了之后就无法被修改了(添加、删除、更改单个元素),如果要修改,Beam会通过Transform来生成新的Pipeline数据(作为新的PCollection),但不会改变输入的PCollection。
04 Coders实现
Coders是什么意思呢?我们可以理解为方法。Beam要求Pipeline中的每个PCollection都要有Coder,大多数情况下Beam SDK会根据PCollection元素类型或者生成它的Transform来自动推断PCollection的Coder,但有时候也需要开发者自己指定Coder或者开发自定义类型的coder。
为什么PCollection需要Coders呢?因为Coder会在数据处理过程中,告诉Beam如何把数据类型进行序列化和逆序列化,以方便在网络上传输。
apache_beam.coders.registry.register_coder(int, BigEndianIntegerCoder)
? References
百度百科
蔡元楠-《大规模数据处理实战》24 小节 —— 极客时间
Apache Beam编程指南
https://blog.csdn.net/ffjl1985/article/details/78055152
一文读懂2017年1月刚开源的Apache Beam
http://www.sohu.com/a/132380904_465944
Apache Beam 快速入门(Python 版)
https://blog.csdn.net/zjerryj/article/details/77970607















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









