







在没有ajax和不知道前端name的情况下接受post请求的值

Rest Framework
先安装

注册进去
在子应用的views中写个类去继承Rest Framework
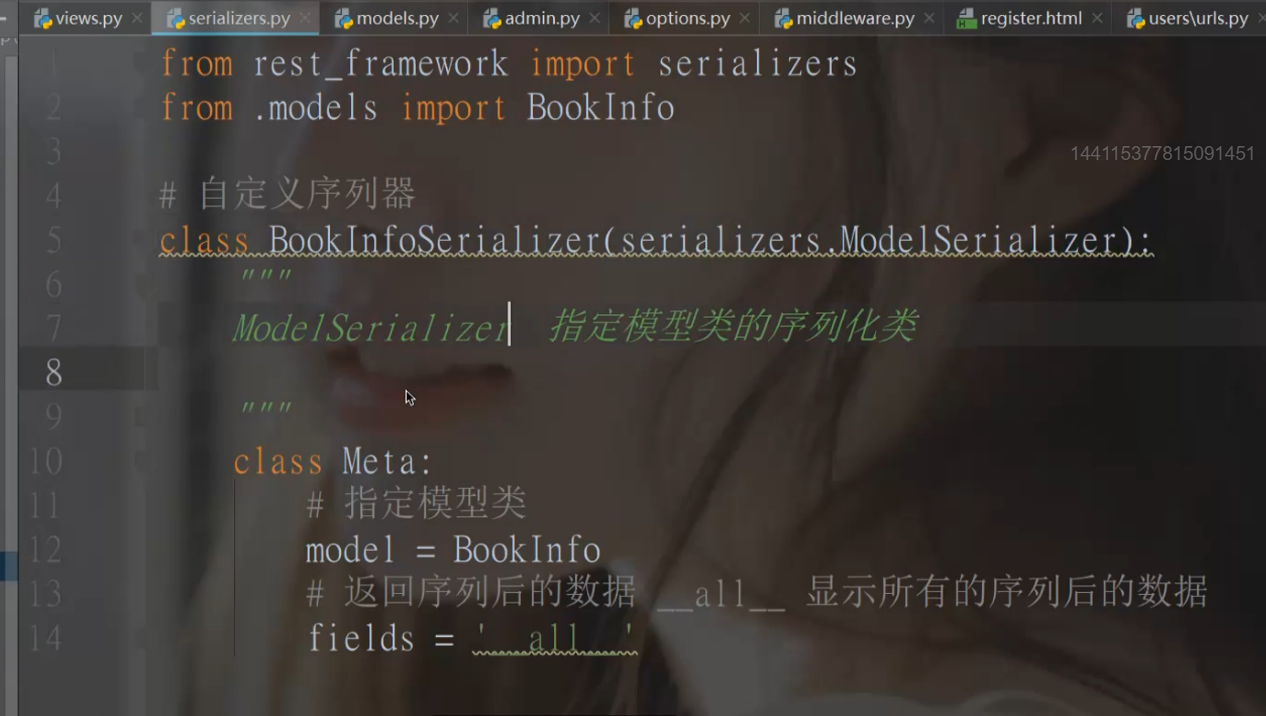
(1)指定一个查询的模型类
(2)等serializers.py里完成序列化后在指定刚刚写好的类
ModeSerializer
在子应用中写一个serializers.py文件去做序列化
fields=('name','put') 指定要做序列化的字段
exclude =('image',) 单独排除这个字段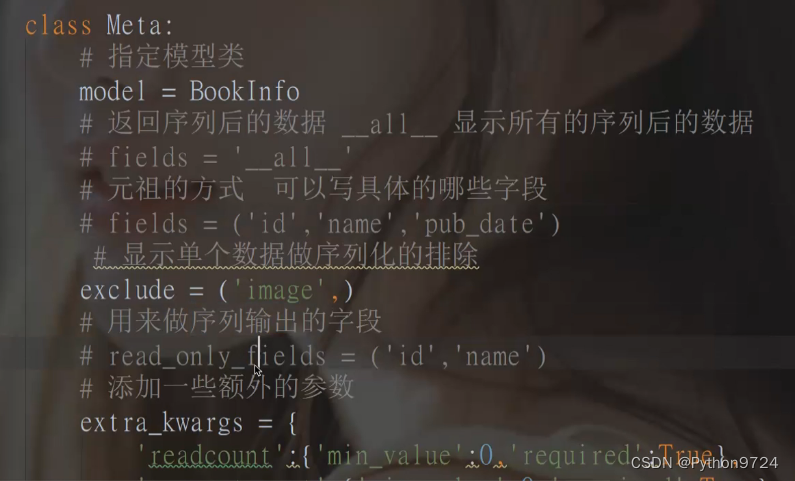
1
对应路由配置在子路由中导入Rest Framework的指定路由

单独注册到uils中
Serializer单独去做序列化
是为了在这判断后直接上到数据库中
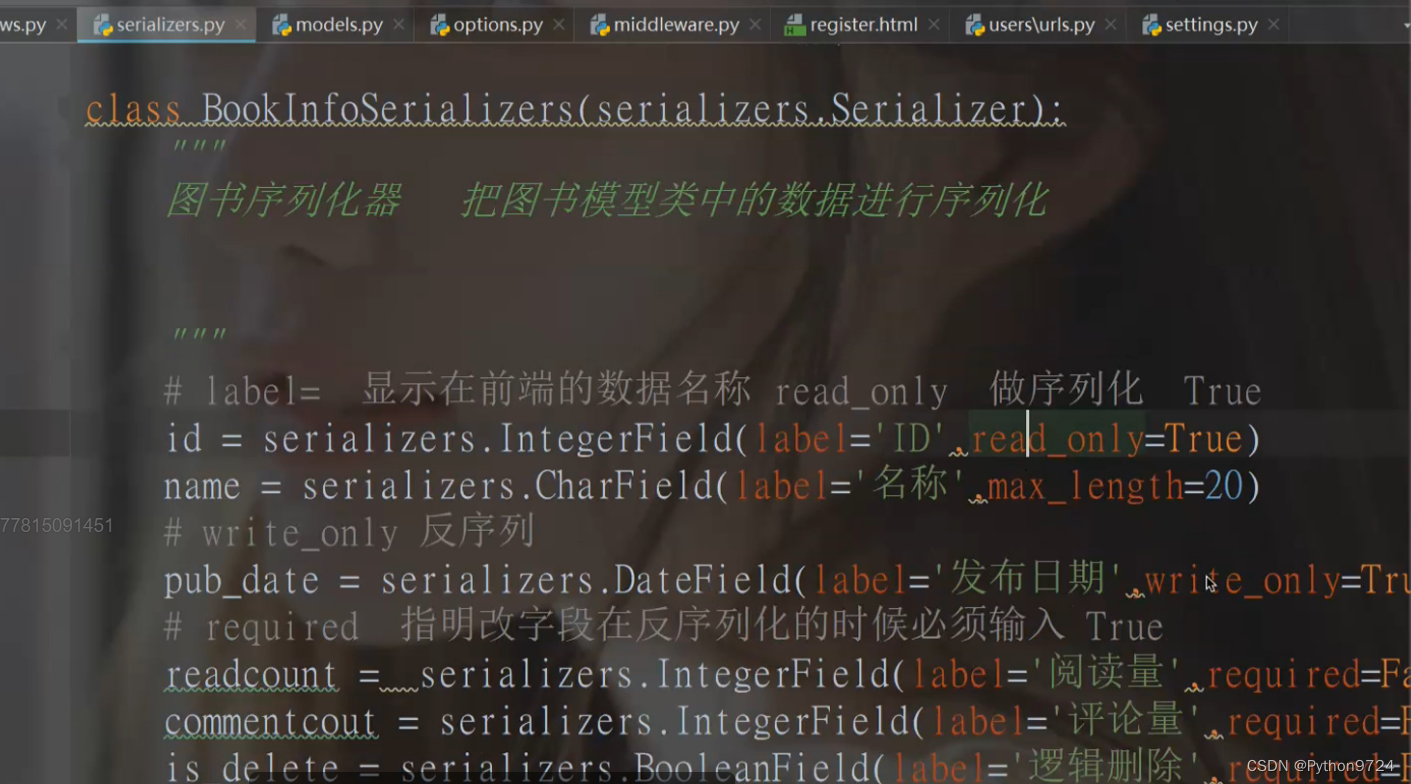
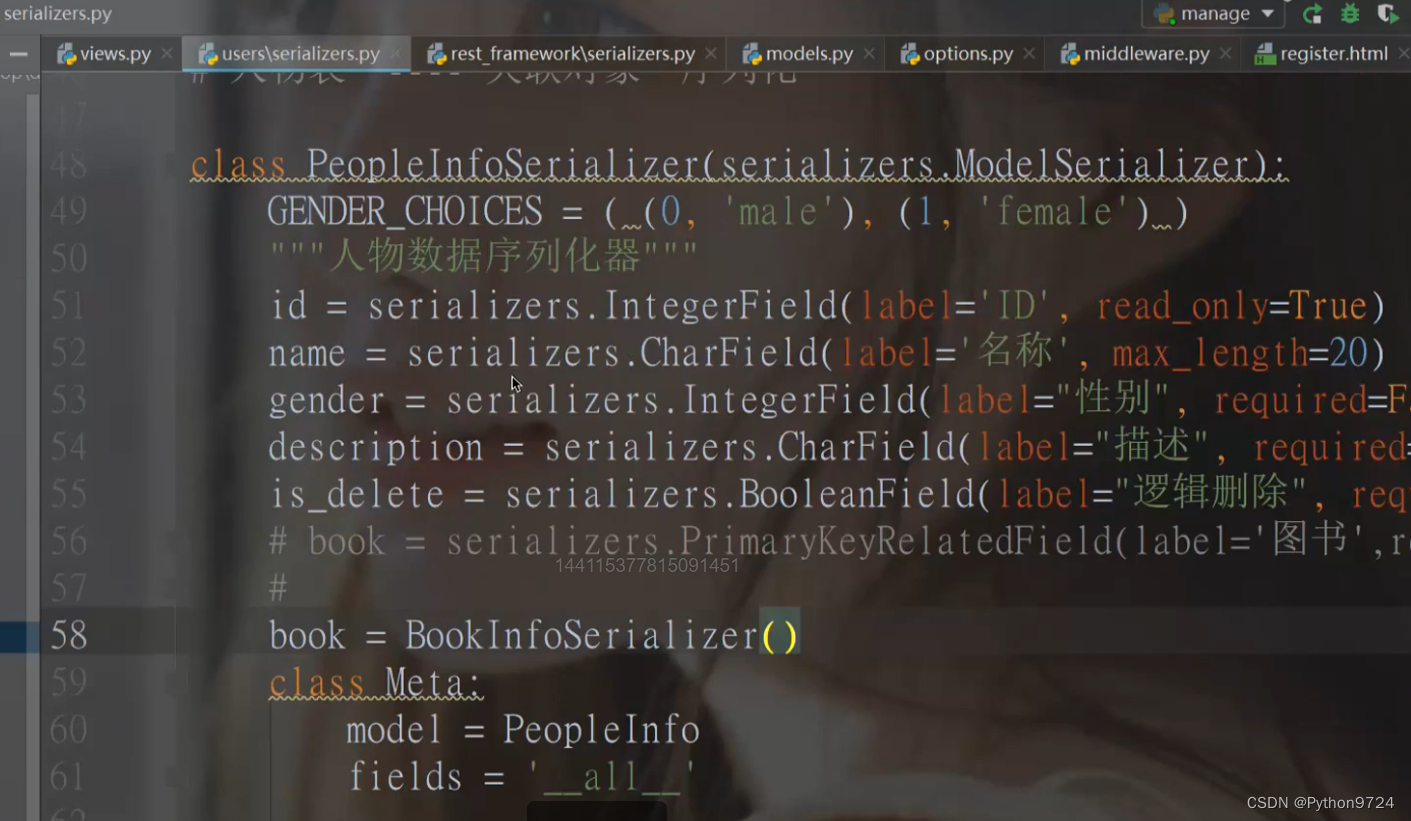
用外键去点上对应的序列化类可以得到全部的数据

## 引入DjangoRESTframework
### 1.Web 应用模式
在开发Web应用中,有两种应用模式:
- 前后端不分离
- 前后端分离
#### 1.1 前后端不分离

在前后端不分离的应用模式中,前端页面看到的效果都是由后端控制,由后端渲染页面或重定向,也就是后端需要控制前端的展示,前端与后端的耦合度很高。
这种应用模式比较适合纯网页应用,但是当后端对接App时,App可能并不需要后端返回一个HTML网页,而仅仅是数据本身,所以后端原本返回网页的接口不再适用于前端App应用,为了对接App后端还需再开发一套接口。
#### 1.2 前后端分离

在前后端分离的应用模式中,后端仅返回前端所需的数据,不再渲染HTML页面,不再控制前端的效果。至于前端用户看到什么效果,从后端请求的数据如何加载到前端中,都由前端自己决定,网页有网页的处理方式,App有App的处理方式,但无论哪种前端,所需的数据基本相同,后端仅需开发一套逻辑对外提供数据即可。
在前后端分离的应用模式中 ,前端与后端的耦合度相对较低。
在前后端分离的应用模式中,我们通常将后端开发的每个视图都称为一个**接口**,或者**API**,前端通过访问接口来对数据进行增删改查。
### 2.认识RESTful
**在前后端分离的应用模式里,后端API接口如何定义?**
- 对于接口的请求方式与路径,每个后端开发人员可能都有自己的定义方式,风格迥异。
- 是否存在一种统一的定义方式,被广大开发人员接受认可的方式呢?
- 这就是被普遍采用的API的RESTful设计风格。
- 例如对于后端数据库中保存了商品的信息,前端可能需要对商品数据进行增删改查,那相应的每个操作后端都需要提供一个API接口:
| 请求方法 | 请求地址 | 后端操作 |
| -------- | -------- | ----------------- |
| GET | /goods | 获取所有商品 |
| POST | /goods | 增加商品 |
| GET | /goods/1 | 获取编号为1的商品 |
| PUT | /goods/1 | 修改编号为1的商品 |
| DELETE | /goods/1 | 删除编号为1的商品 |
#### 2.1 起源
REST这个词,是[Roy Thomas Fielding](http://en.wikipedia.org/wiki/Roy_Fielding)在他2000年的[博士论文](http://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm)中提出的。

Fielding是一个非常重要的人,他是HTTP协议(1.0版和1.1版)的主要设计者、Apache服务器软件的作者之一、Apache基金会的第一任主席。所以,他的这篇论文一经发表,就引起了关注,并且立即对互联网开发产生了深远的影响。
#### 2.2 说明
- RESTful是一种开发理念**,REST是设计风格而不是标准**
- 公司中的后端程序员在定义后端的接口时,可以选择是否遵守这种设计风格;
- RESTful设计风格的API,每种请求方法,都对应后端一种数据库操作。
### 3.RESTful设计方法
#### 3.1 域名
应该尽量将API部署在专用域名之下。
```
https://api.example.com
```
如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
```
https://example.org/api/
```
前后端分离,前端域名和后端域名分开
#### 3.2 版本
应该将API的版本号放入URL。
```
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
```
另一种做法是,将版本号放在HTTP头信息中,但不如放入URL方便和直观。[Github](https://developer.github.com/v3/media/#request-specific-version)采用这种做法。
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URL。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见[Versioning REST Services](http://www.informit.com/articles/article.aspx?p=1566460)):
```
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0
```
#### 3.3 路径(Endpoint)
路径又称"终点"(endpoint),表示API的具体网址,每个网址代表一种资源(resource),也就是路由
**(1) 资源作为网址,只能有名词,不能有动词,而且所用的名词往往与数据库的表名对应。**
举例来说,以下是不好的例子:
`
/getProducts
/listOrders
/retreiveClientByOrder?orderId=1
```
对于一个简洁结构,你应该始终用名词。 此外,利用的HTTP方法可以分离网址中的资源名称的操作。
```
GET /products :将返回所有产品清单
POST /products :将产品新建到集合
GET /products/4 :将获取产品 4
PATCH(或)PUT /products/4 :将更新产品 4
```
**(2) API中的名词应该使用复数。无论子资源或者所有资源。**
举例来说,获取产品的API可以这样定义
```
获取单个产品:http://127.0.0.1:8080/AppName/rest/products/1
获取所有产品: http://127.0.0.1:8080/AppName/rest/products
```
#### 3.4 HTTP动词
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面四个(括号里是对应的SQL命令)。
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- DELETE(DELETE):从服务器删除资源。
还有三个不常用的HTTP动词。
- PATCH(UPDATE):在服务器更新(更新)资源(客户端提供改变的属性)。
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
```
GET /zoos:列出所有动物园
POST /zoos:新建一个动物园(上传文件)
GET /zoos/ID:获取某个指定动物园的信息
PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
DELETE /zoos/ID:删除某个动物园
GET /zoos/ID/animals:列出某个指定动物园的所有动物
DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
```
#### 3.5 过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
```
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
```
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoos/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。通过传参来把过滤的数据传过来
#### 3.6 状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
> - 200 OK - [GET]:服务器成功返回用户请求的数据
> - 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
> - 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
> - 204 NO CONTENT - [DELETE]:用户删除数据成功。
> - 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作
> - 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
> - 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
> - 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
> - 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
> - 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
> - 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
> - 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
状态码的完全列表参见[这里](http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html)或[这里](https://zh.wikipedia.org/wiki/HTTP状态码)。
#### 3.7 错误处理(Error handling)
如果状态码是4xx,服务器就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
```json
{
error: "Invalid API key"
}
```
#### 3.8 返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
- GET /collection:返回资源对象的列表(数组)
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成的资源对象
- PUT /collection/resource:返回完整的资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
#### 3.9 超媒体(Hypermedia API)
RESTful API最好做到Hypermedia(即返回结果中提供链接,连向其他API方法),使得用户不查文档,也知道下一步应该做什么。
比如,Github的API就是这种设计,访问[api.github.com](https://api.github.com/)会得到一个所有可用API的网址列表。
```json
{
"current_user_url": "https://api.github.com/user",
"authorizations_url": "https://api.github.com/authorizations",
// ...
}
```
从上面可以看到,如果想获取当前用户的信息,应该去访问[api.github.com/user](https://api.github.com/user),然后就得到了下面结果。
```json
{
"message": "Requires authentication",
"documentation_url": "https://developer.github.com/v3"
}
```
上面代码表示,服务器给出了提示信息,以及文档的网址。
#### 3.10 其他
服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
### 4.使用Django开发REST接口
我们以在Django框架中使用的图书英雄案例来写一套支持图书数据增删改查的REST API接口,来理解REST API的开发。
在此案例中,前后端均发送JSON格式数据。(注意要关掉Csrf,(注释掉Settings的MIDDLEWARE里面的Csrf))
```python
"""
GET /goods 获取所有商品
POST /goods 增加商品
GET /goods/<pk>/ 获取编号为1的商品
PUT /goods/<pk>/ 修改编号为1的商品
DELETE /goods/<pk>/ 删除编号为1的商品
响应数据 JSON
列表视图:路由后面没有pk/ID
详情视图:路由后面 pk/ID
"""
from django.views import View
class BookListView(View):
"""列表视图"""
def get(self, request):
"""查询所有图书接口"""
pass
def post(self, request):
"""新增图书接口"""
pass
class BookDetailView(View):
"""详情视图"""
def get(self, request, pk):
"""查询指定某个图书接口"""
pass
def put(self, request, pk):
"""修改指定某个图书接口"""
pass
def delete(self, request, pk):
"""删除指定某个图书接口"""
pass
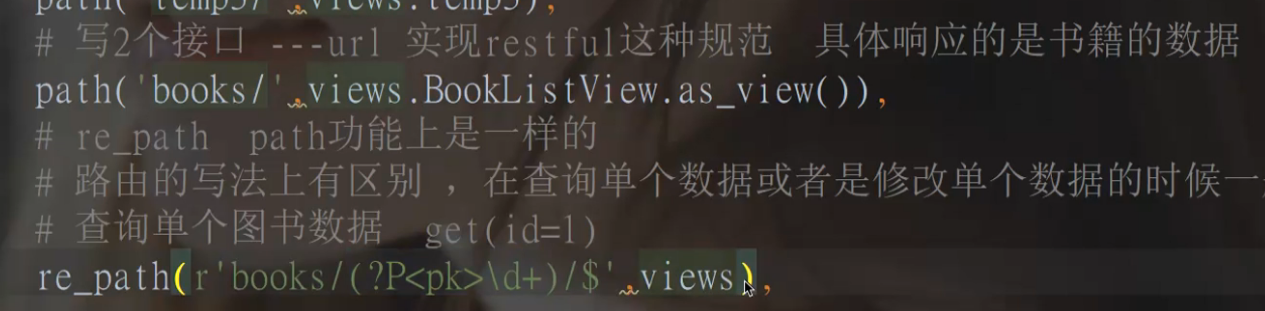
# from django.urls import path, re_path
# path('books/',views.BookListView.as_view())
# re_path(r'^books/(?P<pk>\d+)/$',views.BookDetailView.as_view())
# 为什么要分成两个类视图?
1.一个类里面不能有两个get
2.路由定义是列表视图没有PK,详情视图有pk
``
详细实现
```python
from django.views import View
class BookListView(View):
"""列表视图"""
def get(self, request):
"""查询所有图书接口"""
# 1.查询所有图书接口
books = BookInfo.objects.all()
# 2. 遍历查询集,取出每个书籍模型对象,把模型对象转换成字典
# 定义一个列表变量用来保存所有字典
book_list = []
for book in books:
book_dict = {
# 通过键获取值
'id': book.id,
'name': book.name,
'pub_date': book.pub_date,
'readcount': book.readcount,
'commentcount': book.commentcount,
'image': book.image.url if book.image else ''
}
book_list.append(book_dict)
# 响应
print(book_list)
return JsonResponse(book_list, safe=False)
# return JsonResponse("你好", safe=False)
def post(self, request):
"""新增图书接口"""
# 获取前端传入的请求体数据
json_bytes = request.body
# 把bytes类型的json字符串转换成json_str
json_str = json_bytes.decode()
# 将json字符串转换成字典
book_dict = json.loads(json_str)
# 创建模型对象并保存(把字典转换成模型并存储)
book = BookInfo.objects.create(
name=book_dict['name'],
pub_date=book_dict['pub_date']
)
book_dict = {
'id': book.id,
'pub_date': book.pub_date,
'readcount': book.readcount,
'commentcount': book.commentcount,
'image': book.image.url if book.image else ''
}
return JsonResponse(book_dict, status=201)
class BookDetailView(View):
"""详情视图"""
def get(self, request, pk):
"""查询指定某个图书接口"""
# 1.获取出指定pk的那个模型对象
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse({"message", "查询的数据不存在"}, status=404)
# 2.模型对象转字典
book_dict = {
'id': book.id,
'pub_date': book.pub_date,
'readcount': book.readcount,
'commentcount': book.commentcount,
'image': book.image.url if book.image else ''
}
return JsonResponse(book_dict, safe=False)
def put(self, request, pk):
"""修改指定某个图书接口"""
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse({"message", "查询的数据不存在"}, status=404)
# 获取前端传入的请求体数据
json_bytes = request.body
# 把bytes类型的json字符串转换成json_str
json_str = json_bytes.decode()
# 将json字符串转换成字典
book_dict = json.loads(json_str)
# 重新给模型对象赋值
book.name = book_dict['name']
book.pub_date = book_dict['pub_date']
# 调用save方法进行修改操作
book.save()
json_dict = {
'id': book.id,
'name': book.name,
'pub_date': book.pub_date,
'image': book.image.url if book.image else ''
}
# 响应
return JsonResponse(json_dict)
def delete(self, request, pk):
"""删除指定某个图书接口"""
# 获取要删除的模型对象
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return HttpResponse({"message", "查询的数据不存在"}, status=404)
# 删除模型对象
book.delete() # 物理删除(真正从数据库中删除)
# book.is_delete = True
# book.save() # 逻辑删除
# 响应:删除时不需要有响应体但要指定状态码为 204
return HttpResponse(status=204)
```
查询效果:

单个查询:

新增效果


修改效果:

删除效果:

可以发现,在开发REST API接口时,视图中做的最主要有三件事:
- 将请求的数据(如JSON格式)转换为模型类对象
- 操作数据库
- 将模型类对象转换为响应的数据(如JSON格式)
## DRF 工程搭建
### 1.DRF 介绍
1. 在序列化与反序列化时,虽然操作的数据不尽相同,但是执行的过程却是相似的,也就是说这部分代码是可以复用简化编写的。
2. 在开发REST API的视图中,虽然每个视图具体操作的数据不同,但增、删、改、查的实现流程基本套路化,所以这部分代码也是可以复用简化编写的:
- **增**:校验请求数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
- **删**:判断要删除的数据是否存在 -> 执行数据库删除
- **改**:判断要修改的数据是否存在 -> 校验请求的数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
- **查**:查询数据库 -> 将数据序列化并返回
3.DRF将序列化和反序列化的业务逻辑进⾏了封装,程序员只需要将序列化和反序列化的数据传给DRF即可
**Django REST framework可以帮助我们简化上述两部分的代码编写,大大提高REST API的开发速度。**
**认识Django REST framework**

Django REST framework 框架是一个用于构建Web API 的强大而又灵活的工具。
通常简称为DRF框架 或 REST framework。
DRF框架是建立在Django框架基础之上,由Tom Christie大牛二次开发的开源项目。
**特点**
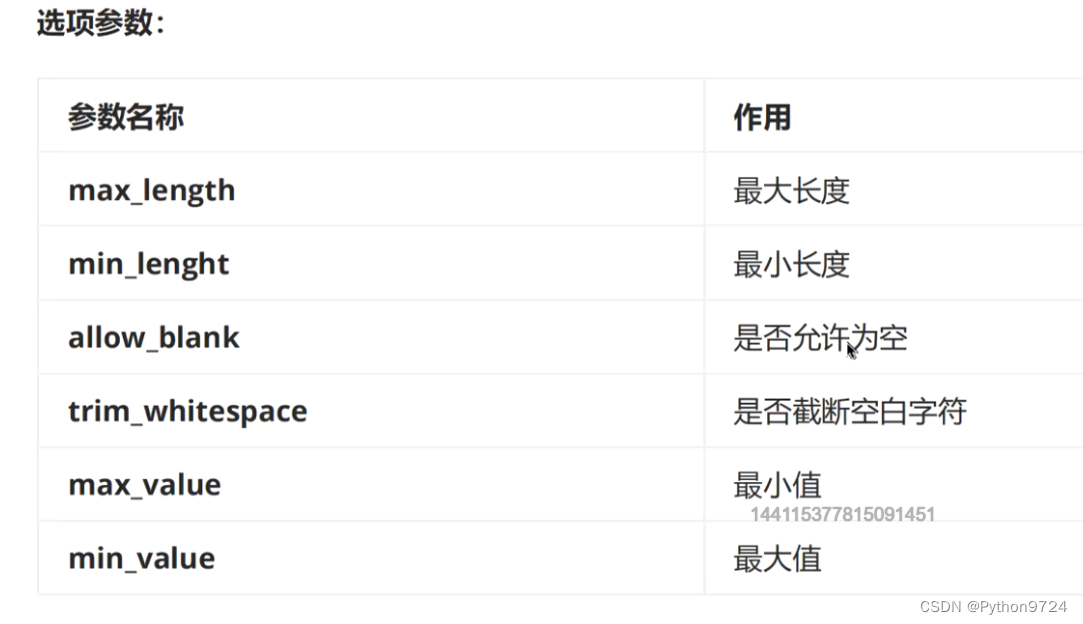
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
- 多种身份认证和权限认证方式的支持;
- 内置了限流系统;
- 直观的 API web 界面;
- 可扩展性,插件丰富
资料:
- [官方文档](http://www.django-rest-framework.org/)
- [Github源码](https://github.com/encode/django-rest-framework/tree/master)
### 2.环境安装与配置
DRF需要以下依赖:
- Python (3.5, 3.6, 3.7, 3.8, 3.9)
- Django (2.2, 3.0, 3.1)
**DRF是以Django扩展应用的方式提供的,所以我们可以直接利用已有的Django环境而无需从新创建。(若没有Django环境,需要先创建环境安装Django)**
**1. 安装DRF**
```shell
pip install djangorestframework
```
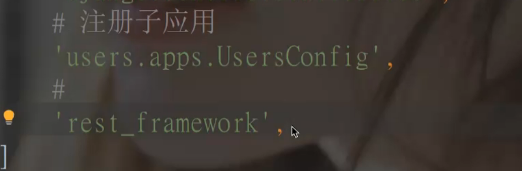
**2. 添加rest_framework应用**
我们利用在Django框架学习中创建的demo工程,在**settings.py**的**INSTALLED_APPS**中添加'rest_framework'。
```python
INSTALLED_APPS = [
...
'rest_framework',
]
```
接下来就可以使用DRF进行开发了。
### 3.见识DRF的魅力
我们仍以在学习Django框架时使用的图书英雄为案例,使用Django REST framework快速实现图书的REST API。
#### 3.1 创建序列化器
在booktest应用中新建serializers.py用于保存该应用的序列化器。
创建一个Serializer.py文件,再创建一个BookInfoSerializer用于序列化与反序列化。
```python
from rest_framework import serializers
from book.models import BookInfo #
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = '__all__'
```
- **model** 指明该序列化器处理的数据字段从模型类BookInfo参考生成
- **fields** 指明该序列化器包含模型类中的哪些字段,'__all__'指明包含所有字段
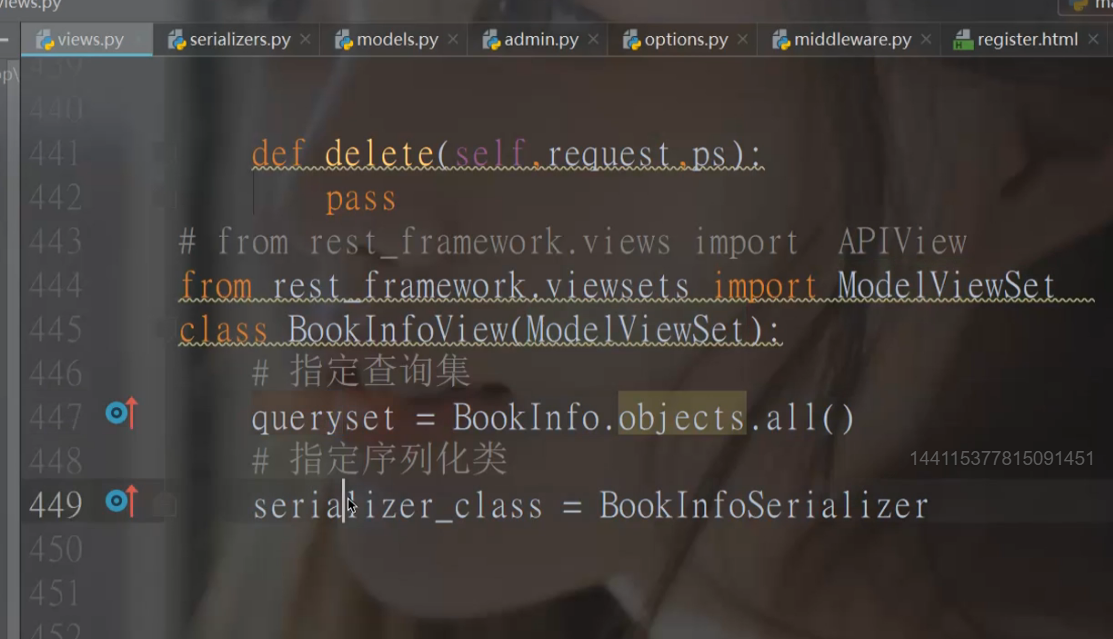
#### 3.2 编写视图
在booktest应用的views.py中创建视图BookInfoViewSet,这是一个视图集合。
```python
from .models import BookInfo
from rest_framework.viewsets import ModelViewSet
from book.serializer import BookInfoSerializer
class BookInfoView(ModelViewSet):
"""定义类视图"""
"""指定查询集"""
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
```
- **queryset** 指明该视图集在查询数据时使用的查询集
- **serializer_class** 指明该视图在进行序列化或反序列化时使用的序列化器
#### 3.3 定义路由
在book应用的urls.py中定义路由信息。
```python
from book import views
from rest_framework.routers import DefaultRouter
urlpatterns = [
# path('books/', views.BookListView.as_view()),
# re_path(r'^books/(?P<pk>\d+)/$', views.BookDetailView.as_view())
]
router = DefaultRouter() # 可以处理视图的路由器
router.register(r'books', views.BookInfoView) # 向路由器中注册视图集
urlpatterns += router.urls # 将路由器中的所以路由信息追到到django的路由列表中
```
注意:要将前面写的对应路由注释,否则以之前写的为准
#### 3.4. 运行测试
运行当前程序(与运行Django一样)
```shell
python manage.py runserver
```
在浏览器中输入网址127.0.0.1:8000,可以看到DRF提供的API Web浏览页面:

1)点击链接127.0.0.1:8000/books/ 可以访问**获取所有数据的接口**,呈现如下页面:


2)在页面底下表单部分填写图书信息,可以访问**添加新图书的接口**,保存新书

点击POST后,返回如下页面信息:

3)在浏览器中输入网址127.0.0.1:8000/books/1/,可以访问**获取单一图书信息的接口**(id为1的图书),呈现如下页面:

4)在页面底部表单中填写图书信息,可以访问**修改图书的接口**:

点击PUT,返回如下页面信息:

5)点击DELETE按钮,可以访问**删除图书的接口**:

返回,如下页面:

至此,是不是发现Django REST framework很好用!

















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









