






01 产业链?我看是新的战场态势图!
讲真,现在谁要是还把AI大模型这摊子事儿,仅仅看成一条冷冰冰的“产业链”,那格局可就小了去了。在我这老兵痞眼里,这哪是什么按部就班的链条?这分明就是一张瞬息万变的数字战场态势图!每家公司,每个技术节点,都跟战场上的火力点、兵工厂、情报站似的,互相盯着,互相较劲,也互相依赖。谁要是打个盹,分分钟就可能被对手端了老窝!
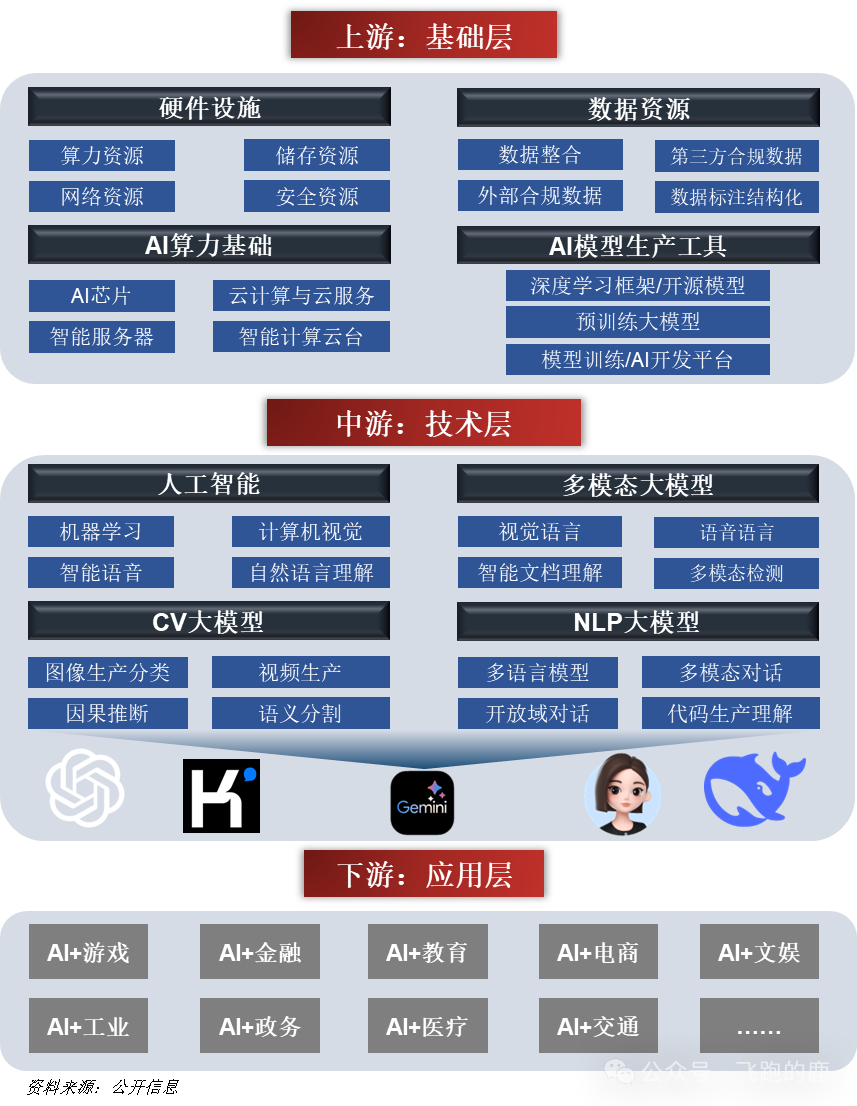
02 AI大模型?听着玄乎,其实就是个能吃能拉的“数据巨兽”
02-1 这“巨兽”肚子里到底装的啥?
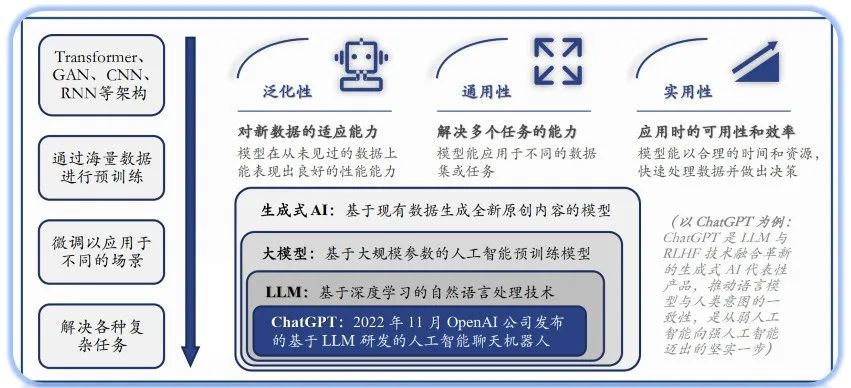
AI大模型,这名头听着挺唬人,参数动不动就十亿百亿往上堆,结构复杂得跟迷宫似的。说白了,不就是个超级能吃数据的“怪兽”嘛!扔给它海量信息,它就能鼓捣出点名堂,什么自然语言处理、图像识别,听着都挺高级。但你得明白,这玩意儿的胃口,可不是一般的大。而且,吃进去的是不是“干净”的?拉出来的是不是“有毒”的?这才是咱们网络安全圈里人,真正要瞪大眼睛瞅的地儿!
02-2 这“巨兽”有三板斧,但别光看贼吃肉...
这“数据巨兽”啊,主要靠三招鲜吃遍天:
- 海量数据投喂:没日没夜地吞数据,越多越好,越杂越“聪明”——至少它们是这么宣传的。可数据来源的合法性、隐私性、偏见性,谁来把关?这简直就是给未来的数据泄露和算法歧视埋雷!
- 复杂算法调教:各种高深莫测的算法模型,像个黑箱子,工程师们往里头塞参数,指望它能“悟道”。可这“道”是正道还是邪道?万一被黑客摸透了算法的“脾气”,植入个后门,那乐子可就大了。
- 强大算力硬扛:没有强大的算力,这“巨兽”就是个病猫。所以,GPU、TPU玩儿命地堆。但算力本身也成了新的攻击目标,DDoS攻击能瘫痪你,挖矿木马能偷你算力,防不胜防啊!
02-3 分门别类?哼,万变不离其“数据依赖”的宗!
市面上把这些大模型分成了好几类,什么NLP(自然语言处理)大模型、CV(计算机视觉)大模型、多模态大模型,还有科学计算大模型。听着挺热闹,对吧?
但在我看来,甭管它贴着什么标签,骨子里都是一路货色——极度依赖数据,也极度暴露数据风险。NLP模型可能泄露你的聊天记录,CV模型可能滥用你的人脸信息,多模态更是把各种隐私搅和在一起。你以为你在享受便捷?说不定早就在“裸奔”了!
02-4 算力、算法、数据——三足鼎立,还是互相掣肘的“铁三角”?
有人说,算力、算法、数据是AI大模型的三大基石,缺一不可。这话没错,但从另一个角度看,这仨玩意儿也可能是互相拖后腿的“猪队友”。
- 算力是发动机,没它模型跑不起来。但光有蛮力,算法跟不上,数据质量差,那就是“傻快傻快的”,有啥用?
- 算法是大脑,决定模型怎么思考。可算法再牛,没有足够的数据喂,没有强劲的算力支撑,那也是“巧妇难为无米之炊”。
- 数据是燃料,决定模型能学到啥。但数据再多,算法垃圾,算力孱弱,那就是“一堆废铜烂铁”。
更要命的是,这三个环节,哪个环节出了安全纰漏,整个模型体系都可能跟着遭殃。预训练阶段被投毒?微调阶段被污染?推理阶段被窃取?想想都头皮发麻!
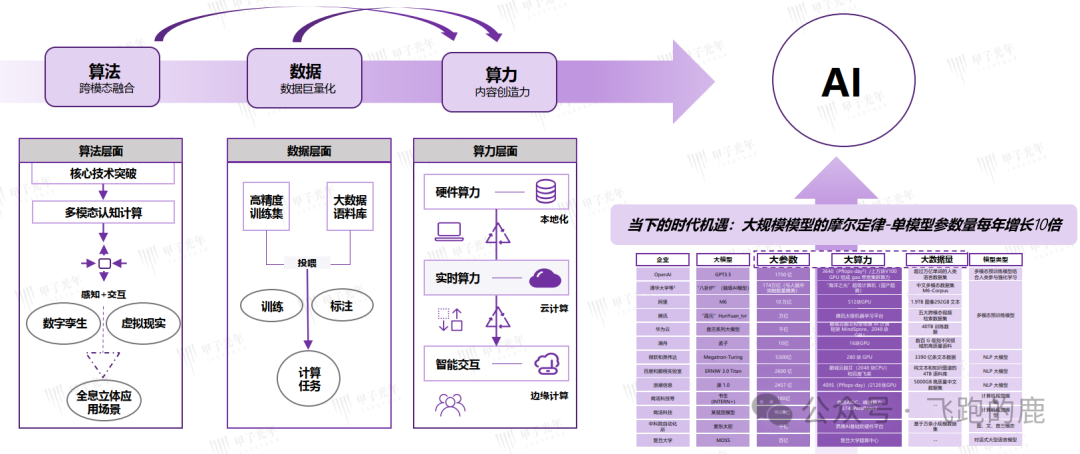
看看这张图,预训练、微调、推理,哪个不是在刀尖上跳舞?每一步都可能成为攻击者的突破口。
03 上游那点事儿:谁在给这“巨兽”添柴加火?
所谓上游,不就是给这“数据巨兽”提供“粮草弹药”的嘛!算力、算法、数据,这三样东西,每一件背后都水深得很。
03-1 算力:没它不行,但“力大砖飞”也可能砸了自己的脚!
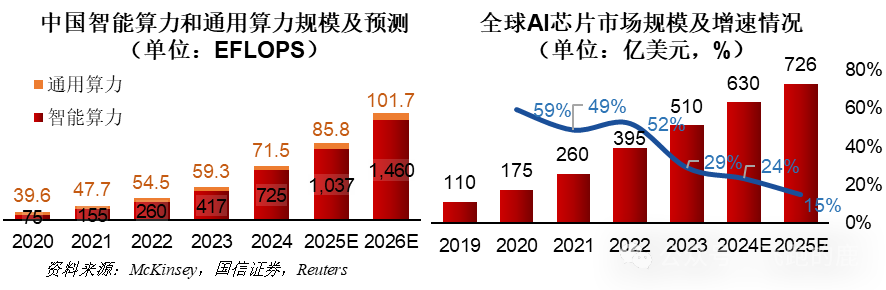
- AI大模型简直是算力的“吞金兽”:他们说啊,到2025年,AI大模型对算力的需求,能翻到2020年的10倍!这里头,超过一半的需求来自企业。啧啧,这得烧多少钱?更关键的是,这么多算力集中起来,一旦被黑客盯上,那可就是“核弹级”的破坏力!
- 芯片市场?那是NVIDIA的后花园,国产替代路漫漫:现在全球高性能AI芯片,NVIDIA一家就占了八成以上!A100、H100这些尖货,简直是有钱都买不到,价格炒上了天。国内的华为昇腾、寒武纪、壁仞这些,虽然也在玩命追,但想从牙缝里抢食,难啊!他们预计2025年国产芯片能占到30%?我看悬,这不仅仅是技术问题,更是生态和信任的问题。
- 云计算巨头们的算力“军备竞赛”:2023年全球AI云算力市场,AWS、Azure、Google Cloud这三家就瓜分了七成多。国内的阿里云、华为云、腾讯云也在疯狂砸钱扩军。阿里云说未来三年要投524亿美元搞AI算力,听着都吓人。但问题是,这些云平台自身的安全性如何?会不会成为下一个“数据泄露集中营”?
- AI算力服务商,花样越来越多,水也越来越浑:以前可能就是卖卖服务器,现在呢?产品和服务搞得越来越复杂,什么异构计算、液冷散热,听着高大上。但越复杂,潜在的漏洞和攻击面就越多。市场多样性是好事,但别成了“浑水摸鱼”的天堂。

03-2 算法:模型的“大脑”,还是精心编织的“迷魂阵”?
算法这玩意儿,说是AI大模型的“灵魂”也不为过。但这个“灵魂”到底是纯洁的,还是藏着掖着什么猫腻?
- Transformer架构?确实牛,但也可能被“反向工程”:2017年Google搞出来的Transformer,的确给AI界带来了革命。计算效率比老掉牙的RNN提升了10倍不止。但你想想,这么核心的技术,一旦其运作机理被攻击者完全吃透,是不是就能针对性地构造攻击样本,让模型“指鹿为马”?
- 算法优化能省钱?小心“省”出新风险!:GPT-4训练一次据说要花1亿多美刀,这谁受得了?所以,稀疏化、蒸馏、量化这些技术就出来了,号称能把训练成本降低30%-50%。听着很美,但这些“阉割版”的算法,会不会在安全性上打折扣?会不会更容易受到对抗性攻击?这都是未知数。
- 开源 vs. 专有?安全风险半斤八两!
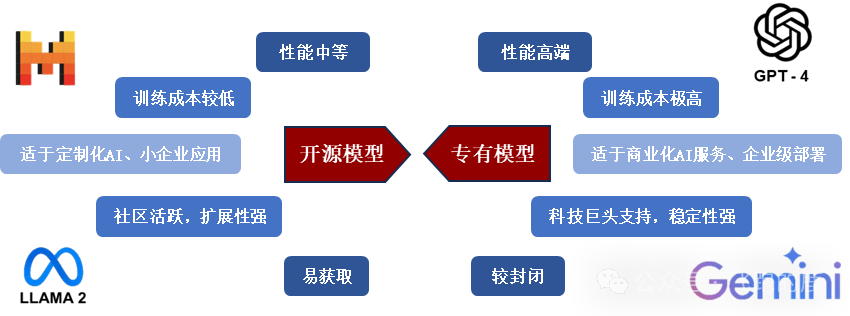
这张表列了开源和专有模型的优劣。开源模型,代码给你看, вроде透明,但也意味着漏洞更容易被发现和利用。专有模型呢,藏着掖着,你不知道里面有什么“私货”,万一开发者留了后门,或者算法本身就有缺陷,用户根本无从知晓。所以啊,别迷信谁比谁更安全,关键还是看背后的安全审计和持续的漏洞管理。 - 前沿算法?听着酷炫,安全隐患可能更隐蔽!:2023年,多模态大模型火了,能处理文字、图像、音频、视频。强化学习(RLHF)也号称能提升AI的交互能力。但你想想,处理的数据类型越多,潜在的攻击向量是不是也越多?交互能力越强,是不是也更容易被诱导说出不该说的话,或者执行危险的操作?
- 算法从“实验室”到“大街上”,安全测试跟上了吗?
这张图说的是算法怎么从技术走向应用。但我想问的是,在这个过程中,有多少是经过了严格、独立、第三方的安全评估和渗透测试的?别光想着怎么赚钱,安全这根弦松了,早晚要出大事!
03-3 数据:“饲料”决定“猛兽”?隐私和偏见这俩“幽灵”可一直没走远!
数据,AI大模型的“口粮”。这“口粮”的质量、来源、处理方式,直接决定了训练出来的模型是“神兽”还是“恶兽”。

- “垃圾进,垃圾出”,这道理几千年了还颠扑不破!:研究都说了,90%的AI模型表现拉胯,问题都出在数据质量上,而不是模型结构有多烂。这简直是常识,但总有人揣着明白装糊涂,用一堆“脏数据”去喂模型,结果呢?训练出来的模型,要么蠢得要死,要么坏得流油。
- 数据来源越“杂”,模型越“聪明”?也可能越“危险”!:GPT-4用了文本和图像,Google的PaLM2更是文本、图像、音频大杂烩。看起来很全能,但数据来源的多样性,也意味着引入了更多潜在的风险点。某个来源的数据被污染了怎么办?某个来源的数据带有强烈的偏见怎么办?模型学坏了,责任算谁的?
- 用AI清洗数据?“监守自盗”的风险考虑过吗?:现在流行用AI技术来加速数据清洗和预处理,比如自监督学习、异常值检测、自动标注。听起来很高效,但如果用来清洗数据的AI本身就有漏洞,或者被恶意操纵了呢?那不就是“引狼入室”?

看看这流程,Tokenization(分词)、Embeddings(嵌入),每个环节都可能引入新的安全问题。比如,恶意的Token序列会不会导致模型崩溃?精心构造的Embedding会不会触发模型的隐藏后门?这些都是需要警惕的。
还有,别忘了那个《“数据要素X”三年行动计划(2024-2026 年)》。国家层面都在推数据要素化,市场规模眼瞅着要破两千亿。
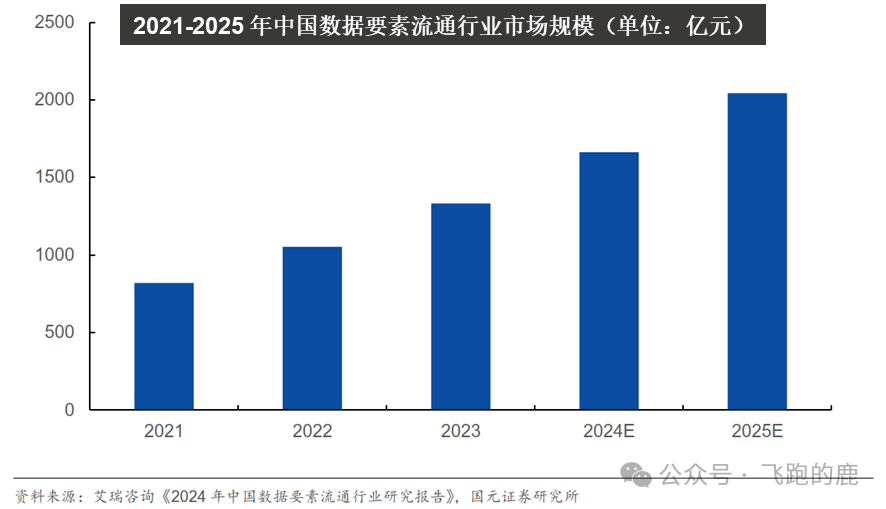
这数字看着喜人,但背后是多少敏感数据在流动?从数据采集、加工、管理,到市场流通、应用,哪个环节不需要严密的安全防护?
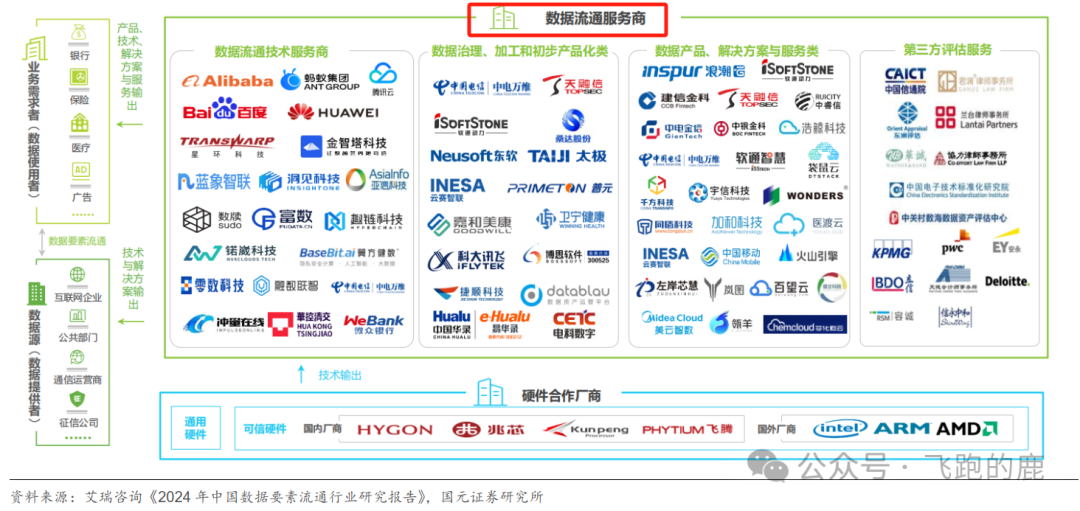
这链条拉得越长,参与方越多,安全风险就越难控制。什么第三方服务机构,咨询审计、评估仲裁,听着挺专业,但谁能保证他们自己就是“干净”的?数据安全,绝对不能只停留在口号上!
04 中游混战:“百模大战”?我看是“百团大混战”,谁能笑到最后?
中游这块儿,就是各路神仙大显神通,把上游的算力、算法、数据捏合成一个个具体的“大模型”。现在都说“百模大战”,我看啊,更像是没头苍蝇似的“百团大混战”,热闹是热闹,但真正能打的、能活下来的,有几个?
04-1 洋玩意儿 vs 土特产:掰掰手腕,看看谁的“肌肉”更硬?(国际篇)
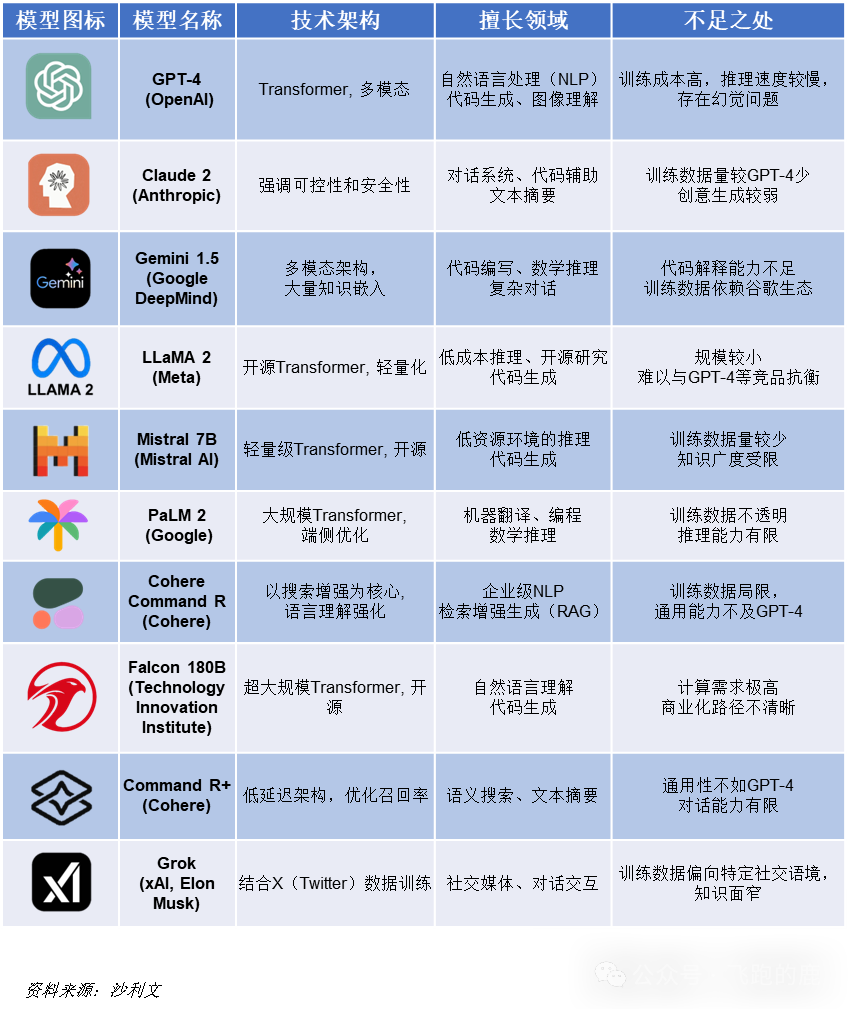
瞧瞧这国际赛场上的选手们:OpenAI的GPT系列,Google的Gemini、PaLM,Meta的Llama,Anthropic的Claude。个个都吹得神乎其神,参数一个比一个大,功能一个比一个炫。但说到底,这些“洋玩意儿”的核心技术和数据,咱们能有多少掌控力?万一哪天人家不高兴了,直接“断供”,咱们是不是就得抓瞎?更别提这些模型在训练过程中,可能存在的针对特定区域的偏见和潜在的“文化后门”了。
04-2 洋玩意儿 vs 土特产:掰掰手腕,看看谁的“肌肉”更硬?(本土篇)

再看看咱们国内的“土特产”:百度的文心、阿里的通义、华为的盘古、科大讯飞的星火、智谱的ChatGLM,还有月之暗面的Kimi。看起来也是百花齐放,热闹非凡。但问题是,这里面有多少是真正自主可控的创新?有多少是在别人的地基上盖房子?在核心算法、高质量数据集、以及高端芯片这些“命根子”上,咱们跟国际巨头比,差距到底有多大?别光看发布会上的PPT,真刀真枪拉出来遛遛,能不能扛得住压力测试和安全审计,这才是关键!而且,国内这些模型,同质化竞争是不是太严重了点?大家都挤在一个赛道里卷,有意思吗?
05 下游应用:AI这把“万能钥匙”,真能打开所有行业的“锁”?别太天真!
都说AI大模型是未来的“万能钥匙”,能赋能千行百业,创造无限可能。市场规模也吹得天花乱坠,2022年中国人工智能行业3716亿,预计2027年能到15372亿,听着跟捡钱似的。
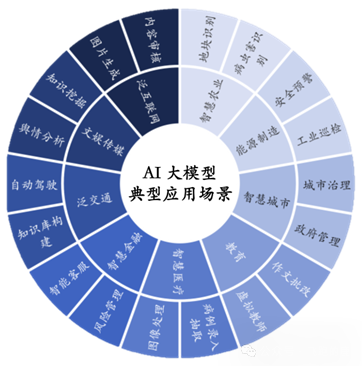
制造、交通、金融、医疗……恨不得所有行业都给它“AI+”一遍。但我想说,步子迈得太大,容易扯着淡!每个行业都有自己的特殊性,都有自己敏感的数据和业务逻辑。AI这把钥匙,用不好,可能撬开的是潘多拉的魔盒!
05-1 AI + 医疗:是“赛博华佗”还是“数字庸医”?隐私这道坎怎么过?
人工智能用到医疗上,听起来很美:提高效率、辅助诊断、研发新药、健康管理。好像“赛博华佗”马上就要降临了。但冷静想想,医疗数据是什么?那是比你银行卡密码还私密的个人信息!这些数据交给AI去“学习”,万一泄露了怎么办?万一AI的诊断出了错,责任算谁的?医疗影像、手术机器人,这些高科技玩意儿,如果被黑客入侵控制了,后果不堪设想!“数字庸医”误人性命,可不是闹着玩的。
05-2 AI + 金融:是“智能提款机”还是“高科技韭菜收割机”?风险控制可不是闹着玩的!
金融行业嘛,数据量大,有钱,对信息安全要求也高,所以AI用得早。营销、合规、风控,好像AI都能插一脚。
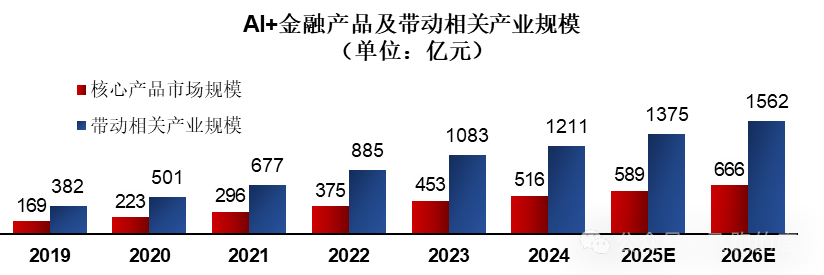
但金融这行当,玩的就是心跳和风险。AI如果被用来进行更精准的“用户画像”,是不是也可能被用来更高效地“割韭菜”?智能投顾如果出现误判,导致用户巨额亏损,谁来买单?AI驱动的量化交易如果被恶意操纵,会不会引发市场动荡?别忘了,再智能的系统,也可能存在漏洞,也可能被内部人员滥用。风险控制这根弦,在金融领域,一刻都不能松!
05-3 AI + 物流:提高效率是真,但数据泄露的“快递”可千万别送到家!
AI在物流领域的应用,什么智能仓储、路径优化、无人配送,听起来确实能降本增效。但物流系统掌握着大量的货物信息、收发件人信息、家庭住址、联系方式。这些数据一旦泄露,不仅是个人隐私的灾难,甚至可能被犯罪分子利用,进行精准诈骗或者入室盗窃。所以,在享受AI带来的便利时,务必盯紧了数据安全这道闸门,别让数据泄露的“毒包裹”送到用户手上。
06 未来趋势?我看是“机遇与陷阱齐飞,创新与监管赛跑”!
展望未来,AI大模型这玩意儿,肯定还会继续折腾。但别光盯着那些光鲜亮丽的“机遇”,脚底下的“陷阱”也得看清楚了!
06-1 技术“内卷”与“跨界打劫”:还能玩出什么新花样?
- 多模态融合?我看是“风险叠加”!:以后的大模型,肯定不满足于只处理文字,图像、音频、视频都得招呼上。交互能力是强了,但不同类型数据的安全风险也跟着融合、叠加了。一个环节出问题,可能导致整个多模态系统崩溃或者被利用。
- 强化学习+人类反馈?小心“养虎为患”!:用强化学习和人类反馈来优化模型,听起来能让AI更“懂事”。但如果反馈机制被污染,或者人类的偏见被模型学了去,那训练出来的AI,会不会越来越像个“精致的利己主义者”,甚至学会欺骗和操纵?
- 算法优化降成本?安全预算可别跟着降!:稀疏化、量化、模型压缩这些技术,能让模型跑得更快、更省钱。但这种“瘦身”会不会牺牲掉模型的鲁棒性和安全性?会不会让模型更容易受到微小的扰动攻击?降本增效是好事,但安全投入这块,一分钱都不能省!
06-2 商业模式大洗牌:谁会是下一个“卖铲子的”?
- MaaS(模型即服务)?小心“服务商跑路”!:以后啊,大模型可能就像水电煤一样,通过API接口提供服务。开发门槛是低了,但你也把自己的业务命脉交给了服务商。万一服务商的安全性不过关,或者干脆倒闭了,你的业务是不是也得跟着瘫痪?
- 生态开放?当心“引狼入室”!:各家厂商都在搞开源、搞合作,想把生态做大。开放是好事,能促进创新。但也可能把安全边界模糊化,让攻击者更容易找到可乘之机。你以为是盟友,说不定就是个“特洛伊木马”。
- 行业大模型定制化?“小而美”也可能“小而脆”!:针对特定行业搞定制化大模型,听起来能更好地满足需求。但这些“小众”模型,在安全投入和攻防经验上,可能远不如那些通用大模型。一旦被盯上,可能更容易被攻破。
06-3 铁笼子越扎越紧:政策、伦理、安全,一个都不能少!
- 监管只会越来越严,别想钻空子!:AI大模型搞出来的幺蛾子越多,政府的监管肯定会越收越紧。生成式AI的内容合规、数据隐私保护、算法伦理审查,这些都是高压线,谁碰谁倒霉。
- 伦理和可持续发展?别光喊口号!:AI技术不能没有“人性”。如果搞出来的AI加剧社会不公、歧视特定人群,或者被用于恶意目的,那这种发展就是不可持续的。厂商得真正把伦理和社会责任刻在骨子里,而不是只做表面文章。
- 数据安全和隐私保护?这是生死线!:数据是AI的命根子,也是用户的命根子。数据安全出了问题,隐私被泄露了,用户凭什么相信你?厂商必须在数据管理和安全技术上持续投入,把用户的信任看得比什么都重。不然,早晚要玩完!
总而言之,AI大模型这股浪潮,是挡不住了。但作为网络安全从业者,我们不能光看热闹,更要看门道,时刻保持警惕,为这头狂奔的“巨兽”套上安全的缰绳。不然,等它失控了,再想补救,可就晚了!
*************************************2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享***************************************
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享*************************************


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









