







 本文介绍了如何使用Python爬虫获取并下载某网站上的视频。首先明确了需求,然后通过开发者工具分析视频播放地址,并在源代码中找到解码后的URL。接着详细阐述了实现步骤,包括发送请求、解析数据、获取视频内容和保存到本地。最后,提供了部分代码示例,帮助读者理解并实践爬虫下载视频的过程。
本文介绍了如何使用Python爬虫获取并下载某网站上的视频。首先明确了需求,然后通过开发者工具分析视频播放地址,并在源代码中找到解码后的URL。接着详细阐述了实现步骤,包括发送请求、解析数据、获取视频内容和保存到本地。最后,提供了部分代码示例,帮助读者理解并实践爬虫下载视频的过程。
首先给大家看一下,小姐姐们!
提提神!

有没有心动的感觉!
爱了~爱了
我们今晚就搞定她
首先需要安装一下,我们这次需要的环境
- selenium
- requests
- re
直接在cmd里输入:pip install +模块名 就可以安装好了
实在你不会安装可以私信我,有教程
接着看我们本次的爬取思路
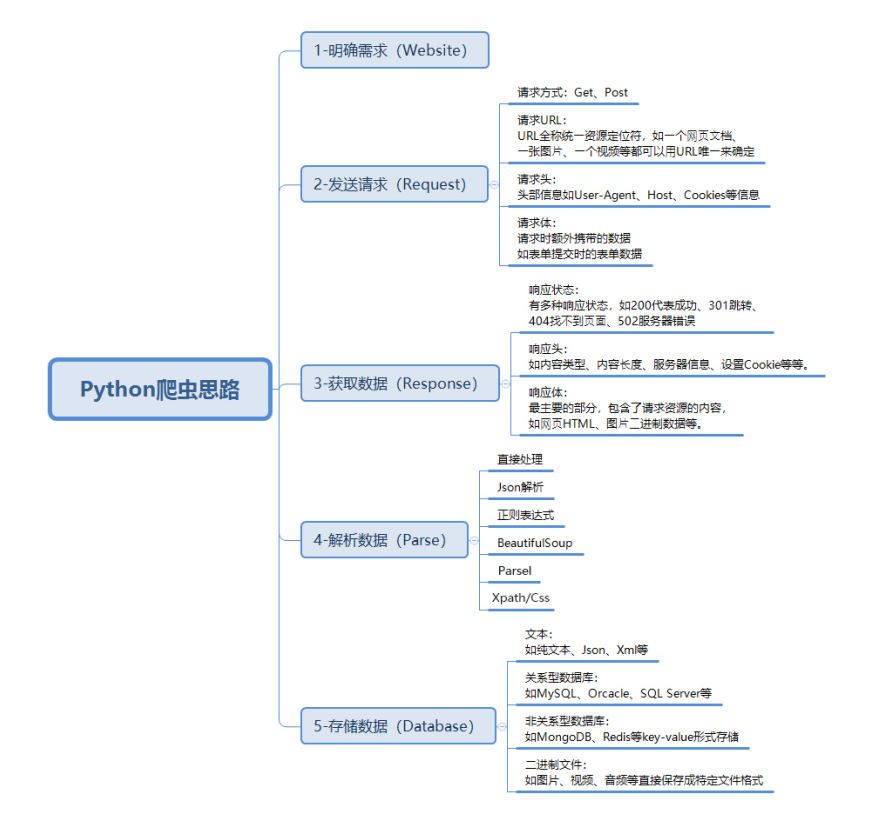
有需要这张图也可以私信我
Python爬虫思路都是通用的, 无论是爬取任何网站数据内容, 都是可以按照这个流程上面实行的
好,接下来咱们正式开始
一. 先明确需求
获取某网站上我女神的视频合集
通过开发者工具进行抓包分析, 分析某网站数据的来源
二.开发者工具的使用
打开我们的开发者工具(f12)
通过元素(Element)面板,我们能查看到想抓取页面渲染内容所在的标签、使用什么 CSS 属性(例
如:class=“middle”)等内容。例如我想要抓取我某乎主页中的动态标题,在网页页面所在处上右击鼠
标,选择“检查”,可进入 Chrome 开发者工具的元素面板。
网络(Network)面板记录页面上每个网络操作的相关信息,包括详细的耗时数据、HTTP 请求与响应
标头和 Cookie,等等。这就是我们通常说的抓包。
三.数据来源分析过程 :
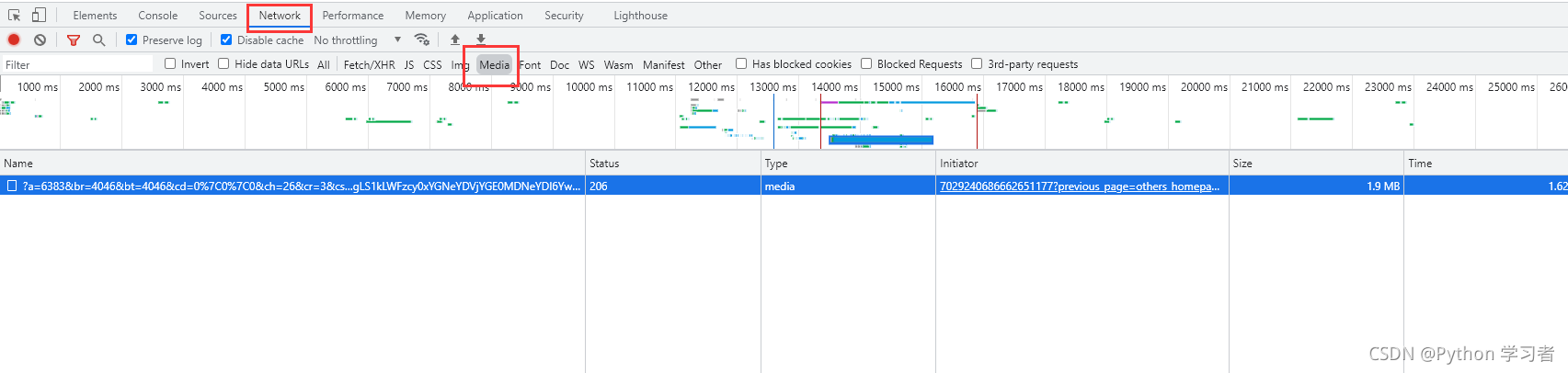
Media:媒体文件音频和视频数据
对于这个网站,想要找到他的视频播放地址,可以直接选择media可以看到视频播放地址.可以复制这个url在浏览器窗口打开.

https://v26-web.dou***vod.com/c2aeeb5733e4b7ee35d350b0300debc1/618e7abf/video/tos/cn/tos-cn-ve-15-alinc2/745f44b0459d44da83e43631d89dbdd2/?a=6383&br=4046&bt=4046&cd=0%7C0%7C0&ch=26&cr=3&cs=0&cv=1&dr=0&ds=3&er=&ft=VgcwUVIIL7ThWH0XrgAGZ&l=021636723874075fdbddc0200fff0030a921a640000003425f23d&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=M251d2g6Zm9nOTMzNGkzM0ApOGg3NGU8Nzs3NzM3Nzw0Nmc1X2NtcjRfczNgLS1kLWFzcy0xYGNeYDVjYGE0MDNeYDI6Yw%3D%3D&vl=&vr=
当你知道视频播放地址的了,接下来就是要分析,这个视频的URL地址可以哪个地址获取,可以分析url中的一段参数
M251d2g6Zm9nOTMzNGkzM0ApOGg3NGU8Nzs3NzM3Nzw0Nmc1X2NtcjRfczNgLS1kLWFzcy0xYGNeYDVjYGE0MDNeYDI6Yw
在开发者工具里面进行搜索
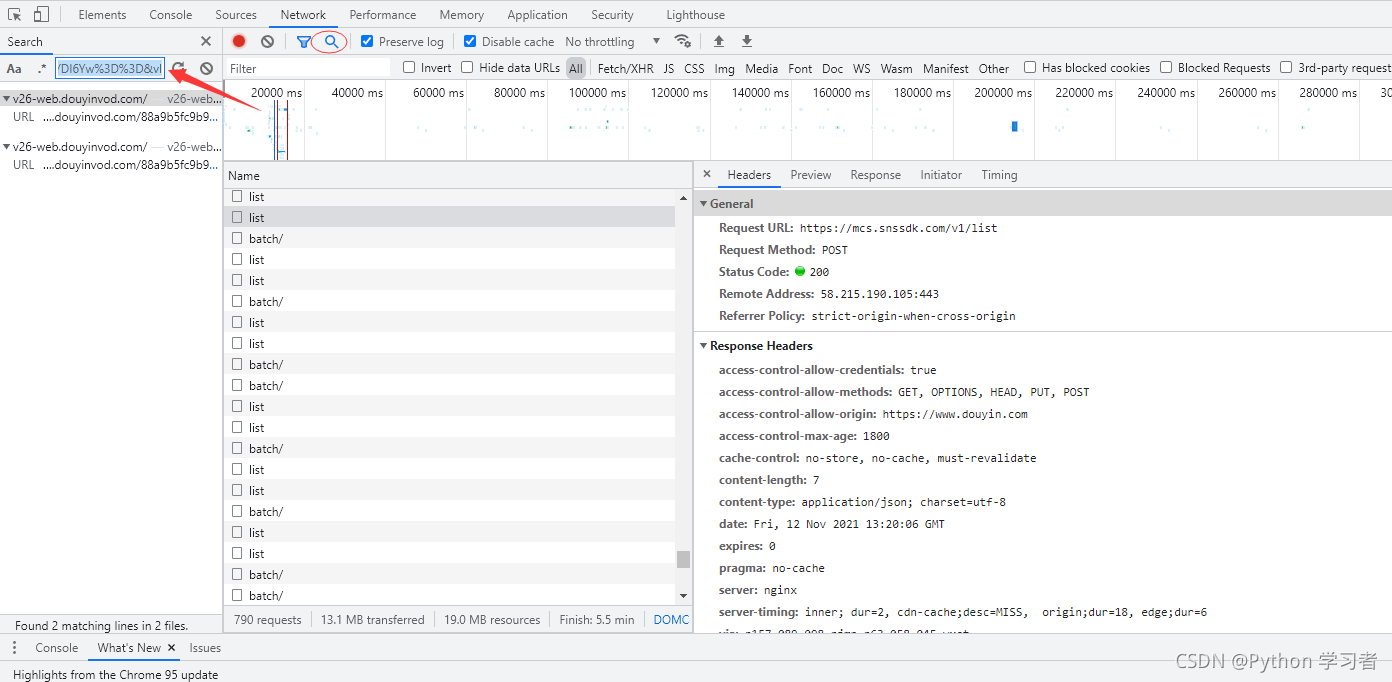
从搜索返回的内容可以知道, 我们想要的视频url地址在网页源代码里面是可以找到的.
这样的格式是通过编码之后的样子, 所以想要得到完整的url地址的话, 是需要进行解码的.
四.实现步骤
1.发送请求,对于视频详情页url地址发送请求
2.获取数据,获取服务器返回的response.text响应体文本数据
3.解析数据,使用正则表达式提取视频url地址以及视频标题
4.发送请求,对于视频播放地址发送请求
5.获取数据,获取二进制数据内容response.content
6.保存数据,保存视频内容到本地
五.代码实现
url='https://www.dou***.com/video/6881953434883329293'
headers={
'cookie':'cookies',
#'referer':'https://www.***yin.com/video/6899024915689704712',
'User-Agent':'Mozilla/5.0(WindowsNT10.0;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/81.0.4044.138Safari/537.36'
}
response=requests.get(url=href,headers=headers)
html_data=re.findall('src(.*?)vr%3D%2',response.text)[1]
video_url=requests.utils.unquote(html_data).replace('":"','https:')
title=re.findall('<titledata-react-helmet="true">(.*?)</title>',
response.text)[0]
video_content=requests.get(url=video_url).content
new_title=change_title(title)
withopen('video\\'+new_title+'.mp4',mode='wb')asf:
f.write(video_content)
print(title,'下载完成')
#有需要源码可以私信我
学会了吗,赶紧去下载你的女神吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









