









前言
本文我们介绍另一种实现方式:利用 Ollama+RagFlow 来实现,其中 Ollama 中使用的模型仍然是Qwen2
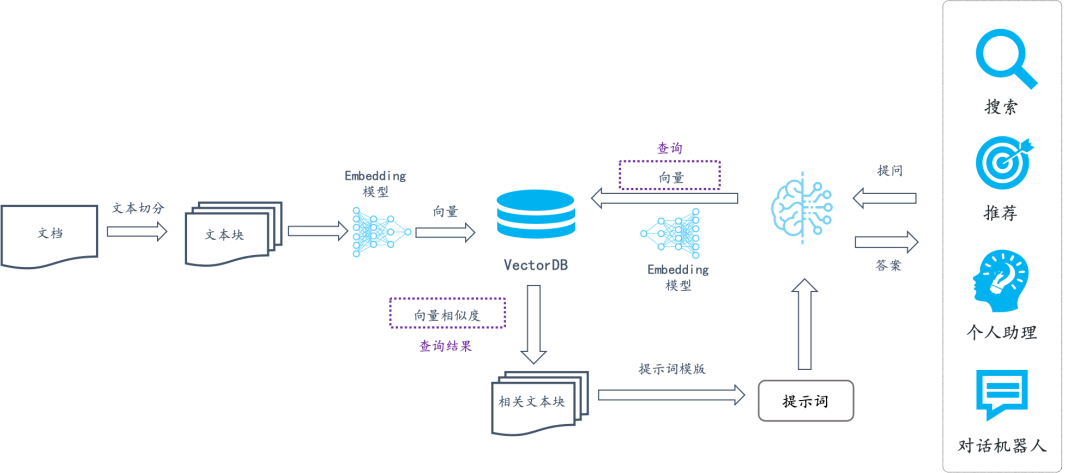
我们再来回顾一下 RAG 常见的应用架构
RagFlow的安装和部署
前置条件
-
CPU >= 4 核
-
RAM >= 16 GB
-
Disk >= 50 GB
-
Docker >= 24.0.0 & Docker Compose >= v2.26.1
安装
克隆仓库
$ git clone https://github.com/infiniflow/ragflow.git
进入 docker 文件夹,利用提前编译好的 Docker 镜像启动服务器:
$ cd ragflow/docker $ chmod +x ./entrypoint.sh $ docker compose -f docker-compose-CN.yml up -d
这一步注意docker 下载的镜像比较大,要留有足够的存储空间,我这边观察下载了约 10 个 G 左右。
服务器启动成功后再次确认服务器状态:
$ docker logs -f ragflow-server
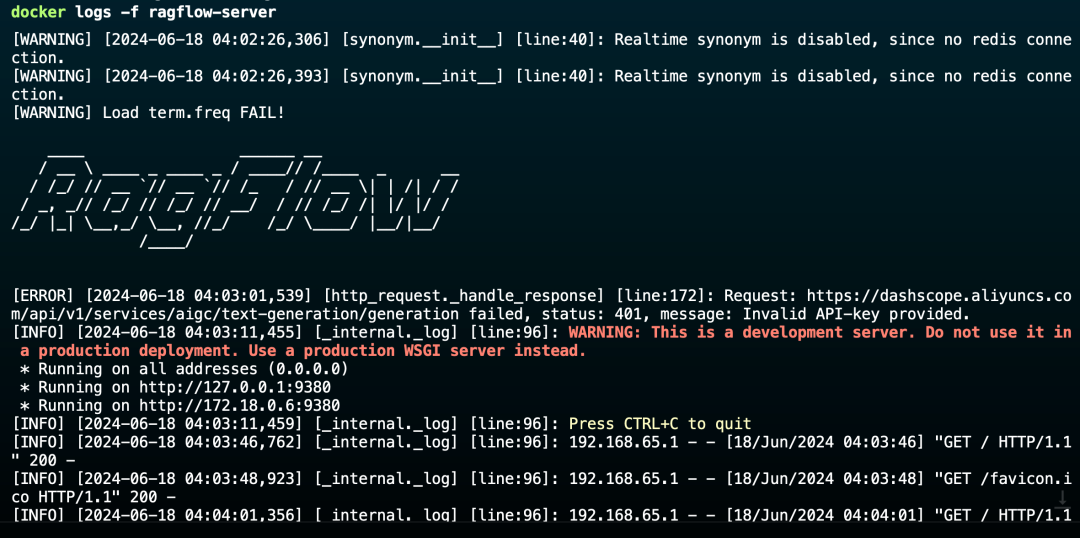
这里注意,安装完成后并不是要进入 下面两个地址
-
http://127.0.0.1:9380
-
http://172.18.0.6:9380
而是要进入:http://localhost:80 先注册账号,是下面这个页面
注册登录
在上图的界面中注册,然后登录就来到下面这个页面了
配置 Ollama 连接大模型
如下图我们先配置模型,点击右上角头像,再点击模型提供商
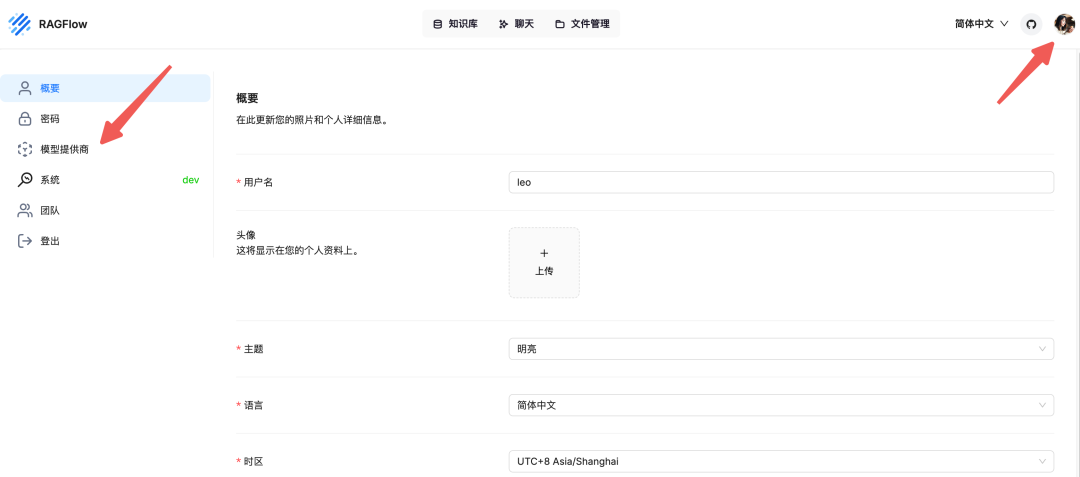
这里我是想连接我本地已经安装部署好的 Ollama ,通过 Ollama 我安装了 Qwen2 大模型,具体的安装步骤在之前的那篇文章里,有需要的可以移步到那里看。
打开Ollama 后, 我是通过服务器模式启动的大模型
ollama serve
当然你也可以选择其他平台和其他模型,需要提供 API key,API key 的获取就去你所选模型的网站,现在有很多模型的 API 是有免费额度的。
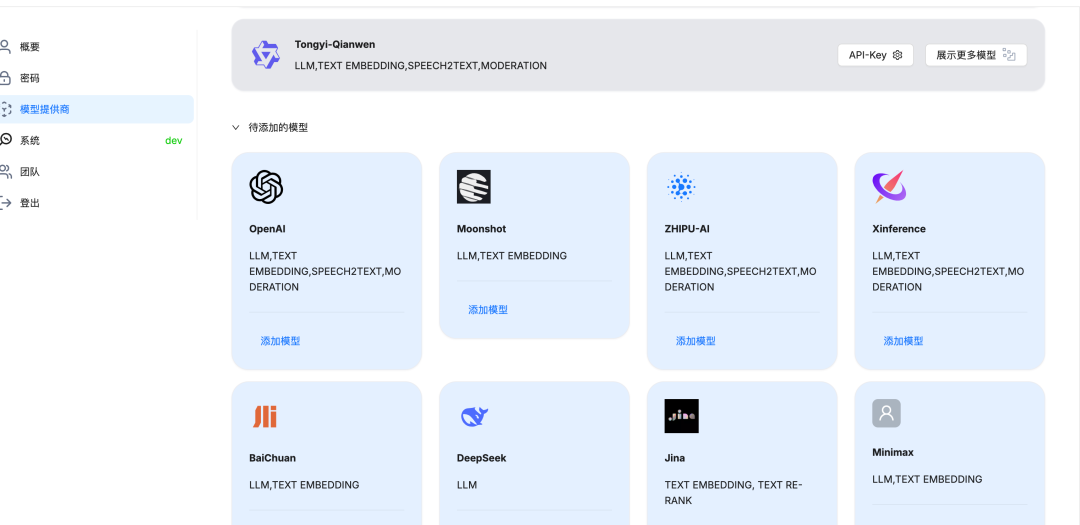
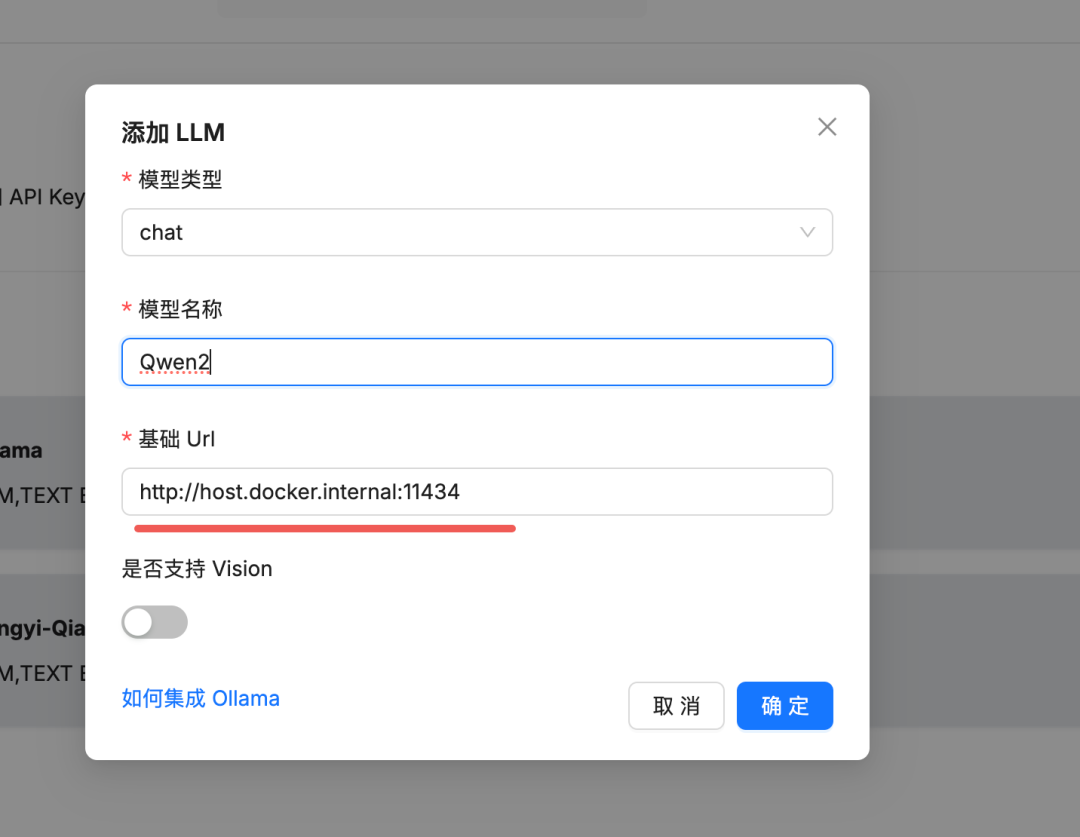
接着我们在 RagFlow 中配置模型,注意由于 RagFlow 我是在 docker 中安装的,所以请求本地部署的 Ollama 地址要用 :http://host.docker.internal:11434
创建知识库
接下来我们就可以创建知识库了
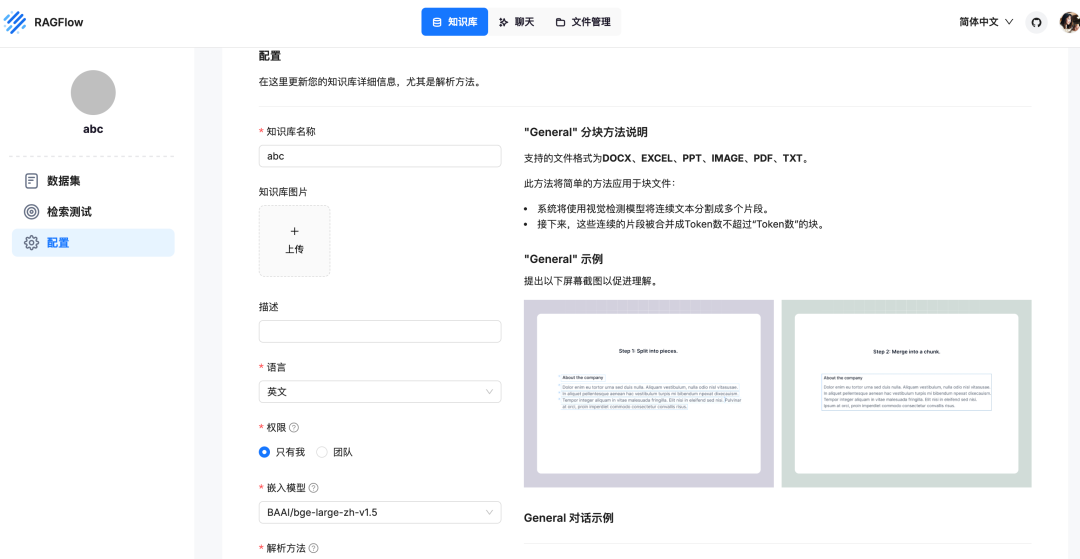
注意这里的文件类型没有 markdown,但我实测 markdown 是可以的。其他的选项,根据你的情况自行设置就好,很简单。
接下来就是上传你的文件了,也比较简单,但我发现上传后文件处理的比较慢,应该是我电脑配置的原因
文件上传并处理完成后,可以通过检索测试看一下文件有没有被正确检索。
至此,如果你上传完成全部的文件,知识库就算创建完毕了。
聊天
接着就到了展示成果的时候了,我们可以根据自己的知识库与模型进行自然语言交互了。
首先注意,在聊天配置中要把 token 设置的大一些,不然回复的内容会很少!我这里把它拉到最大值了。
展示一下成果:
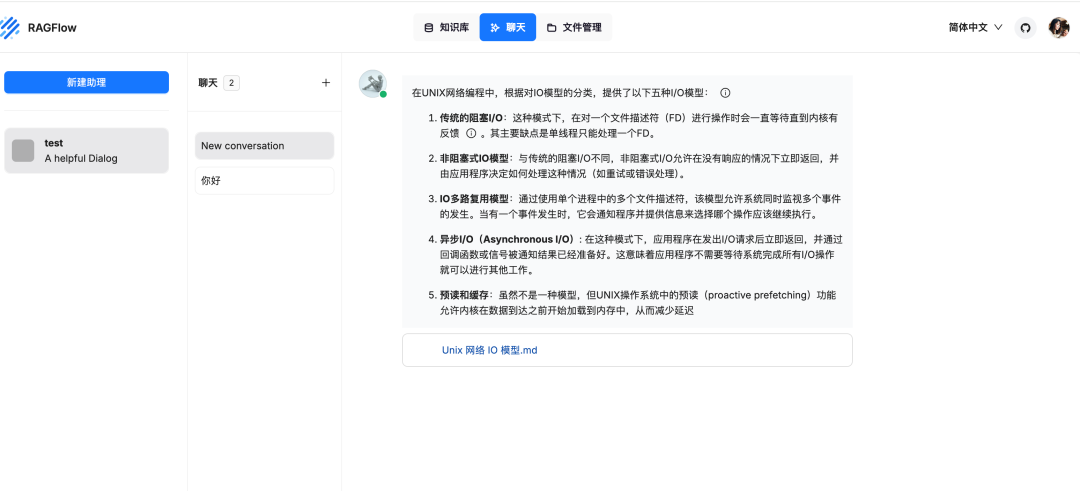
我觉得还算满意。但是由于我笔记本配置一般,也没有显卡支持,所以跑的很慢,真的很慢。但如果部署在有 GPU 的服务器上,企业私有化部署供内部使用,应该会比较快的。

思考
我这里的例子是用个人笔记本电脑上的资料做的个人知识库,对于文档的提问,无论是围绕着摘要总结来做,还是围绕着全文检索,答案看起来还行,也基本能用。但是这是面向个人的或者说面向 C 端 ,如果面向 B 端面向企业单靠向量检索就力不从心了,一来无法对精确信息召回,二来无法与企业内部信息系统集成(大量结构化数据)。所以必须在检索阶段引入多路召回和重排序,保证数据查询的准确度。
企业内部的数据包含各种格式,更复杂的还包含各类图表等,如果在没有理解这些语义的基础之上直接提供 RAG 方案,例如简单的根据文字空白就来切分段落,就会导致语义丢失从而让最终查询的结果也是混乱不堪。
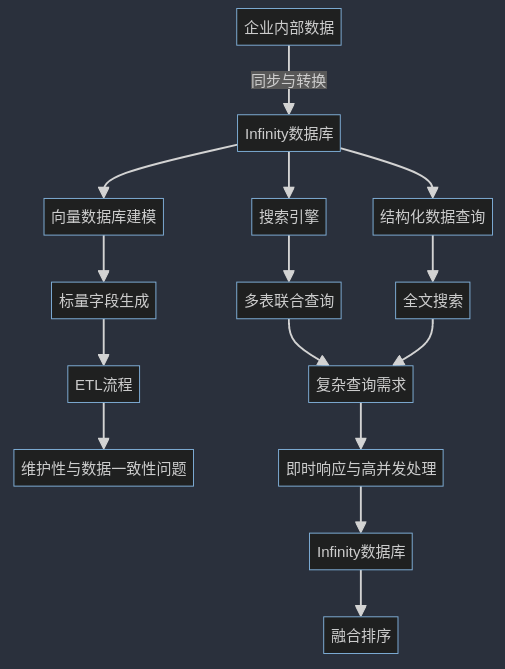
如果解决这个问题呢,除了之前说的多路召回(多跳)和重排序这种方案,目前业界还有其他思路,比如 infiniFlow提出的 Infinity AI原生数据库(https://github.com/infiniflow/infinity)
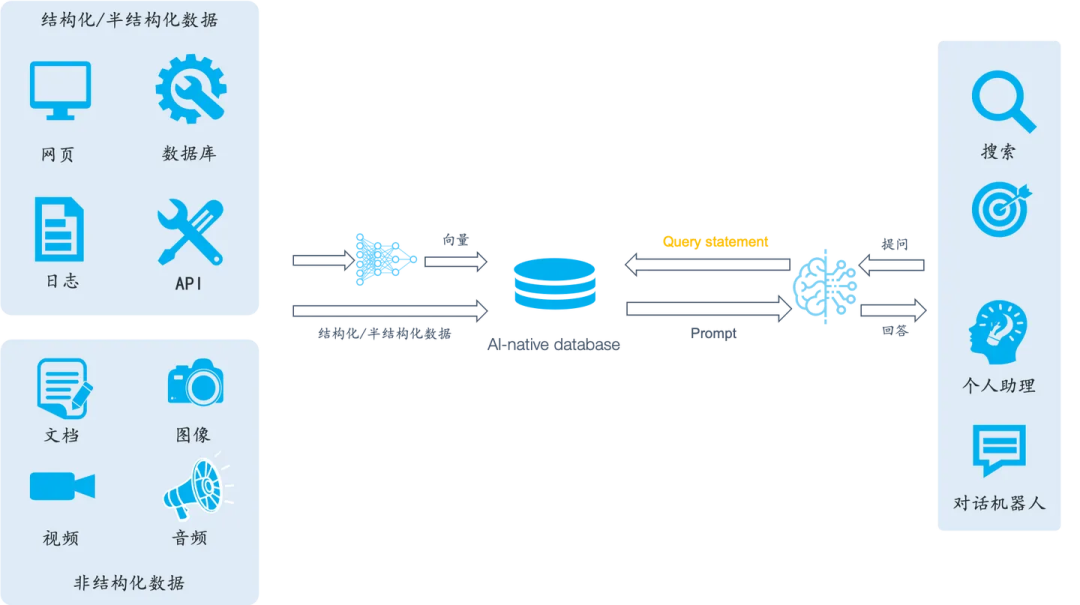
从上图可以看到,AI原生数据库 不仅涵盖非结构化的内容如文档和图片,也包括结构化的信息系统。对这些信息进行有效整合,并在此基础上实现多路召回机制和最终的融合排序解决方案。
此外,很多AI 产品的上下文现在是越来越长,可能有人会说现在上下文都这么长了,还用得着 RAG 吗?我认为,RAG在知识库问答场景依然是非常必要的。LLM 的长上下文能力,对于 RAG 来说应该是很大的促进。用 OpenAI 联创 Andrej Karpathy 的一张图做个类比,他把 LLM 比喻为一台计算机的 CPU, 把上下文类比为计算机的内存,那么以向量为代表的数据库,就可以看作是这台计算机的硬盘
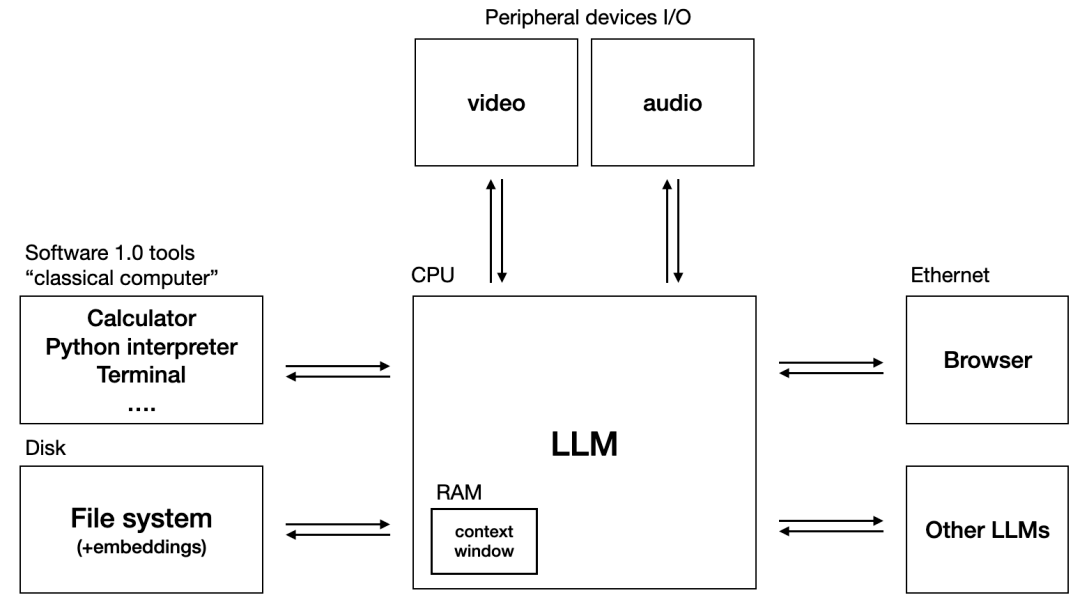
显然你不可能买一台只有内存的电脑。内存可以很大,但也意味着很贵,并且短时间内替代不了硬盘的作用。
最后是准确性问题,关于这个问题一般有两个方向的解决思路,一种是从 RAG 下手,比如做 Embedding 模型的微调。一种是从 LLM 下手,做 LLM 微调。虽然两种我都没真正做过,但从研读的资料上得知RAG系统在实时性和成本方面相较于LLM微调具有优势,因此更受青睐。这点跟我的直觉一致。
参考
-
https://github.com/infiniflow/ragflow/blob/main/README_zh.md
-
https://infiniflow.org/blog/database-for-rag
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









