







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
人脸识别技术作为计算机视觉领域的重要分支,在现代社会中扮演着越来越重要的角色。它广泛应用于安全监控、身份验证、人脸检索等领域。为了提高人脸识别的准确率和效率,本项目采用PCA(主成分分析)+SVM(支持向量机)+KFold方法,通过Python编程语言实现了一个高效、准确的人脸识别系统。
二、技术原理
PCA(主成分分析):PCA是一种常用的数据降维方法。在人脸识别中,由于人脸图像的像素点数量庞大,导致特征变量很多。通过PCA方法,可以将高维的人脸图像数据投影到低维空间,提取出最具代表性的特征,减少计算复杂度,提高识别效率。
SVM(支持向量机):SVM是一种强大的分类算法,它通过将样本数据投影到高维度的特征空间中,并找到最好的超平面,从而实现分类。在人脸识别中,SVM算法可以判别某一张图片是否属于某个人,具有较高的准确率和泛化能力。
KFold方法:KFold是一种常用的交叉验证方法。它将数据集分成K份,每次取其中K-1份作为训练集,剩余的一份作为测试集。通过多次迭代,可以充分利用数据集进行模型训练和评估,提高模型的稳定性和可靠性。
三、项目实现流程
数据收集与预处理:收集大量的人脸图像数据,并进行必要的预处理,如灰度化、归一化等。通过预处理,可以提高数据的质量和一致性,有利于后续的特征提取和模型训练。
特征提取:使用PCA方法对预处理后的人脸图像进行特征提取。通过PCA降维,得到每个人脸的低维特征向量。
数据集拆分:将提取的特征向量数据集按照KFold方法进行拆分,得到多个训练集和测试集。
模型训练:在每个训练集上,使用SVM算法训练人脸识别模型。通过调整SVM的参数和训练策略,优化模型的性能。
模型评估与优化:在每个测试集上,对训练好的模型进行评估,计算准确率、精确率、召回率等指标。根据评估结果,对模型进行优化和调整,提高模型的泛化能力和鲁棒性。
系统测试与部署:使用完整的测试集对系统进行全面测试,验证系统的性能和稳定性。测试通过后,将系统部署到实际应用场景中,进行人脸识别任务。
四、项目优势
高效性:通过PCA降维和SVM分类算法的结合,提高了人脸识别的速度和准确率。
准确性:采用KFold交叉验证方法,充分利用数据集进行模型训练和评估,提高了模型的稳定性和可靠性。
可扩展性:系统具有良好的可扩展性,可以方便地添加新的功能和优化现有算法。
实际应用价值:该系统可应用于安全监控、身份验证、人脸检索等领域,具有广泛的应用前景和重要的实用价值。
二、功能
基于Python PCA+SVM+KFold方法人脸识别
三、系统

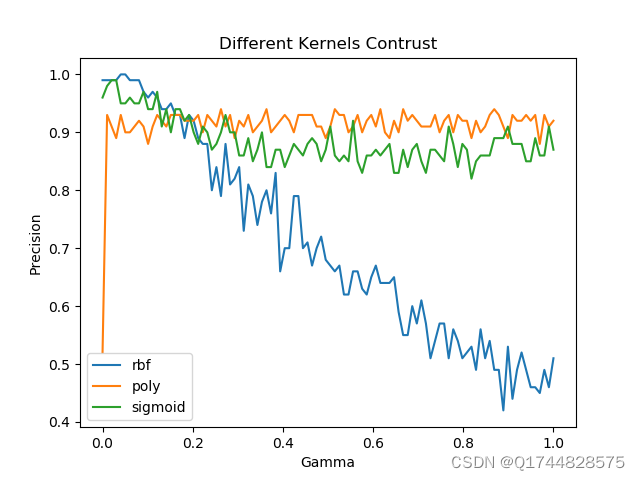
四. 总结
本项目基于Python PCA+SVM+KFold方法实现了一个高效、准确的人脸识别系统。通过PCA降维和SVM分类算法的结合,提高了人脸识别的速度和准确率。同时,采用KFold交叉验证方法,提高了模型的稳定性和可靠性。该系统具有良好的可扩展性和实际应用价值,为相关领域的研究和应用提供了有力支持。















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









