






爬虫基础
目录
1.urllib 是 Python 中的一个库,它提供了许多用于处理网络请求(如打开和读取URLs)的类和函数。
大家好,如果你是爬虫的初学者那么以下很适合你去看一看(爬虫别乱爬,不然很刑)
事先声明代码基于python
导入库都会吧?就用import狠狠导入
然后呢?爬虫需要很多第三方库去辅助,我们先介绍一个
1.urllib 是 Python 中的一个库,它提供了许多用于处理网络请求(如打开和读取URLs)的类和函数。
# urllib
from urllib.request import urlopen
url = 'http://www.baidu.com/'
resp = urlopen(url) # 发送请求,并将结果返回给resp
print(resp.read().decode())
分析一下上面的代码
当你使用
urlopen函数发送请求到'http://www.baidu.com/'这个URL,并将返回的响应对象resp的内容读取并解码后,通常你会得到HTML代码,这是百度网站的首页源代码。
具体来说,
print(resp.read().decode())这行代码会输出百度首页的HTML内容。这个HTML内容包含了定义网页结构和样式的各种标签(如<html>,<head>,<body>,<div>,<a>,<img>等),以及可能包含在页面中的JavaScript代码和CSS样式。
由于HTML内容可能非常长且复杂,直接打印到控制台可能不太方便阅读。通常,开发者会使用浏览器开发者工具(如Chrome的DevTools)来查看和分析网页的HTML结构,或者使用专门的库(如BeautifulSoup)来解析HTML内容并提取所需的信息。
另外,需要注意的是,由于网络请求可能会受到各种因素的影响(如网络延迟、服务器响应速度等),所以发送请求并获取响应可能需要一些时间。在编写代码时,你可能需要考虑添加适当的超时设置或错误处理机制来确保程序的稳定性和健壮性。
好了,现在这就是你的第一个爬虫代码,是不是枯燥又无味呢?
接下来我给你加一点调料,请吃
# urllib
from urllib.request import urlopen
url = 'http://www.baidu.com/'
resp = urlopen(url) # 发送请求,并将结果返回给resp
print(resp.read()) # 读取数据
print(resp.getcode()) # 为了判断是否要处理请求的结果
print(resp.geturl()) # 为了记录访问记录,避免2次访问,导致出现重复数据
print(resp.info()) # 响应头的信息,取到里面有用的数据
注释已经把调料都介绍完了,大家就在编译器上凑合着敲一敲吧,多敲才能理解这些代码有多枯燥,加油噢!
2.常见到的方法(request的)
- requset.urlopen(url,data,timeout)第一个参数ur即为URL,第二个参数data是访问URL时要传送的教据,第三个timeout是设置超时时间。第二三个参数是可以不传送的,data默认为空None,timeout戳认为 socket._GLOBAL DEFAULT_TIMEOUT第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
- response.read() read()方法就是读取文件里的全部内容,返回bytes类型
- response.getcode() 返回 HTTP的响应码,成功返回200,4服务器页面出错,5服务器问题
- response.geturl() 返回实际数据的实际URL,防止重定向问题
- response.info() 返回服务器响应的HTTP报头
3.Request对象
from urllib.request import urlopen
from urllib.request import Request
from random import choice
# url = 'http://www.baidu.com/'
url = 'http://httpbin.org/get'
user_agent_list=[
'ua1','ua2','ua3'
]
headers = {
'User-Agent':choice(user_agent_list)
}
req = Request(url,headers=headers)
resp = urlopen(req)
# print(resp.getcode())
print(resp.read().decode())request对象,因为构建请求的时候需要加入好多内容,通过构建一个request,服务器响应请求得到应答,显得逻辑清晰
headers写就是得伪装一下,正常情况下,浏览器会忍你一两次的浏览,但是你爬的多了,就把你禁止了。
headers里面的user-agent如何找呢?
1.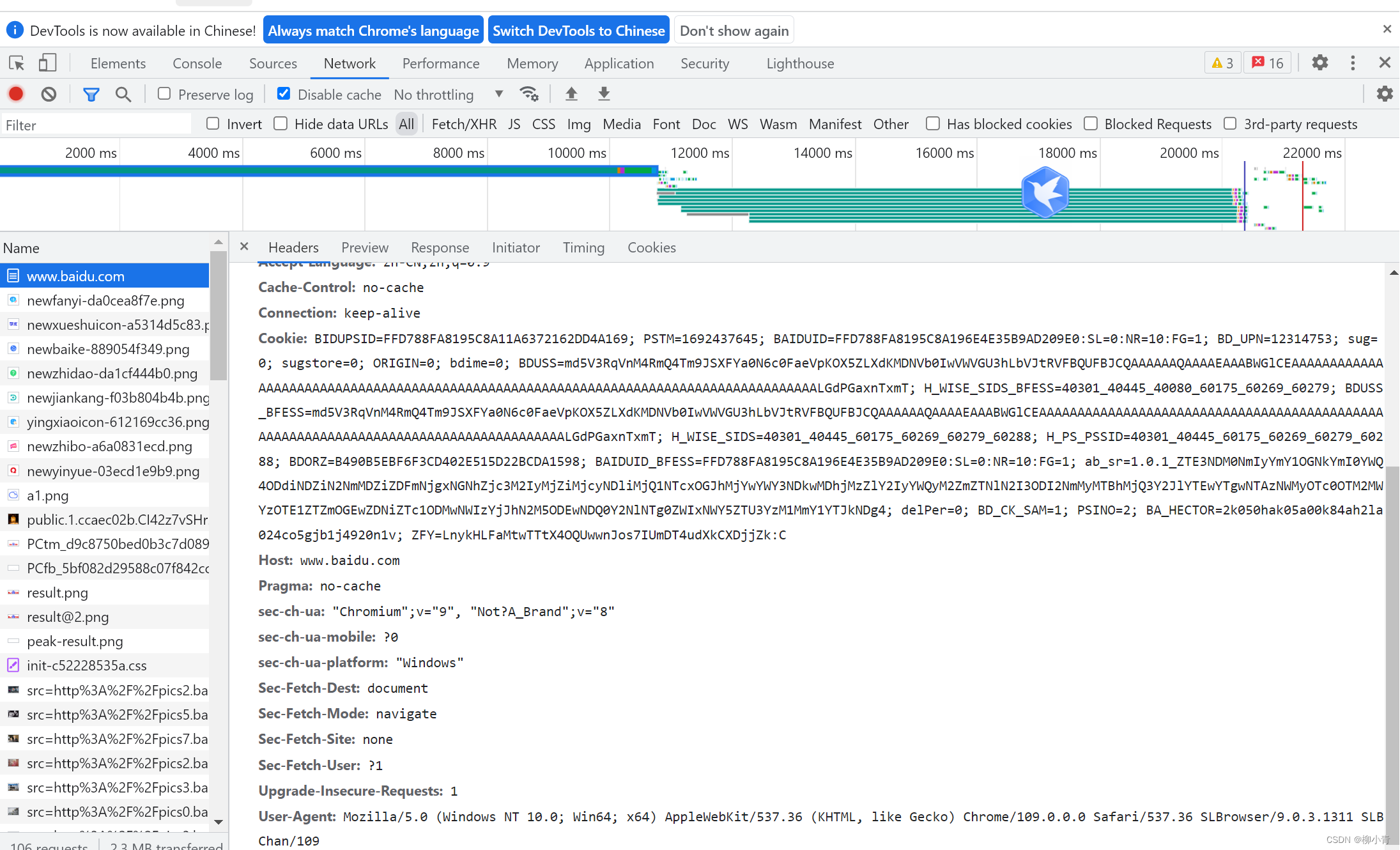
2.直接在网上搜users-agent大全
user_agent_list=[
'ua1','ua2','ua3'
]这样代码是为了随机访问,更好伪装
好了好了,大家好好学,我也会从大家的学习发言中有新的体会,我们下一篇见!















 2459
2459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









