






很奇妙,我不知道这一篇标题该叫啥,这标题也不知对不对,不过不能添加标签,顾及别人也看不到,自己能看懂,无所谓了;那我就说说遇到了什么问题,然后怎么解决的吧
当牵扯到随机的时候,为了验证精度啊之类的,常常需要做很多次,然后求平均啥的,很简单,会点鼠标的都能做,但是当文件上百的时候,就有点难度了。
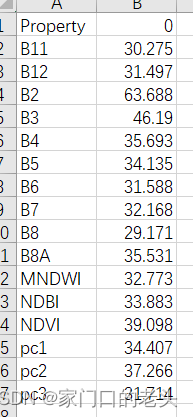
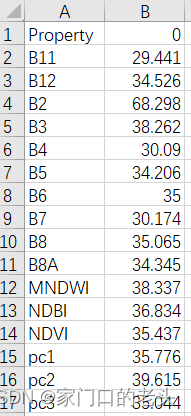
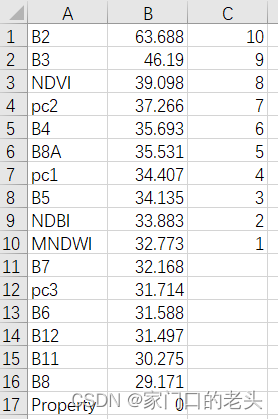
我的每个文件大概长这样,我需要做的呢,对B排序,按排序结果赋权值,按A属性对所有文件的权值结果求和、求平均之类的,
手操并不难,也就是把两个文件里面的B11对应的C加一下……B12对应的C加一下……
但我有几百个这样的文件,我可能需要一个不辞辛苦的会计,pandas帮我解决了问题
原文件1 原文件2 手动排序赋权值
然后加合,我懒,所以这里没有加和结果图
我的代码长这样:
import os
import pandas as pd
#创建全局可操作变量
df = pd.DataFrame(data=None,columns=['Property','0','score'])
#于是我们有了一个只有表头的可操作CSV,接下来把需要操作的文件读进来
allfiles = os.listdir('C:\\Users\\mrlon\\Desktop\\paixu')#获取每个文件名
print(allfiles)
#然后就是循环操作的事儿了
for eachfile in allfiles:#对每个文件
inpath = 'C:\\Users\\mrlon\\Desktop\\paixu'+'\\'+eachfile#输入路径
df1 = pd.read_csv(inpath,usecols=[0,1])#打开文件,我后面还有其他玩意儿,只读前两列
#skipnrows(跳过某些行)和nrows(读取某些行)可以控制行
df1 = df1.sort_values(by='0',ascending=False)#按‘0’那一列的值,降序排列
df1 = df1.iloc[:10]#保留前10行,从结果来看,iloc这个函数默认不算表头
df1['score']=[10,9,8,7,6,5,4,3,2,1]#添加我的权值
frames=[df,df1]#合并,相同的表头,只保留数据
df=pd.concat(frames)#覆写,把我得到的结果放在全局变量里面
del df1#删除,不加也行,反正下一个循环df1会被覆盖
#最后就是分组求和的事情了,按Property分组,对‘0’,‘score’求和
df = df.groupby('Property',sort=False,as_index=False)\
.agg(Property=('Property','first'),Value=('0', 'sum'),score=('score','sum'))
#'\'一行太长,不好看,'\'用来换行,drop_duplicates()删除重复项,groupby分组,agg融合
#agg的参数很,很……很随意吧……这里相当于定义了三个新列覆写了原数据,
#Property=('Property','first'),等号左侧是新列名,右侧第一个是运算列,第二个是运算形式
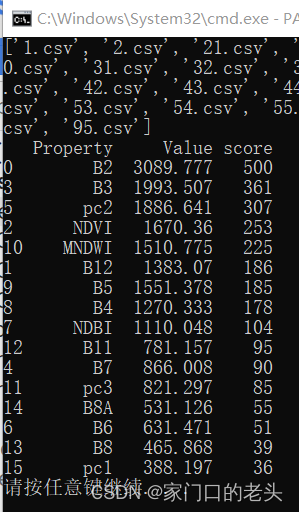
df = df.sort_values(by='score',ascending=False)#降序排列一下
print(df)#输出,是的,我不需要保存我的输出结果长这样,当然,这里数据不全:
这是对我帮助比较大的文章















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









