







啊哈!算法-第1章-一大波数正在靠近——排序
第1节 最快最简单的排序——桶排序
在我们生活的这个世界中到处都是被排序过的东东。站队的时候会按照身高排序,考试的名次需要按照分数排序,网上购物的时候会按照价格排序,电子邮箱中的邮件按照时间排序……总之很多东东都需要排序,可以说排序是无处不在。现在我们举个具体的例子来介绍一下排序算法。
首先出场的是我们的主人公小哼,上面这个可爱的娃就是啦。期末考试完了老师要将同学们的分数按照从高到低排序。小哼的班上只有 5 个同学,这 5 个同学分别考了 5 分、3 分、5 分、2 分和 8 分,哎考得真是惨不忍睹(满分是 10 分)。接下来将分数进行从大到小排序,排序后是 8 5 5 3 2。你有没有什么好方法编写一段程序,让计算机随机读入 5 个数然后将这5 个数从大到小输出?
首先我们需要申请一个大小为 11 的数组 int a[11]。OK,现在你已经有了 11 个变量,编号从 a[0]~a[10]。刚开始的时候,我们将 a[0]~a[10]都初始化为 0,表示这些分数还都没有人得过。例如 a[0]等于 0 就表示目前还没有人得过 0 分,同理 a[1]等于 0 就表示目前还没有人得过 1 分……a[10]等于 0 就表示目前还没有人得过 10 分。
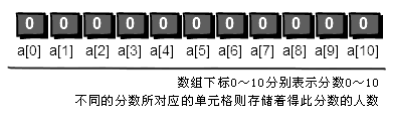
下面开始处理每一个人的分数,第一个人的分数是 5 分,我们就将相对应的 a[5]的值在原来的基础增加 1,即将 a[5]的值从 0 改为 1,表示 5 分出现过了一次。

第二个人的分数是 3 分,我们就把相对应的 a[3]的值在原来的基础上增加 1,即将 a[3]的值从 0 改为 1,表示 3 分出现过了一次。

注意啦!第三个人的分数也是 5 分,所以 a[5]的值需要在此基础上再增加 1,即将 a[5]的值从 1 改为 2,表示 5 分出现过了两次。

按照刚才的方法处理第四个和第五个人的分数。最终结果就是下面这个图啦。

你发现没有,a[0]~a[10]中的数值其实就是 0 分到 10 分每个分数出现的次数。接下来,我们只需要将出现过的分数打印出来就可以了,出现几次就打印几次,具体如下。
a[0]为 0,表示“0”没有出现过,不打印。
a[1]为 0,表示“1”没有出现过,不打印。
a[2]为 1,表示“2”出现过 1 次,打印 2。
a[3]为 1,表示“3”出现过 1 次,打印 3。
a[4]为 0,表示“4”没有出现过,不打印。
a[5]为 2,表示“5”出现过 2 次,打印 5 5。
a[6]为 0,表示“6”没有出现过,不打印。
a[7]为 0,表示“7”没有出现过,不打印。
a[8]为 1,表示“8”出现过 1 次,打印 8。
a[9]为 0,表示“9”没有出现过,不打印。
a[10]为 0,表示“10”没有出现过,不打印。
最终屏幕输出“2 3 5 5 8”,完整的代码如下。
n = int(input("请输入分数的数量:"))
list_tong = [0 for i in range(11)]
score = list(map(int, input("请输入分数:").split())) # 存分数的列表
for i in range(len(score)): # 将数据出现的次数存储到桶中
list_tong[score[i]] += 1
for i in range(len(list_tong)): # 循环遍历桶中存放到数据
for j in range(list_tong[i]): # 根据桶中存放到数据循环打印
print(i, end=" ")
仔细观察的同学会发现,刚才实现的是从小到大排序。但是我们要求是从大到小排序,这该怎么办呢?
n = int(input("请输入分数的数量:"))
list_tong = [0 for i in range(11)]
score = list(map(int, input("请输入分数:").split())) # 存分数的列表
for i in range(len(score)): # 将数据出现的次数存储到桶中
list_tong[score[i]] += 1
for i in range(-1, -12, -1): # i为列表的逆序位置
for j in range(list_tong[i]): # 根据桶中存放到数据循环打印
print(len(list_tong)+i, end=" ") # 正序i-逆序i = 列表长度
这种排序方法我们暂且叫它“桶排序”。因为其实真正的桶排序要比这个复杂一些,以后再详细讨论,目前此算法已经能够满足我们的需求了。
这个算法就好比有 11 个桶,编号从 0~10。每出现一个数,就在对应编号的桶中放一个小旗子,最后只要数数每个桶中有几个小旗子就 OK 了。例如 2 号桶中有 1 个小旗子,表示2 出现了一次;3 号桶中有 1 个小旗子,表示 3 出现了一次;5 号桶中有 2 个小旗子,表示 5出现了两次;8 号桶中有 1 个小旗子,表示 8 出现了一次。

现在你可以尝试一下输入 n 个 0-1000 之间的整数,将它们从大到小排序。提醒一下,如果需要对数据范围在 0~1000 之间的整数进行排序,我们需要 1001 个桶,来表示 0-1000之间每一个数出现的次数,这一点一定要注意。代码实现如下。
n = int(input("请输入分数的数量:"))
list_tong = [0 for i in range(1001)]
score = list(map(int, input("请输入分数:").split())) # 存分数的列表
for i in range(len(score)): # 将数据出现的次数存储到桶中
list_tong[score[i]] += 1
for i in range(-1, -1002, -1): # i为列表的逆序位置
for j in range(list_tong[i]): # 根据桶中存放到数据循环打印
print(len(list_tong)+i, end=" ") # 正序i-逆序i = 列表长度
可以输入以下数据进行验证。
10
8 100 50 22 15 6 1 1000 999 0
运行结果是:
1000 999 100 50 22 15 8 6 1 0
最后来说下时间复杂度的问题。代码中第 2 行的循环一共循环了 m 次(m 为桶的个数),第 4 行的代码循环了 n 次(n 为待排序数的个数),第 6行和第 7行一共循环了 m+n 次。所以整个排序算法一共执行了 m+n+m+n 次。我们用大写字母 O 来表示时间复杂度,因此该算法的时间复杂度是 O(m+n+m+n)即 O(2*(m+n))。我们在说时间复杂度的时候可以忽略较小的常数,最终桶排序的时间复杂度为 O(m+n)。还有一点,在表示时间复杂度的时候,n 和 m通常用大写字母即 O(M+N)。
这是一个非常快的排序算法。桶排序从 1956 年就开始被使用,该算法的基本思想是由E.J.Issac 和 R.C.Singleton 提出来的。之前我说过,其实这并不是真正的桶排序算法,真正的桶排序算法要比这个更加复杂。但是考虑到此处是算法讲解的第一篇,我想还是越简单易懂越好,真正的桶排序留在以后再聊吧。需要说明一点的是:我们目前学习的简化版桶排序算法,其本质上还不能算是一个真正意义上的排序算法。为什么呢?例如遇到下面这个例子就没辙了。
现在分别有 5 个人的名字和分数:huhu 5 分、haha 3 分、xixi 5 分、hengheng 2 分和 gaoshou 8 分。请按照分数从高到低,输出他们的名字。即应该输出 gaoshou、huhu、xixi、haha、hengheng。发现问题了没有?如果使用我们刚才简化版的桶排序算法仅仅是把分数进行了排序。最终输出的也仅仅是分数,但没有对人本身进行排序。也就是说,我们现在并不知道排序后的分数原本对应着哪一个人!这该怎么办呢??不要着急,请看下节——冒泡排序。
第2节 邻居好说话——冒泡排序
简化版的桶排序不仅仅有上一节所遗留的问题,更要命的是:它非常浪费空间!例如需要排序数的范围是 0~2100000000 之间,那你则需要申请 2100000001 个变量,也就是说要写成 int a[2100000001]。因为我们需要用 2100000001 个“桶”来存储 0~2100000000 之间每一个数出现的次数。即便只给你 5 个数进行排序(例如这 5 个数是 1、1912345678、2100000000、18000000 和 912345678),你也仍然需要 2100000001 个“桶”,这真是太浪费空间了!还有,如果现在需要排序的不再是整数而是一些小数,比如将 5.56789、2.12、1.1、3.123、4.1234这五个数进行从小到大排序又该怎么办呢?现在我们来学习另一种新的排序算法:冒泡排序。它可以很好地解决这两个问题。
冒泡排序的基本思想是:每次比较两个相邻的元素,如果它们的顺序错误就把它们交换过来。
例如我们需要将 12 35 99 18 76 这 5 个数进行从大到小的排序。既然是从大到小排序,也就是说越小的越靠后,你是不是觉得我在说废话,但是这句话很关键(∩_∩)。
首先比较第 1 位和第 2 位的大小,现在第 1 位是 12,第 2 位是 35。发现 12 比 35 要小,因为我们希望越小越靠后嘛,因此需要交换这两个数的位置。交换之后这 5 个数的顺序是35 12 99 18 76。
按照刚才的方法,继续比较第 2 位和第 3 位的大小,第 2 位是 12,第 3 位是 99。12 比 99 要小,因此需要交换这两个数的位置。交换之后这 5 个数的顺序是 35 99 12 18 76。
根据刚才的规则,继续比较第 3 位和第 4 位的大小,如果第 3 位比第 4 位小,则交换位置。交换之后这 5 个数的顺序是 35 99 18 12 76。
最后,比较第 4 位和第 5 位。4 次比较之后 5 个数的顺序是 35 99 18 76 12。
经过 4 次比较后我们发现最小的一个数已经就位(已经在最后一位,请注意 12 这个数的移动过程),是不是很神奇。
每次都是比较相邻的两个数,如果后面的数比前面的数大,则交换这两个数的位置。一直比较下去直到最后两个数比较完毕后,最小的数就在最后一个了。就如同是一个气泡,一步一步往后“翻滚”,直到最后一位。所以这个排序的方法有一个很好听的名字"冒泡排序"

说到这里其实我们的排序只将 5 个数中最小的一个归位了。每将一个数归位我们将其称为“一趟”。下面我们将继续重复刚才的过程,将剩下的 4 个数一一归位。
好,现在开始“第二趟”,目标是将第 2 小的数归位。首先还是先比较第 1 位和第 2 位,如果第 1 位比第 2 位小,则交换位置。交换之后这 5 个数的顺序是 99 35 18 76 12。接下来你应该都会了,依次比较第 2 位和第 3 位,第 3 位和第 4 位。注意此时已经不需要再比较第 4位和第 5 位。因为在第一趟结束后已经可以确定第 5 位上放的是最小的了。第二趟结束之后这 5 个数的顺序是 99 35 76 18 12。
“第三趟”也是一样的。第三趟之后这 5 个数的顺序是 99 76 35 18 12。
现在到了最后一趟“第四趟”。有的同学又要问了,这不是已经排好了吗?还要继续?当然,这里纯属巧合,你若用别的数试一试可能就不是了。
“冒泡排序”的原理是:每一趟只能确定将一个数归位。即第一趟只能确定将末位上的数(即第 5 位)归位,第二趟只能将倒数第 2 位上的数(即第 4 位)归位,第三趟只能将倒数第 3 位上的数(即第 3 位)归位,而现在前面还有两个位置上的数没有归位,因此我们仍然需要进行“第四趟”。
“第四趟”只需要比较第 1 位和第 2 位的大小。因为后面三个位置上的数归位了,现在第 1 位是 99,第 2 位是 76,无需交换。这 5 个数的顺序不变仍然是 99 76 35 18 12。到此排序完美结束了,5 个数已经有 4 个数归位,那最后一个数也只能放在第 1 位了。
最后我们总结一下:如果有 n 个数进行排序,只需将 n1 个数归位,也就是说要进行n-1 趟操作。而“每一趟”都需要从第 1 位开始进行相邻两个数的比较,将较小的一个数放在后面,比较完毕后向后挪一位继续比较下面两个相邻数的大小,重复此步骤,直到最后一个尚未归位的数,已经归位的数则无需再进行比较(已经归位的数你还比较个啥,浪费表情)。
n = int(input("请输入数字的数量:"))
score = list(map(int, input("请分别输入数字:").split()))
if n == len(score):
for i in range(len(score)-1): # n个数排序,只需要进行n-1趟
for j in range(n-1-i): # 从第一位开始,每位需要进行n-i-1次
if score[j] < score[j+1]: # 比较大小并进行交换
score[j], score[j+1] = score[j+1], score[j]
for i in score:
print(i, end=" ")
可以输入以下数据进行验证。
10
8 100 50 22 15 6 1 1000 999 0
运行结果是:
0 1 6 8 15 22 50 100 999 1000
将上面代码稍加修改,就可以解决第 1 节遗留的问题,如下。
class Student:
def __init__(self, name, score):
self.name = name
self.score = score
n = int(input("请输入总人数:"))
duixiang = []
for i in range(n):
name, score = input("请输入学生姓名和分数:").split()
score = float(score)
duixiang.append(Student(name, score))
duixiang.sort(key=lambda x: x.score, reverse=True)
for i in duixiang:
print(i.name)
可以输入以下数据进行验证。
5
huhu 5
haha 3
xixi 5
hengheng 2
gaoshou 8
运行结果是:
gaoshou
huhu
xixi
haha
hengheng
冒泡排序的核心部分是双重嵌套循环。不难看出冒泡排序的时间复杂度是 O(N 2)。这是一个非常高的时间复杂度。
第3节 最常用的排序——快速排序
上一节的冒泡排序可以说是我们学习的第一个真正的排序算法,并且解决了桶排序浪费空间的问题,但在算法的执行效率上却牺牲了很多,它的时间复杂度达到了 O(N2)。假如我们的计算机每秒钟可以运行 10 亿次,那么对 1 亿个数进行排序,桶排序只需要 0.1 秒,而冒泡排序则需要 1 千万秒,达到 115 天之久,是不是很吓人?那有没有既不浪费空间又可以快一点的排序算法呢?那就是“快速排序”啦!光听这个名字是不是就觉得很高端呢?
假设我们现在对“6 1 2 7 9 3 4 5 10 8”这 10 个数进行排序。首先在这个序列中随便找一个数作为基准数(不要被这个名词吓到了,这就是一个用来参照的数,待会儿你就知道它用来做啥了)。为了方便,就让第一个数 6 作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在 6 的右边,比基准数小的数放在 6 的左边,类似下面这种排列。
3 1 2 5 4 6 9 7 10 8
方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于 6 的数,再从左往右找一个大于 6 的数,然后交换它们。这里可以用两个变量 i 和 j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵 i”和
“哨兵 j”。刚开始的时候让哨兵 i 指向序列的最左边(即 i=1),指向数字 6。让哨兵 j 指向序列的最右边(即 j=10),指向数字 8。

首先哨兵 j 开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵 j 先出动,这一点非常重要(请自己想一想为什么)。哨兵 j 一步一步地向左挪动,直到找到一个小于 6 的数停下来。接下来哨兵 i 再一步一步向右挪动,直到找到一个大于 6的数停下来。最后哨兵 j 停在了数字 5 面前,哨兵 i 停在了数字 7 面前。


现在交换哨兵 i 和哨兵 j 所指向的元素的值。交换之后的序列如下。
6 1 2 5 9 3 4 7 10 8
到此,第一次交换结束。接下来哨兵 j 继续向左挪动(再次友情提醒,每次必须是哨兵j 先出发)。他发现了 4(比基准数 6 要小,满足要求)之后停了下来。哨兵 i 也继续向右挪动,他发现了 9(比基准数 6 要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下。
6 1 2 5 4 3 9 7 10 8

第二次交换结束,“探测”继续。哨兵 j 继续向左挪动,他发现了 3(比基准数 6 要小,满足要求)之后又停了下来。哨兵 i 继续向右移动,糟啦!此时哨兵 i 和哨兵 j 相遇了,哨兵 i 和哨兵 j 都走到 3 面前。说明此时“探测”结束。我们将基准数 6 和 3 进行交换。交换之后的序列如下。
3 1 2 5 4 6 9 7 10 8

到此第一轮“探测”真正结束。此时以基准数 6 为分界点,6 左边的数都小于等于 6,6右边的数都大于等于 6。
现在基准数 6 已经归位,它正好处在序列的第 6 位。此时我们已经将原来的序列,以 6 为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列,因为 6 左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理 6 左边和右边的序列即可。
def QuickSort(nums, left, right):
if left < right:
mid = nums[left]
i = left
j = right
while i != j:
while j > i and nums[j] >= mid:
j -= 1
while i < j and nums[i] <= mid:
i += 1
nums[i], nums[j] = nums[j], nums[i]
nums[j], nums[left] = nums[left], nums[j]
QuickSort(nums, left, i-1)
QuickSort(nums, i+1, right)
import random
data = [random.randint(-100, 100) for _ in range(10)] # 此处可以自己尝试用一组固定的数据来进行测试
QuickSort(data, 0, len(data)-1)
print(data)
第4节 小哼买书
现在来看一个具体的例子“小哼买书”(根据全国青少年信息学奥林匹克联赛 NOIP2006 普及组第一题改编),来实践一下本章所学的三种排序算法。

小哼的学校要建立一个图书角,老师派小哼去找一些同学做调查,看看同学们都喜欢读哪些书。小哼让每个同学写出一个自己最想读的书的 ISBN 号(你知道吗?每本书都有唯一的 ISBN 号,不信的话你去找本书翻到背面看看)。当然有一些好书会有很多同学都喜欢,这样就会收集到很多重复的 ISBN 号。小哼需要去掉其中重复的 ISBN 号,即每个 ISBN 号只保留一个,也就说同样的书只买一本(学校真是够抠门的)。然后再把这些 ISBN 号从小到大排序,小哼将按照排序好的 ISBN 号去书店买书。请你协助小哼完成“去重”与“排序”的工作。
输入有 2 行,第 1 行为一个正整数,表示有 n 个同学参与调查(n≤100)。第 2 行有 n个用空格隔开的正整数,为每本图书的 ISBN 号(假设图书的 ISBN 号在 1~1000 之间)。
输出也是 2 行,第 1 行为一个正整数 k,表示需要买多少本书。第 2 行为 k 个用空格隔开的正整数,为从小到大已排好序的需要购买的图书的 ISBN 号。
例如输入:
10
20 40 32 67 40 20 89 300 400 15
则输出:
8
15 20 32 40 67 89 300 400
解决这个问题的方法大致有两种。第一种方法:先将这 n 个图书的 ISBN 号去重,再进行从小到大排序并输出;第二种方法:先从小到大排序,输出的时候再去重。这两种方法都可以。
n = int(input("请输入参与调查的人数:"))
list_chu = list(map(int, input("请输入图书的ISBN号").split()))
list_tong = [0 for i in range(1, 1001)]
if n == len(list_chu):
for j in list_chu:
list_tong[j+1] += 1
for k in range(len(list_tong)):
if list_tong[k] != 0:
print(k-1, end=" ")
这种方法的时间复杂度就是桶排序的时间复杂度,为 O(N+M)。
第二种方法我们需要先排序再去重。排序我们可以用冒泡排序或者快速排序。
# 冒泡排序
n = int(input("请输入参与调查的人数:"))
list_chu = list(map(int, input("请输入图书的ISBN号").split()))
for i in range(n-1):
for j in range(n-1-i):
if list_chu[j] > list_chu[j+1]:
list_chu[j], list_chu[j+1] = list_chu[j+1], list_chu[j]
for k in range(len(list_chu)):
if list_chu[k] != list_chu[k-1]:
print(list_chu[k], end=" ")
这种方法的时间复杂度由两部分组成,一部分是冒泡排序的时间复杂度,是O (N2),另一部分是读入和输出,都是 O(N),因此整个算法的时间复杂度是 O(2N+N2)。相对于 N2来说,2N 可以忽略(我们通常忽略低阶),最终该方法的时间复杂度是 O(N2)。
# 快速排序
def QuickSort(nums, left, right):
if left < right:
mid = nums[left]
i = left
j = right
while i != j:
while j > i and nums[j] >= mid:
j -= 1
while i < j and nums[i] <= mid:
i += 1
nums[i], nums[j] = nums[j], nums[i]
nums[j], nums[left] = nums[left], nums[j]
QuickSort(nums, left, i-1)
QuickSort(nums, i+1, right)
n = int(input("请输入参与调查的人数:"))
list_chu = list(map(int, input("请输入图书的ISBN号").split()))
QuickSort(list_chu, 0, len(list_chu)-1)
for k in range(len(list_chu)):
if list_chu[k] != list_chu[k-1]:
print(list_chu[k], end=" ")
我们来回顾一下本章三种排序算法的时间复杂度。桶排序是最快的,它的时间复杂度是O(N+M);冒泡排序是 O(N2);快速排序是 O(NlogN)。
# 最后附上不想学算法的我的代码:
n = int(input("请输入参与调查的人数:"))
list_chu = list(map(int, input("请输入图书的ISBN号").split()))
list_chu.sort()
for k in range(len(list_chu)):
if list_chu[k] != list_chu[k-1]:
print(list_chu[k], end=" ")

















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











