




 本文介绍如何使用Python进行文本分析,包括词汇频率统计、n-gram模型构建及马尔科夫链生成。同时探讨了自然语言处理工具包(NLTK)的应用,并通过实例展示了如何提取文本特征。
本文介绍如何使用Python进行文本分析,包括词汇频率统计、n-gram模型构建及马尔科夫链生成。同时探讨了自然语言处理工具包(NLTK)的应用,并通过实例展示了如何提取文本特征。
8.1 概括数据
源自美国第九任总统威廉 ·亨利 ·哈里森的就职演说http://pythonscraping.com/files/inaugurationSpeech.txt
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
import operator
def cleanInput(input):
input = re.sub('\n+', " ", input) #把换行符替换成空格
input = re.sub('\[[0-9]*\]', "", input) #剔除[数字]
input = re.sub(' +', " ", input) #连续的多个空格替换成空格
input = bytes(input, 'UTF-8')
input = input.decode('ascii', 'ignore')
cleanInput = []
input = input.split(' ') # 分成单词序列,所有单词按照空格分开
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'): #删除单词a i
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input) # 分成单词序列,所有单词按照空格分开
output = {}
for i in range(len(input) - n + 1):
ngramTemp = " ".join(input[i:i+n])
if ngramTemp not in output:
output[ngramTemp] = 0
output[ngramTemp] += 1
return output
content = str(urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt").read(), 'utf-8')
ngrams = ngrams(content, 2)
sortedNGrams = sorted(ngrams.items(), key = operator.itemgetter(1), reverse=True)
print(sortedNGrams)def isCommon(ngram):
commonWords = ["the", "be", "and", "of", "a", "in", "to", "have", "it",
"i", "that", "for", "you", "he", "with", "on", "do", "say", "this",
"they", "is", "an", "at", "but", "we", "his", "from", "that", "not",
"by", "she", "or", "as", "what", "go", "their", "can", "who", "get",
"if", "would", "her", "all", "my", "make", "about", "know", "will",
"as", "up", "one", "time", "has", "been", "there", "year", "so",
"think", "when", "which", "them", "some", "me", "people", "take",
"out", "into", "just", "see", "him", "your", "come", "could", "now",
"than", "like", "other", "how", "then", "its", "our", "two", "more",
"these", "want", "way", "look", "first", "also", "new", "because",
"day", "more", "use", "no", "man", "find", "here", "thing", "give",
"many", "well"]
for word in ngram:
if word in commonWords:
return True;
return False8.2 马尔科夫模型
http://twitov.extrafuture.com/,还可以用它们为傻瓜测试系统生成看似真实的垃圾邮件
随机事件的特点是一个离散事件发生之后,另一个离散事件将在前一个事件的条件下以一定的概率发生
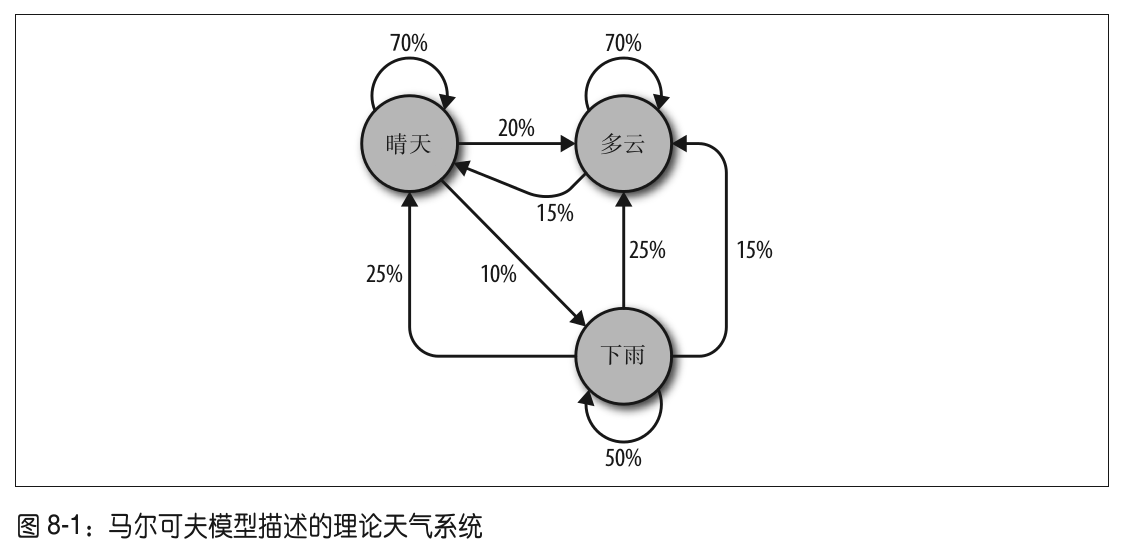
需要注意以下几点:
- 任何一个节点引出的所有可能的总和必须等于100%,。无论是多么复杂的系统,必然会在下一步发生若干事件中的一个事件。
- 虽然这个天气系统在任一时间都只有三种可能,但是你可以用这个模型生成一个天气状态的无限次转移列表。
- 只有当前节点的状态会影响后一天的状态。如果你在”晴天“节点上,即使前100天都是晴天或雨天都没关系,明天晴天的概率还是70%
- 有些节点可能比其他节点较难到达。这个现象的原因用数学来解释非常复杂,但是可以直观地看出,在这个系统中任意时间节点上,第二天是”雨天“的可能性(指向它的箭头概率之和小于”100%“)比”晴天“或”多云“要小很多。
事实上,Google的PageRank算法也是基于马尔科夫模型,把网站做为节点,入站/出站链接做为节点之间的连线。连接某个节点”可能性“表示一个网站的相对关注度。
例子:文本分析与写作:
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from random import randint
def wordListSum(wordList):
sum = 0
for word, value in wordList.items():
sum += value
return sum
def retrieveRandomWord(wordList):
randIndex = randint(1, wordListSum(wordList)) #随机选取:按照字典中单词频次的权重随机获取一个单词
for word, value in wordList.items():
randIndex -= value
if randIndex <= 0:
return word
def buildWordDict(text):
# 剔除换行符和引号
text = text.replace("\n", " ")
text = text.replace("\"", "")
# 保证每个标点符号都和前面的单词在一起
# 这样不会被剔除,保留在马尔科夫链中
punctuation = [',', '.', ';', ':']
for symbol in punctuation:
text = text.replace(symbol, " "+symbol+" ");
words = text.split(" ")
# 过滤空单词
words = [word for word in words if word != ""]
print(len(words))
# 建一个二维字典---字典里有字典 word_a -> word_b, word_a -> word_c, word_a -> word_d
# {word_a : {word_b : 2, word_c : 1, word_d : 1}, 表示word_a出现了四次,有2次后面跟word_b 即50%的概率...
wordDict = {}
for i in range(1, len(words)):
if words[i-1] not in wordDict:
# 为单词新建一个词典
wordDict[ words[i-1] ] = {}
if words[i] not in wordDict[words[i-1]]: # 后一个单词
wordDict[ words[i-1] ][ words[i] ] = 0
wordDict[ words[i-1] ][ words[i] ] = wordDict[ words[i-1] ][ words[i] ] + 1
return wordDict
text = str(urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt").read(), 'utf-8')
wordDict = buildWordDict(text)
print(len(wordDict))
# 生成链长为100的马尔科夫链
length = 100
chain = ""
currentWord = "I" # 以I为开始的句子
for i in range(0, length):
chain += currentWord + " "
currentWord = retrieveRandomWord(wordDict[currentWord]) #随机选取:按照字典中单词频次的权重随机获取一个单词
print(chain)维基百科六度分割:终结篇
在第3章,存储了维基词条链接在数据库里的爬虫。因为它体现了一种从一个页面指向另一个页面的链接路径选择问题,是一个有向图问题
用第5章里获得的链接数据表,实现一个完整的广度优先搜索算法:
# -*- coding: utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/var/run/mysqld/mysqld.sock', user='root', passwd='dong', db='mysql', charset='utf8')
cur = conn.cursor()
cur.execute("use wikipedia")
class SolutionFound(RuntimeError):
def __init__(self, message):
self.message = message
def getLinks(fromPageId):
cur.execute("select toPageId from links where fromPageId = %s", (fromPageId))
if cur.rowcount == 0:
return None
else:
return [x[0] for x in cur.fetchall()]
# 当前节点相连的page
def constructDict(currentPageId):
links = getLinks(currentPageId)
if links:
return dict(zip(links, [{}] * len(links)))
return {}
# 链接树要么为空,要么包含多个链接
def searchDepth(targetPageId, currentPageId, linkTree, depth):
if depth == 0:
# 停止递归,返回结果
return linkTree
if not linkTree:
linkTree = constructDict(currentPageId)
if not linkTree:
# 若此节点页面无链接,则跳过此节点
return {}
cur.execute("select url from pages where id = %s", (currentPageId))
if cur.rowcount == 0:
url = ()
else:
url = cur.fetchone()
if targetPageId in linkTree.keys():
print("target " + str(targetPageId) + " found!")
raise SolutionFound("page: " + str(currentPageId) + " : " + str(url))
for branchKey, branchValue in linkTree.items():
try:
# 递归建立链接树
linkTree[branchKey] = searchDepth(targetPageId, branchKey, branchValue, depth - 1)
except SolutionFound as e:
print(e.message)
raise SolutionFound("page: " + str(currentPageId) + " : " + str(url))
return linkTree
try:
searchDepth(1342, 1, {}, 4)
print("No solution found")
except SolutionFound as e:
print(e.message)8.3 自然语言工具包
讨论对文本中所有单词的统计分析。哪些单词使用得最频繁?哪些单词用得最少?一个单词后面跟着哪几个单词?这些单词是如何组合在一起的?我们应该做却没有做的事情,是理解每个单词的具体含义。
NLTK是用于识别和标记英语文本中各个词的词性。这个项目于2000年创建
用NLTK做统计分析一般是从Text对象开始的
# -*- coding: utf-8 -*-
from nltk import word_tokenize
from nltk import Text
tokens = word_tokenize("Here is some not very interesting text")
text = Text(tokens)from nltk import FreqDist
fdist = FreqDist(text)
print(fdist.most_common(10))# -*- coding: utf-8 -*-
from nltk.book import *
from nltk import FreqDist
fdist = FreqDist(text6)
print(fdist.most_common(10))
from nltk import bigrams
bigrams = bigrams(text6)
bigramsDist = FreqDist(bigrams)
print(bigramsDist[("Sir", "Robin")])
# 18
from nltk import ngrams
fourgrams = ngrams(text6, 4)
fourgramsDist = FreqDist(fourgrams)
print( fourgramsDist[("father", "smelt", "of", "elderberries")])
# 1区分同义词或语境,两个词互为同义词,同一词在不同的语境中可能会导致意思混乱
除了词性,还要区分词的用法

除了度量语言,NLTK还可以用它的超级大字典分析文本内容,帮助人们寻找单词的含义。

# -*- coding: utf-8 -*-
from nltk.book import *
from nltk import word_tokenize
text = word_tokenize("Strange women lying in ponds distributing swords is no basis for a system of government. Supreme executive power derives from a mandate from the masses, not from some farcical aquatic ceremony.")
from nltk import pos_tag
print(pos_tag(text))搜索名词Google
# -*- coding: utf-8 -*-
from nltk import word_tokenize, sent_tokenize, pos_tag
sentences = sent_tokenize("Google is one of the best companies in the world.I constantly google myself to see what I'm up to.")
nouns = ['NN', 'NNS', 'NNP', 'NNPS']
for sentence in sentences:
if "google" in sentence.lower():
taggedWords = pos_tag(word_tokenize(sentence))
for word in taggedWords:
if word[0].lower() == 'google' and word[1] in nouns:
print(sentence)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









