







目录
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
使用场景 : 排行榜
1. 编码
zset的编码有ziplist和skiplist两种。
底层分别使用ziplist(压缩链表)和skiplist(跳表)实现。
-
什么时候使用ziplist什么时候使用skiplist?
当zset满足以下两个条件的时候,使用ziplist:
- 保存的元素少于128个
- 保存的所有元素大小都小于64字节
不满足这两个条件则使用skiplist。
(注意:这两个数值是可以通过redis.conf的zset-max-ziplist-entries 和 zset-max-ziplist-value选项 进行修改。)
2. 实现
-
ziplist编码
关于什么是ziplist(压缩链表),可以参见这篇文章:Redis源码分析-压缩列表ziplist
ziplist 编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。

从小到大排列

ziplist结构
-
skiplist编码
skiplist 编码的有序集合对象使用 zet 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳表:
typedef struct zset{
//跳跃表
zskiplist *zsl;
//字典
dict *dice;
} zset;
字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。
说明:其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
zset的常用命令
zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
zrem(key, member) :删除名称为key的zset中的元素member
zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素
zcard(key):返回名称为key的zset的基数
zscore(key, element):返回名称为key的zset中元素element的score
zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素
zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
更多命令详细使用:https://www.cnblogs.com/yhq-qhh/p/9838368.html
skiplist介绍
跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。简单说来跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度。
先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
- 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程:
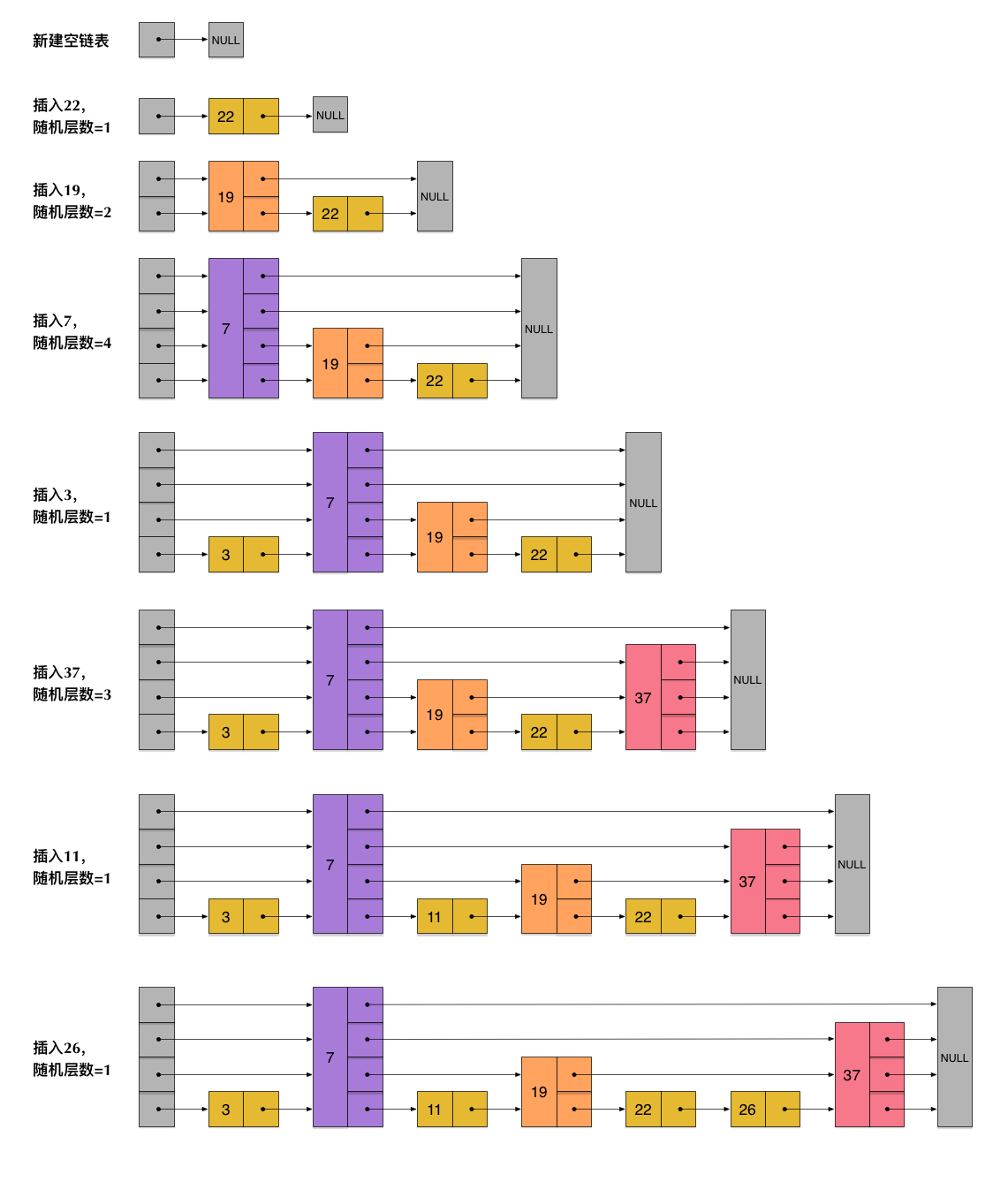
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
skiplist,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径:
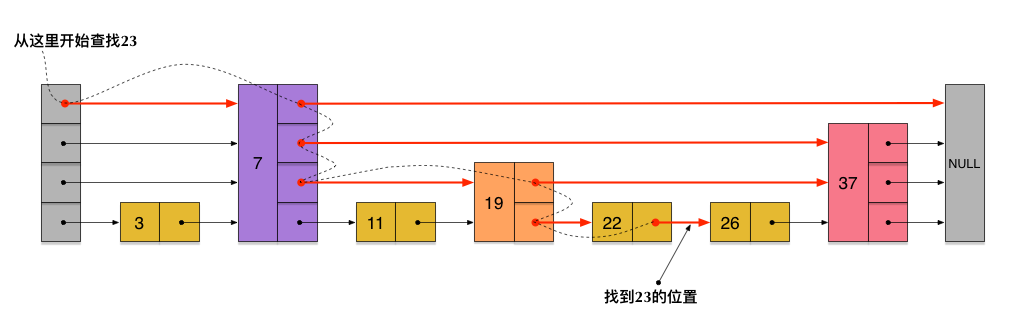
需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key(score)进行排序的,查找过程也是根据key在比较。
执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
- 首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
- 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
- 节点最大的层数不允许超过一个最大值,记为MaxLevel。
这个计算随机层数的伪码如下所示:
randomLevel()
level := 1
// random()返回一个[0...1)的随机数
while random() < p and level < MaxLevel do
level := level + 1
return levelrandomLevel()的伪码中包含两个参数,一个是p,一个是MaxLevel。在Redis的skiplist实现中,这两个参数的取值为:
p = 1/4
MaxLevel = 32skiplist与平衡树、哈希表的比较
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
- 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
Redis中的skiplist实现
skiplist的数据结构定义:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #define ZSKIPLIST_MAXLEVEL 32 #define ZSKIPLIST_P 0.25 typedef struct zskiplistNode { robj *obj; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned int span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist; |
简单分析一下几个查询命令:
- zrevrank由数据查询它对应的排名,这在前面介绍的skiplist中并不支持。
- zscore由数据查询它对应的分数,这也不是skiplist所支持的。
- zrevrange根据一个排名范围,查询排名在这个范围内的数据。这在前面介绍的skiplist中也不支持。
- zrevrangebyscore根据分数区间查询数据集合,是一个skiplist所支持的典型的范围查找(score相当于key,数据相当于value)。
实际上,Redis中sorted set的实现是这样的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
看一下sorted set与skiplist的关系,:
- zscore的查询,不是由skiplist来提供的,而是由那个dict来提供的。
- 为了支持排名(rank),Redis里对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后,也同时很容易获得排名。而且,根据排名的查找,时间复杂度也为O(log n)。
- zrevrange的查询,是根据排名查数据,由扩展后的skiplist来提供。
- zrevrank是先在dict中由数据查到分数,再拿分数到skiplist中去查找,查到后也同时获得了排名。
总结起来,Redis中的skiplist跟前面介绍的经典的skiplist相比,有如下不同:
- 分数(score)允许重复,即skiplist的key允许重复。这在最开始介绍的经典skiplist中是不允许的。
- 在比较时,不仅比较分数(相当于skiplist的key),还比较数据本身。在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
- 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在skiplist中可以很方便地计算出每个元素的排名(rank)。
Redis为什么用skiplist而不用平衡树?
-
内存效率:跳跃表相较于B+树在存储相同数量的元素时,通常需要更少的内存。这是因为跳跃表的节点层数是随机的,每个节点只需记录下一层节点的指针,而B+树的每个节点需要记录所有子节点的指针,这使得跳跃表在内存使用上更为高效。
-
实现简单性:跳跃表的实现和调试相对简单,没有B+树那样的平衡调整复杂度。在Redis这样追求高性能和易用性的系统中,简单的实现意味着更高的可维护性和更少的出错机会。
-
操作简便:跳跃表的基本操作如插入、删除只需修改相邻节点的指针,而B+树的插入和删除可能需要进行复杂的子树调整,影响性能。对于实时性要求高的Redis来说,这种简洁快速的操作方式更为合适。
-
链表特性:跳跃表以链表形式存储,便于进行范围查询操作(如
ZRANGE和ZREVRANGE),且其缓存局部性与平衡树相当,这对于连续数据访问模式是有利的。 -
适应性:Redis作为一个内存数据库,其操作不涉及磁盘I/O,因此不需要B+树为了优化磁盘访问而设计的特性,如高度平衡和顺序访问优化。
综上所述,Redis选择跳跃表作为Zset的实现,是因为它在内存使用、实现复杂度、操作效率以及适应内存数据库特性方面相比B+树有显著优势。















 8793
8793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









