







目录
1 软件环境和远程工具
(1)Centos7服务器一台。
(2)远程连接工具(推荐使用方式二)
使用远程工具进行centos连接,有两种方式:
方式一:给linux系统安装xdfp,使用windows远程连接工具进行连接。此种连接方式有桌面。
具体操作方式见:
方式二:使用mobaxterm远程工具进行连接。Mobaxterm工具无需安装,下载后打开运行即可使用。
优点是:对于无法安装桌面的linux系统,安装后可以上传文件。


2 环境安装
2.1安装包准备
一、将软件安装包上传至centos的 /root/opt/目录下;
注意:在linux系统中分清“/root/”目录和“/”目录
常用命令介绍:
默认登录后是在目录“/root”下;
cd : 切换至“/root”目录下;
cd / :切换至“/”目录下。
二、在目录 /opt/下新建文件夹用于存放解压后的压缩包:
1.#mkdir 文件夹名称:新建文件夹
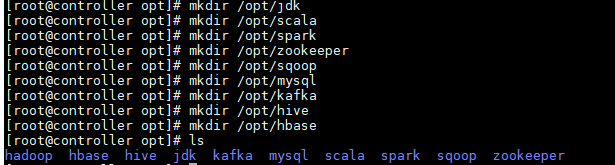
[root@controller opt]# mkdir /opt/jdk
[root@controller opt]# mkdir /opt/scala
[root@controller opt]# mkdir /opt/spark
[root@controller opt]# mkdir /opt/hadoop
[root@controller opt]# mkdir /opt/zookeeper
[root@controller opt]# mkdir /opt/sqoop
[root@controller opt]# mkdir /opt/mysql
[root@controller opt]# mkdir /opt/kafka
[root@controller opt]# mkdir /opt/hive
[root@controller opt]# mkdir /opt/hbase如下图所示:
2.切换至/root/opt/下:以下均为离线下载的安装包

(1)#tar zxvf *** :解压文件夹
[root@controller opt]# tar zxvf hadoop-2.8.0.tar.gz
[root@controller opt]# tar zxvf jdk-8u144-linux-x64.tar.gz
[root@controller opt]# tar zxvf hbase-1.2.6-bin.tar.gz
[root@controller opt]# tar zxvf scala-2.12.10.tgz
[root@controller opt]# tar zxvf spark-2.4.4-bin-hadoop2.7.tgz
[root@controller opt]# tar zxvf kafka_2.12-1.0.0.tgz
[root@controller opt]# tar zxvf mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz
[root@controller opt]# tar zxvf zookeeper-3.4.10.tar.gz
[root@controller opt]# tar zxvf apache-hive-2.1.1-bin.tar.gz蓝色均为解压后的文件夹:

(2)#mv 移动目标文件夹 /路径/重命名 :移动文件夹至指定目录下,并重新命名
[root@controller opt]# mv hadoop-2.8.0/ /opt/hadoop/hadoop2.8/
[root@controller opt]# mv jdk1.8.0_144/ /opt/jdk/jdk1.8
[root@controller opt]# mv apache-hive-2.1.1-bin/ /opt/hive/hive2.1
[root@controller opt]# mv hbase-1.2.6/ /opt/hbase/hbase1.2
[root@controller opt]# mv kafka_2.12-1.0.0/ /opt/kafka/kafka2.12
[root@controller opt]# mv mysql-5.7.24-linux-glibc2.12-x86_64/ /opt/mysql/mysql5.7
[root@controller opt]# mv scala-2.12.10/ /opt/scala/scala2.12
[root@controller opt]# mv spark-2.4.4-bin-hadoop2.7/ /opt/spark/spark2.4
[root@controller opt]# mv zookeeper-3.4.10/ /opt/zookeeper/zookeeper3.42.2配置环境变量
2.2.1环境变量文件(总配置)
编辑命令:#vim /etc/profile,输入以下内容:
#Java Config
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$java_home/lib/dt.jar:$:JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
#Scala Config
export SCALA_HOME=/opt/scala/scala2.12.10
export PATH=$SCALA_HOME/bin:$PATH:
#Spark Config
export SPARK_HOME=/opt/spark/spark2.4
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bn:$PATH
#Zookeeper Config
#export ZK_HOME=/home/slave/Desktop/file/zookeeper/zookeeper3.4
#Hbase Config
#export HBASE_HOME=/home/slave/Desktop/file/hbase/hbase1.2
#Hadoop Config
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
#Hive Config
#export HIVE_HOME=/home/slave/Desktop/file/hive/hive2.1
#export HIVE_CONF_DIR=${HIVE_HOME}/conf
#kafka config
#export KAFKA_HOME=/home/slave/Desktop/file/kafka/kafka1.0.0
#export
#PATH.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:$PATH以下均为各软件的分步配置:
2.2.2 Java安装
1.配置环境变量,编辑/etc/profile文件,使用命令:#vim /etc/profile
#Java Config
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$java_home/lib/dt.jar:$:JAVA_HOME/lib/tools.jar:$JRE_HOME/li2.使配置文件生效:#source /etc/profile
3.验证是否安装,查看java版本:#java -version

2.2.3 Scala安装
1.配置环境变量,编辑/etc/profile文件,使用命令:#vim /etc/profile
#Scala Config
export SCALA_HOME=/opt/scala/scala2.12.10
export PATH=$SCALA_HOME/bin:$PATH:配置文件生效:#source /etc/profile
3.验证是否安装,查看scala版本:#scala -version
![]()
2.2.4 hadoop安装
1.配置环境变量,编辑/etc/profile文件,使用命令:#vim /etc/profile:
#Hadoop Config
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
2.使配置文件生效:#source /etc/profile
3.切换至hadoop的安装目录下:cd /opt/hadoop/hadoop8/etc/hadoop。进行如下文件的配置。
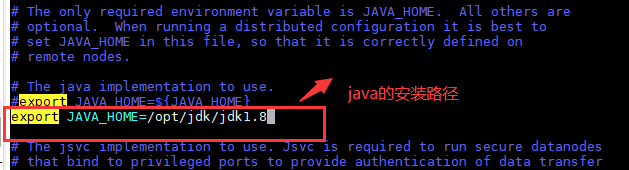
4.编辑hadoop-env.sh文件,配置JAVA_HOME的安装路径
(1)编辑命令:# vim /opt/hadoop/hadoop2.8/etc/hadoop/hadoop-env.sh
(2)文件内容:
export JAVA_HOME =/opt/jdk/jdk1.8如下图所示:
5.编辑core-site.xml文件,配置hadoop存储数据相关参数:
(1)编辑命令:#vim /opt/hadoop/hadoop2.8/etc/hadoop/core-site.xml
(2)添加内容:
<configuration>
<property>
<!-- 指定目录存储让hadoop存储数据文件 -->
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>Parent directory for other temporary directories.</description>
</property>
<property>
<!-- 指定默认文件系统 -->
<name>fs.defaultFS </name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. </description>
</property>
</configuration>
(3)创建存储文件目录:mkdir -p /app/hadoop/tmp
(4)授予权限:chmod 750 /app/hadoop/tmp
6.(没用到)Map Reduce配置,设置hadoop环境变量:
(1)编辑文件:# vim /etc/profile.d/hadoop.sh
(2)添加内容:
export HADOOP_HOME =/opt/hadoop/hadoop2.8(3)授权命令:# chmod +x /etc/profile.d/hadoop.sh
7.配置mapreduce,先在模板复制mapred-site.xml ,再编辑:
(1)复制文件:# cp /opt/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml.template
/opt/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml
(2)编辑命令:# vim /opt/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml
(3)添加内容:
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>localhost:54311</value>
<description>MapReduce job tracker runs at this host and port.
</description>
</property>
</configuration>
8.编辑hdfs-site.xml,配置HDFS
(1)编辑命令:#vim /opt/hadoop/hadoop2.8/etc/hadoop/hdfs-site.xml
(2)添加内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hduser_/hdfs</value>
</property>
</configuration>
(3)创建配置指定目录:mkdir -p /home/hduser_/hdfs
(4)授权:chmod 750 /home/hduser_/hdfs
9.初始化
(1)切换到:/opt/hadoop/hadoop2.8/bin目录下:
(2)执行:./hdfs name -format
只要不报错则初始化成功。如下图所示:


(3)切换到:cd /opt/hadoop/hadoop2.8/sbin
启动hadoop:# start-dfs.sh

(4)启动成功:输入网址:http://10.50.28.3:50070/验证:

输入:http://10.50.28.3:8088/cluster

参考文章:https://blog.csdn.net/zh_itroad/article/details/84805295
2.2.5 Spark安装
1.配置环境变量,编辑/etc/profile文件,使用命令:#vim /etc/profile
#Spark Config
export SPARK_HOME=/opt/spark/spark2.4
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bn:$PATH2..切换到/opt/spark/spark2.4/conf/目录下,对以下文件进行配置。
3.编辑spark-env.sh文件:
(1)复制spark-env.sh.template为spark-env.sh:
#cp /opt/spark/spark2.4/conf/spark-env.sh.template
/opt/spark/spark2.4/conf/spark-env.sh(2)编辑spark-env.sh:#vim /opt/spark/spark2.4/conf/spark-env.sh
(3)添加内容:
export SCALA_HOME=/opt/scala/scala2.12.10
export JAVA_HOME=/opt/jdk/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8/etc/hadoop
export SPARK_HOME=/opt/spark/spark2.4
#主机
export SPARK_MASTER_HOST=controller
export SPARK_MASTER_PORT=7077
4.编辑slaves
(1)复制slaves.template 为slaves:
#cp /opt/spark/spark2.4/conf/slaves.template /opt/spark/spark2.4/conf/slaves
(2)编辑slaves文件:#vim /opt/spark/spark2.4/conf/slaves
(3)添加内容:主机地址10.50.28.3 ,如下图所示:

直接在空白处添加所有Worker的IP,本机单节点的话可以直接写本机IP,也就是此节点既是master又是worker。
5.启动&停止
(1)切换到目录下:cd /opt/spark/spark2.4/sbin/
停止:stop-all.sh
启动:start-all.sh

6.输入http://10.50.28.3:8080/测试spark是否安装成功。

参考文章:
https://blog.csdn.net/cherlshall/article/details/88953090
2.5.6 mysql安装
(1)切换到:cd /opt/mysql/mysql5.7/bin
(2)初始化:
方式一:# mysqld --initialize --user=mysql --basedir=
/opt/mysql/mysql5.7 --datadir=/opt/mysql/mysql5.7/data
方式二:mysql_install_db --user=mysql --basedir=
/opt/mysql/mysql5.7/ --datadir=/opt/mysql/mysql5.7/data/

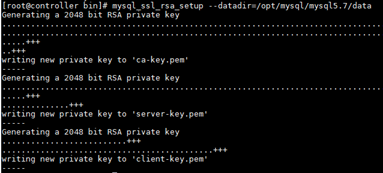
(3)# mysql_ssl_rsa_setup --datadir=/opt/mysql/mysql5.7/data
(4)复制:# cp /opt/mysql/mysql5.7/support-files/mysql.server /etc/init.d/mysql.server
(5)编辑:#vim /etc/init.d/mysql.server

(6)修改配置文件 vim/etc/my.cnf
| [root@jun ~]# vim /etc/my.cnf [client] port = 3306 socket = /tmp/mysql.sock [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' basedir=/opt/mysql/mysql5.7 datadir=/opt/mysql/mysql5.7/data socket=/tmp/mysql.sock #skip-grant-tables log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid lower_case_table_names = 1 sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION max_connections=5000 default-time_zone = '+8:00' ~ |
| [mysqld] basedir=/opt/mysql/mysql5.7 datadir=/opt/mysql/mysql5.7/data [mysql_safe] basedir=/opt/mysql/mysql5.7 datadir=/opt/mysql/mysql5.7/data port=3306 |
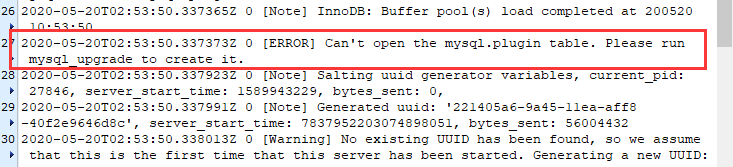
报错:
(1)错误一:
(2)错误二:
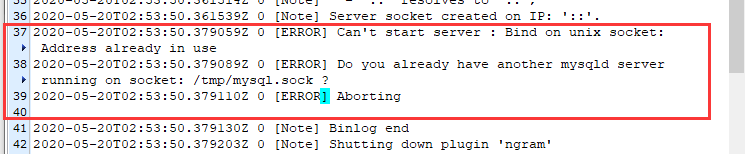
解决mysql报错:Do you already have another mysqld server running on socket
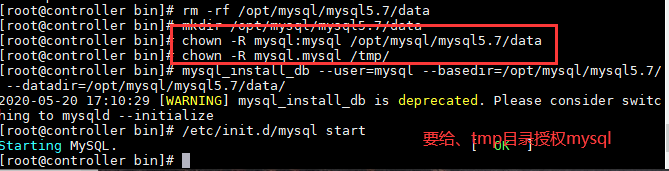
解决:
https://blog.csdn.net/weixin_33801856/article/details/93807230
2.5.7 scoop安装
1.配置环境变量:#vim /etc/profile
2.添加内容:
| #sqoop export SQOOP_HOME=/opt/sqoop/sqoop1.4.7 export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SQOOP_HOME}/bin:$PATH |
3.
3.使配置文件生效:#source /etc/profile
4.编辑文件:#sqoop-env.sh
(1)进入目录:#cd /opt/sqoop/sqoop1.4.7/conf
(2)复制文件:#cp sqoop-env-template.sh sqoop-env.sh
(3)编辑文件:vim /opt/sqoop/sqoop1.4.7/conf/sqoop-env.sh
(4)添加内容:
| #Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/opt/hadoop/hadoop2.8/ #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/opt/hadoop/hadoop2.8/ |
5.编辑configure-sqoop
(1)进入目录:#cd/opt/sqoop/sqoop1.4.7/bin
(2)编辑文件:vim /opt/sqoop/sqoop1.4.7/bin/configure-sqoop
(3)注释掉几个还未配置的选项,防止报错:
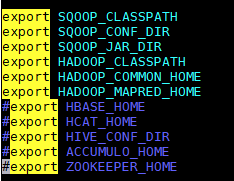
(4)移动mysql的驱动包到sqoop的lib目录下:
#mv /root/opt/mysql-connector-java-5.1.41.jar /opt/sqoop/sqoop1.4.7/lib/
(5)输入:
#sqoop list-databases --connect jdbc:mysql://10.50.28.3:3306/ --usename root --password root=其中10.50.28.3:3306为本机的ip地址:端口号,root= 为mysql数据库的用户名=密码。
执行后忽略警告,显示表的结构即表示安装成功。

参考文档:
https://blog.csdn.net/qq_21153619/article/details/81866722
















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











