






1、项目介绍
随着大数据和人工智能技术的迅猛发展,数据分析和信息挖掘在各行各业中扮演着日益重要的角色。特别是在招聘领域,通过对招聘数据的深度挖掘和智能分析,企业和求职者可以更加精准地掌握市场动态和人才需求。本文旨在设计并实现一个基于Python语言、Spark、Hive、Hadoop、Django框架、Echarts可视化、TensorFlow和Selenium爬虫技术的招聘数据分析系统。该系统以拉钩招聘网站为数据源,综合运用了数据采集、数据处理、数据分析和数据可视化等多种技术手段,为求职者、企业和招聘管理人员提供了全面、实时、精准的招聘数据分析服务。
一、技术栈:
Python语言、Spark、Hive、Hadoop、Django框架、Echarts可视化、selenuim爬虫技术、基于内容推荐算法、TensorFlow预测算法、拉钩招聘网站数据
二、系统功能模块:
0、数据采集: selenuim爬虫技术、拉钩招聘网站
1、可视化分析大屏(城市平均薪资Top10、工资区间分析、工资经验薪资分析、各省市招聘数据分布、公司人数分析、薪资Top10工作、最高薪资岗位)
2、注册登录
3、薪资分析(各行业薪资区间、各行业平均薪资)
4、经验学历分析(工作经验薪资人数分析、学历招聘人数分析)
5、行业分析(行业招聘个数柱状图、行业最高薪资玫瑰图)
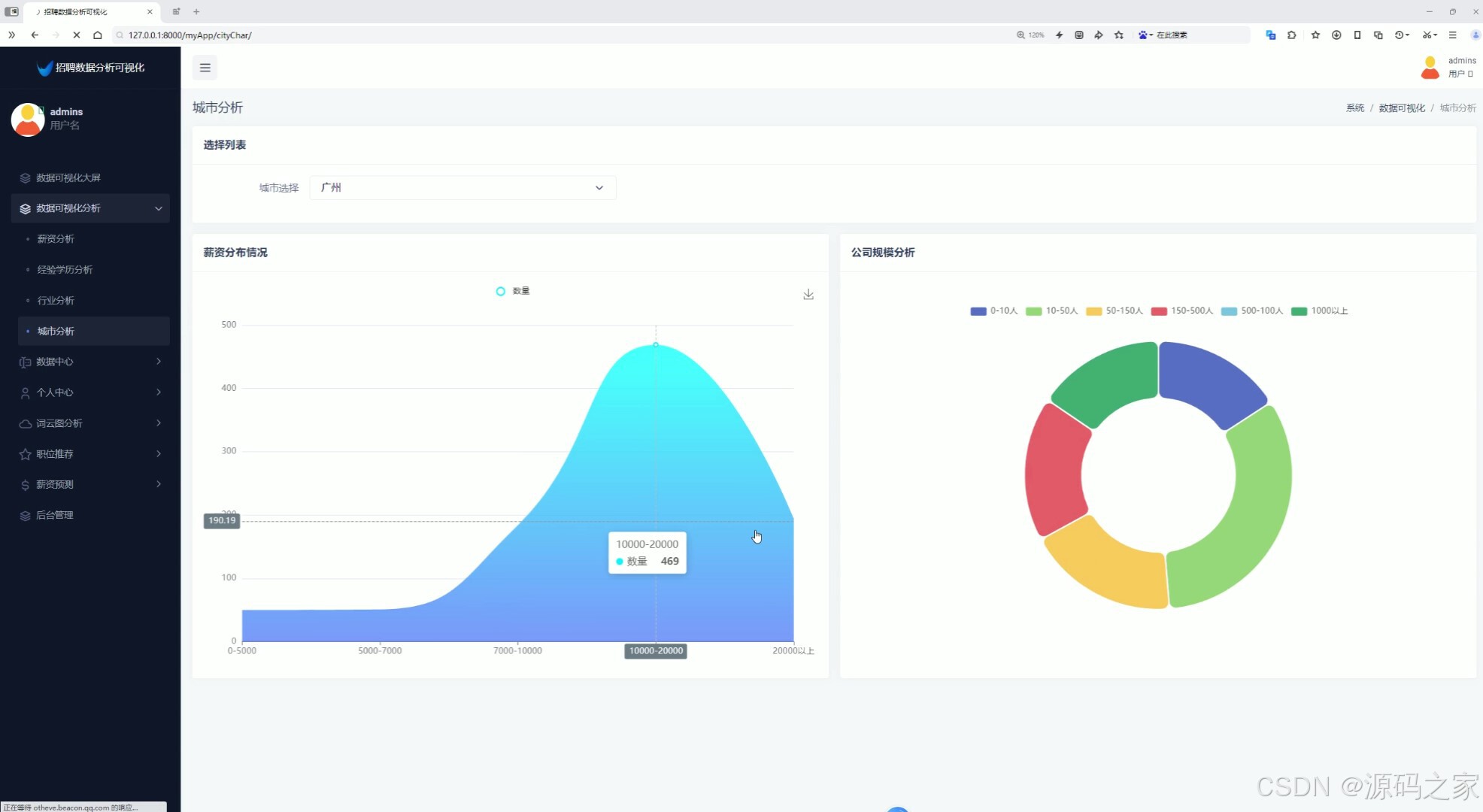
6、城市分析(城市选择查看薪资分布情况、公司规模分析)
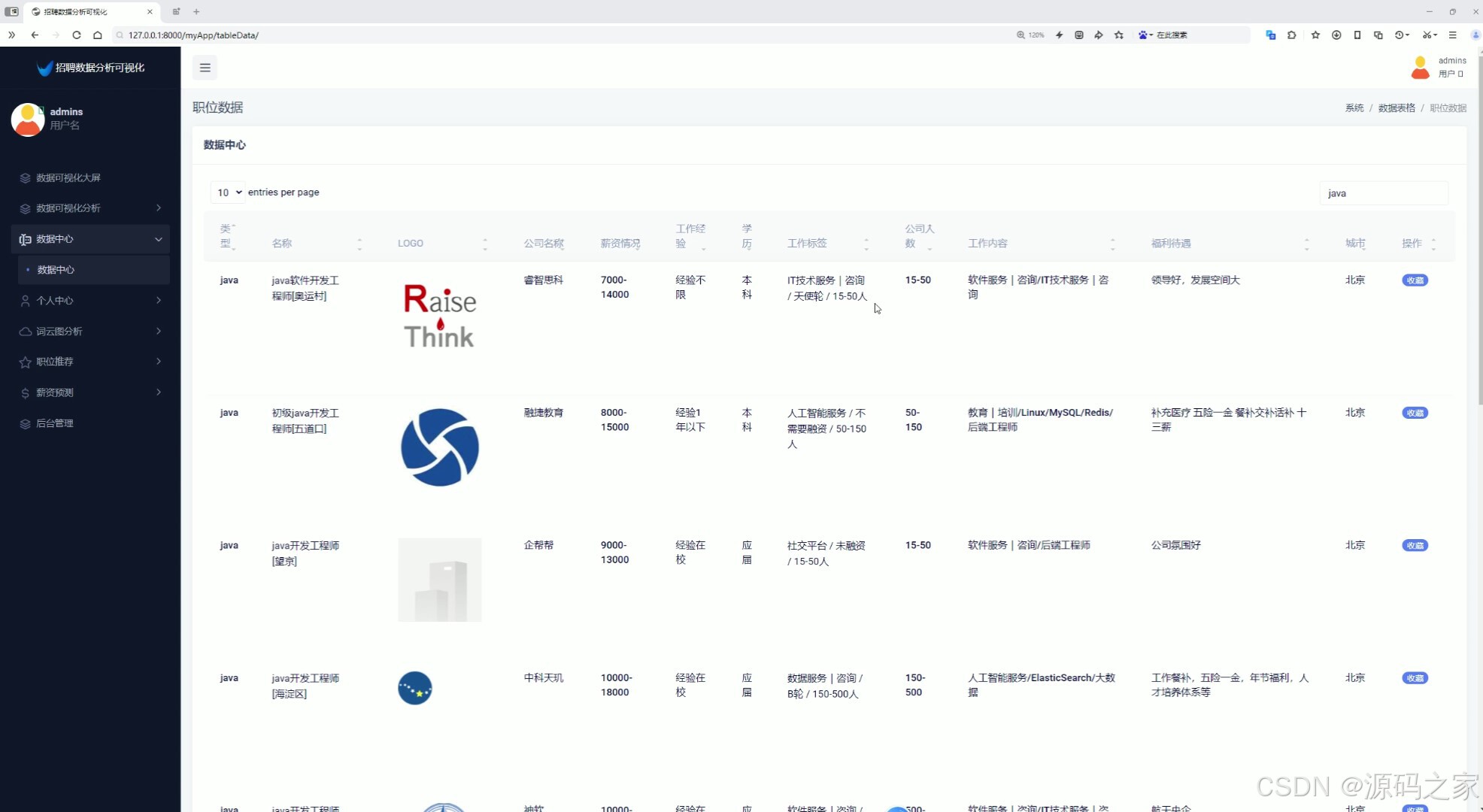
7、招聘数据中心(查看招聘数据、搜索、用户可以点击收藏岗位)
8、个人中心(修改密码)
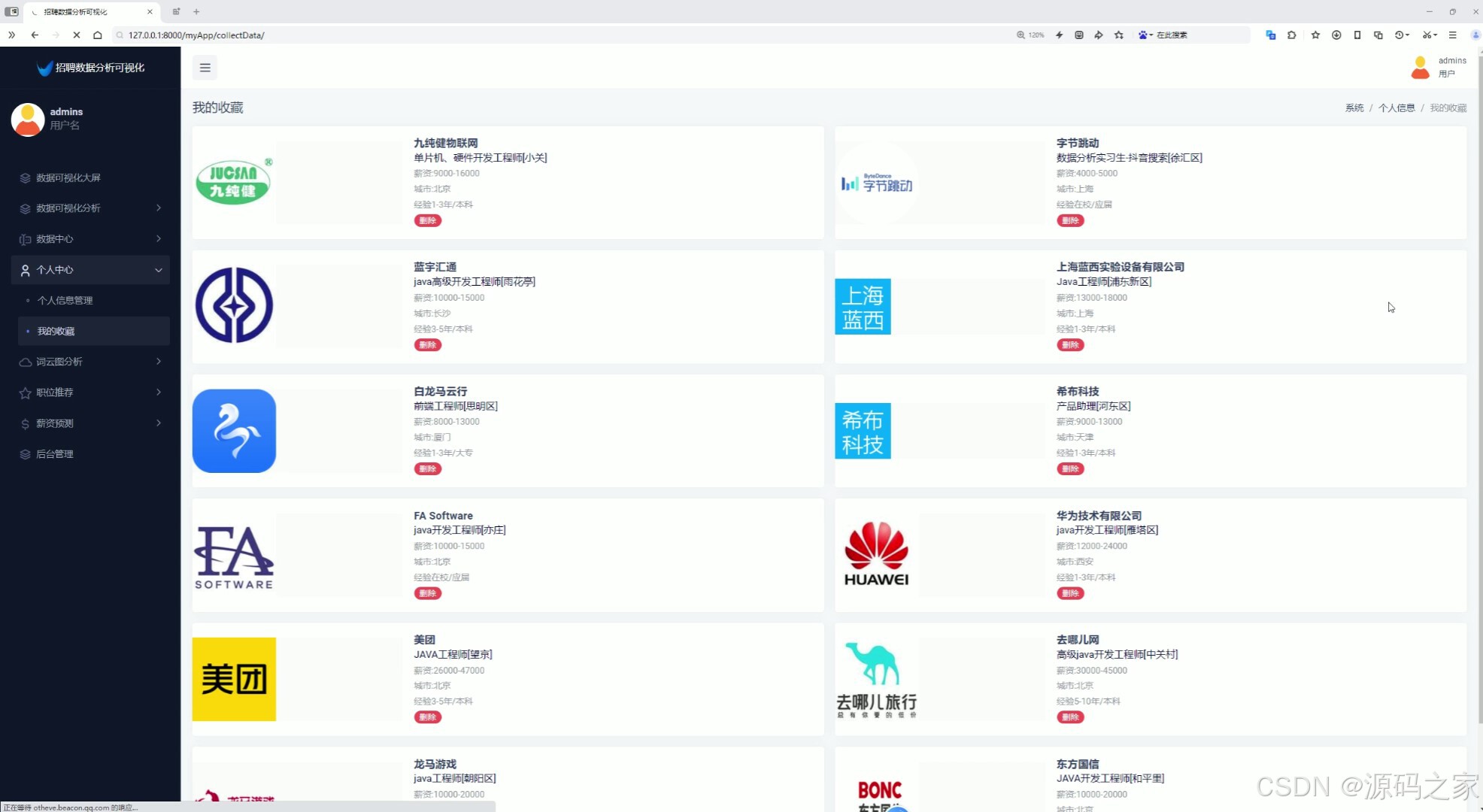
9、我的收藏
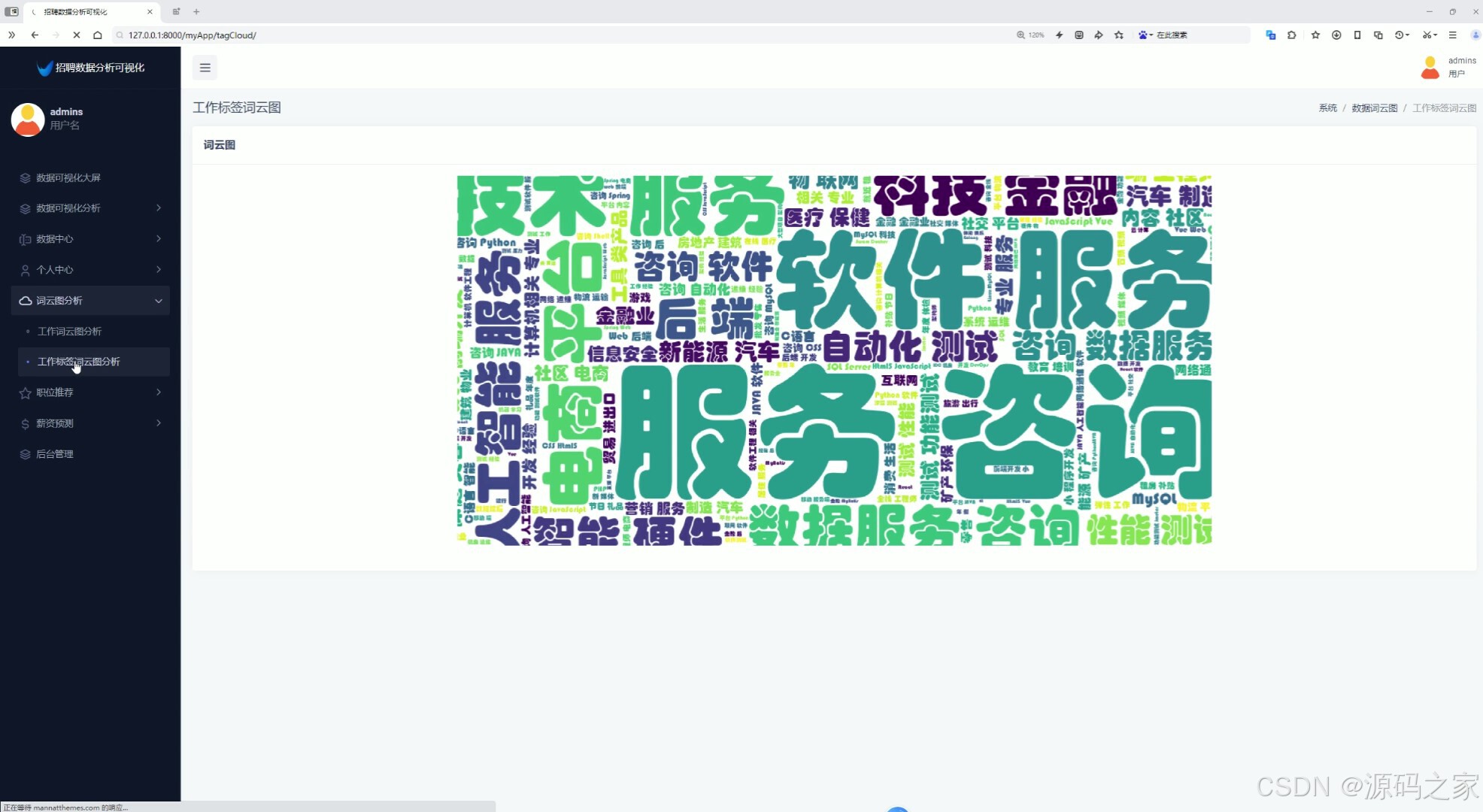
10、词云图分析(工作词云图分析、工作标签词云图分析)
11、职位推荐(采用基于内容推荐算法为用户推荐岗位)
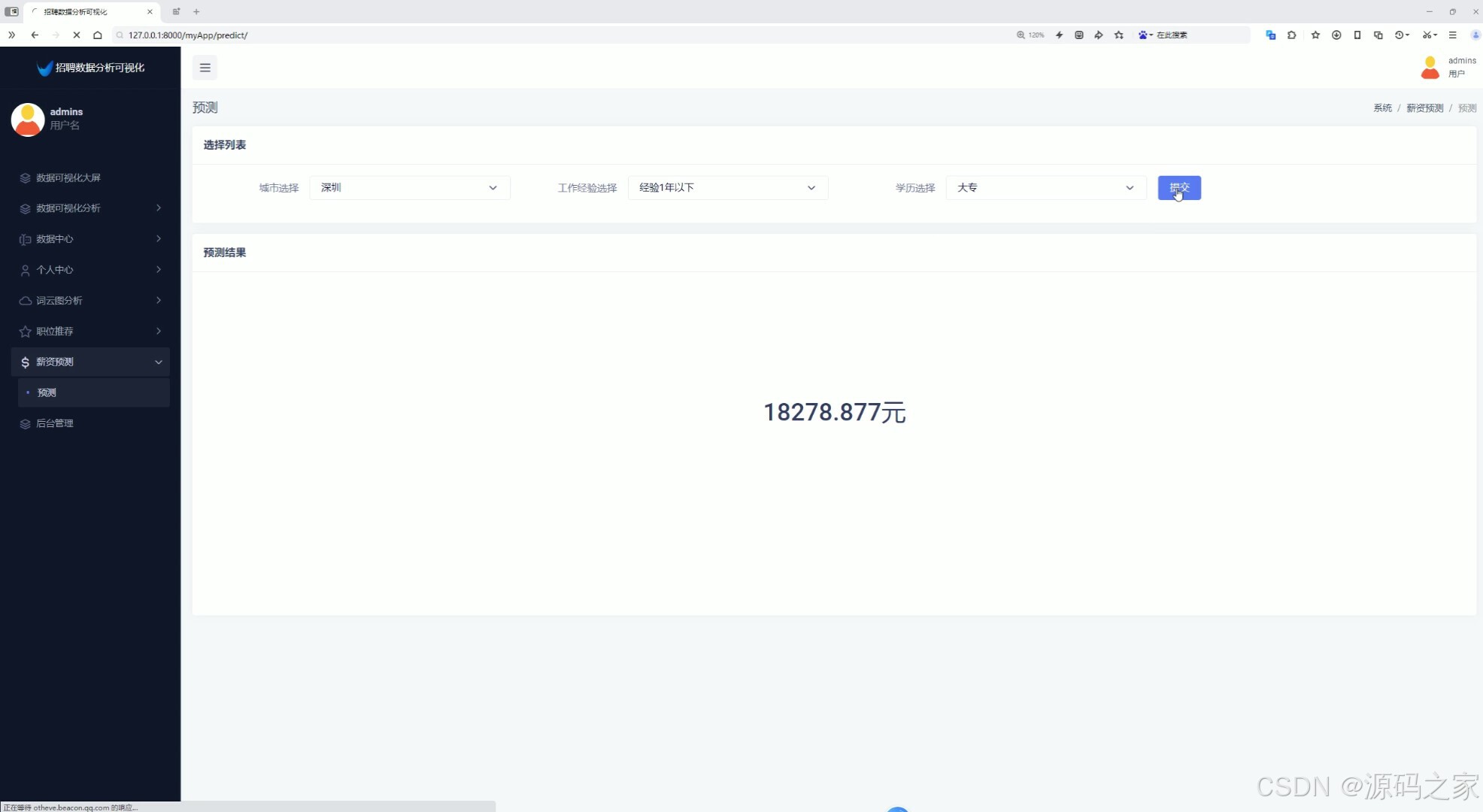
12、薪资预测(输入特征值,城市、工作经验、学历,预测薪资,根据TensorFlow预测算法)
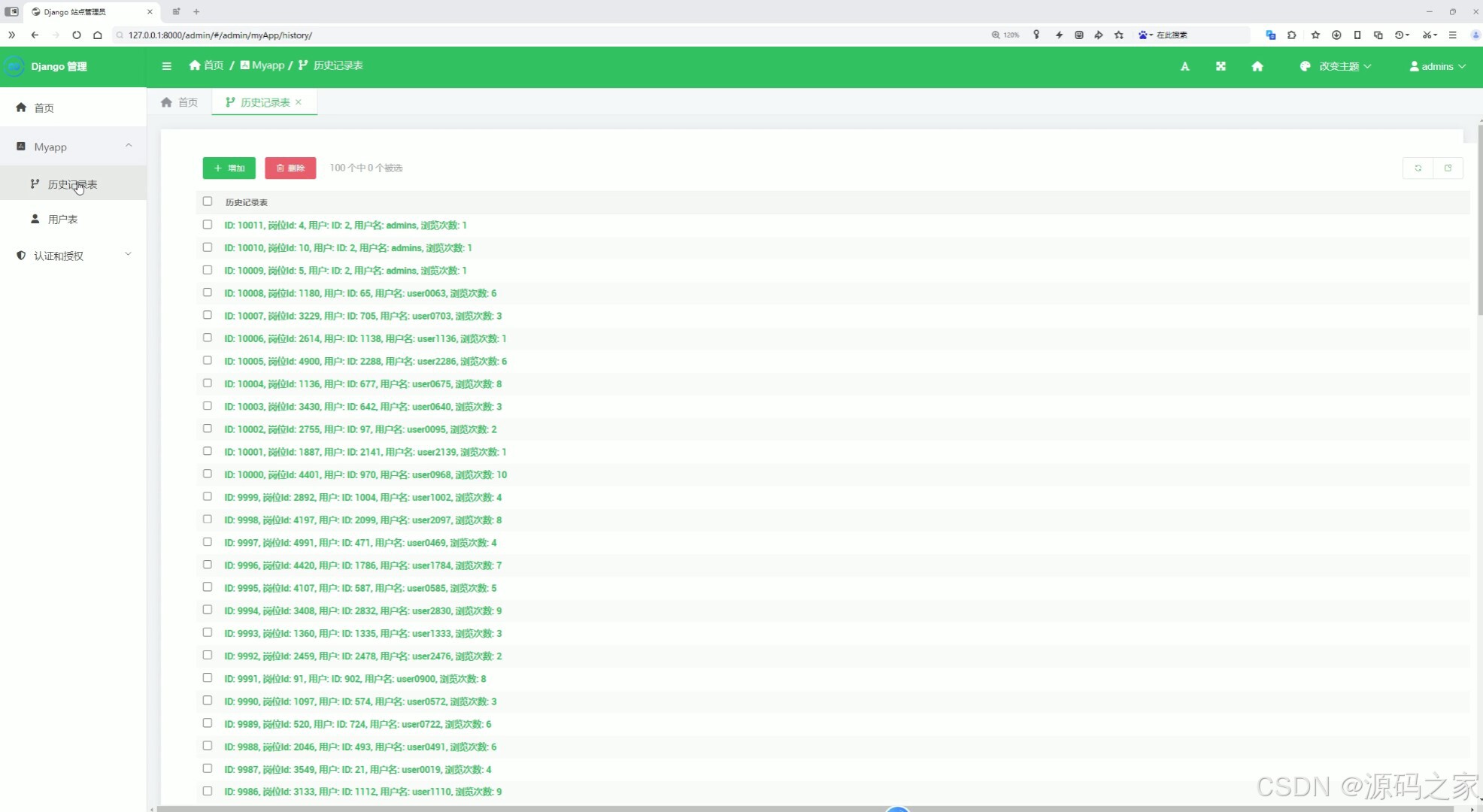
13、后台数据管理(用户数据管理、用户收藏记录管理)
2、项目界面
1、可视化分析大屏(城市平均薪资Top10、工资区间分析、工资经验薪资分析、各省市招聘数据分布、公司人数分析、薪资Top10工作、最高薪资岗位)
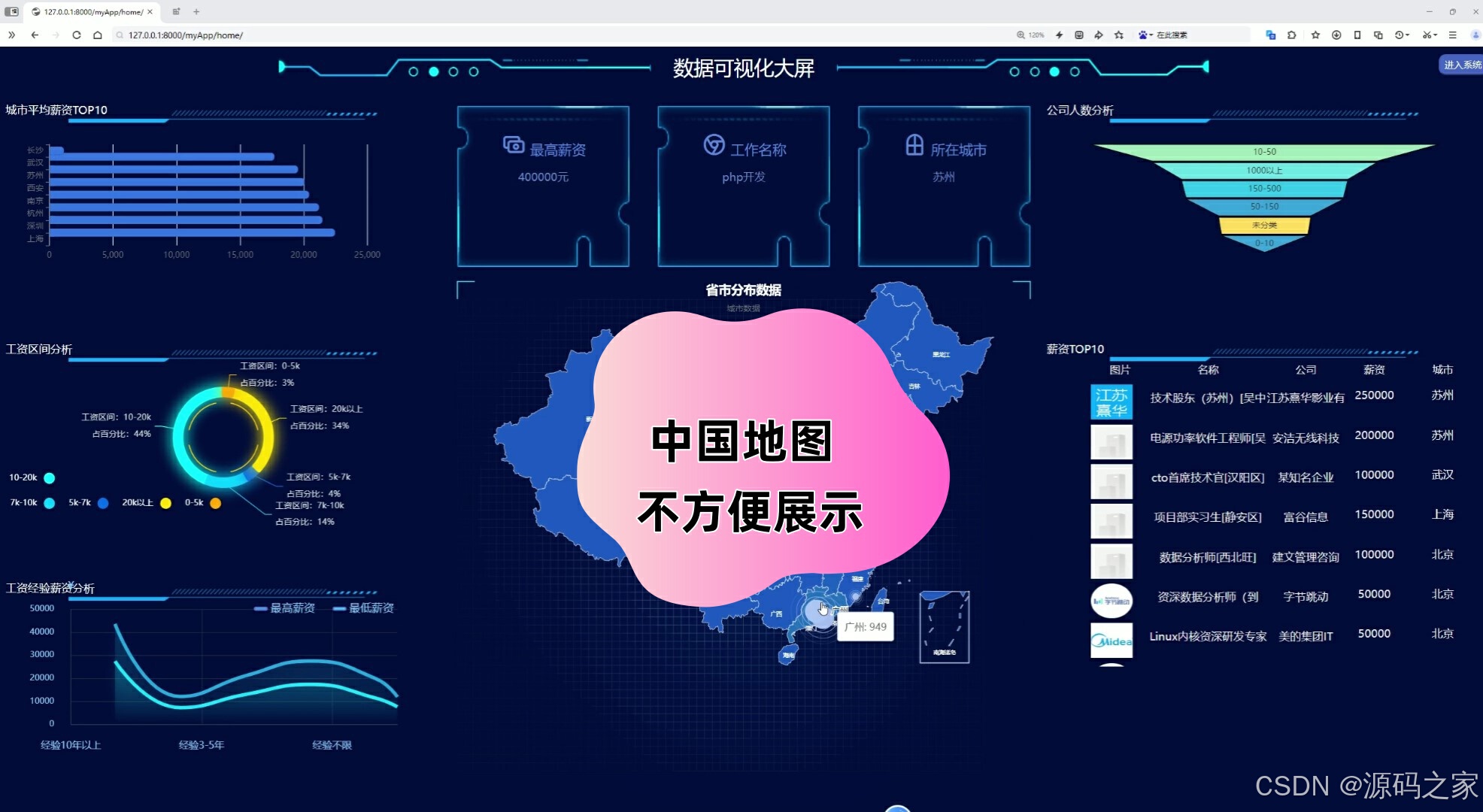
2、薪资分析(各行业薪资区间、各行业平均薪资)
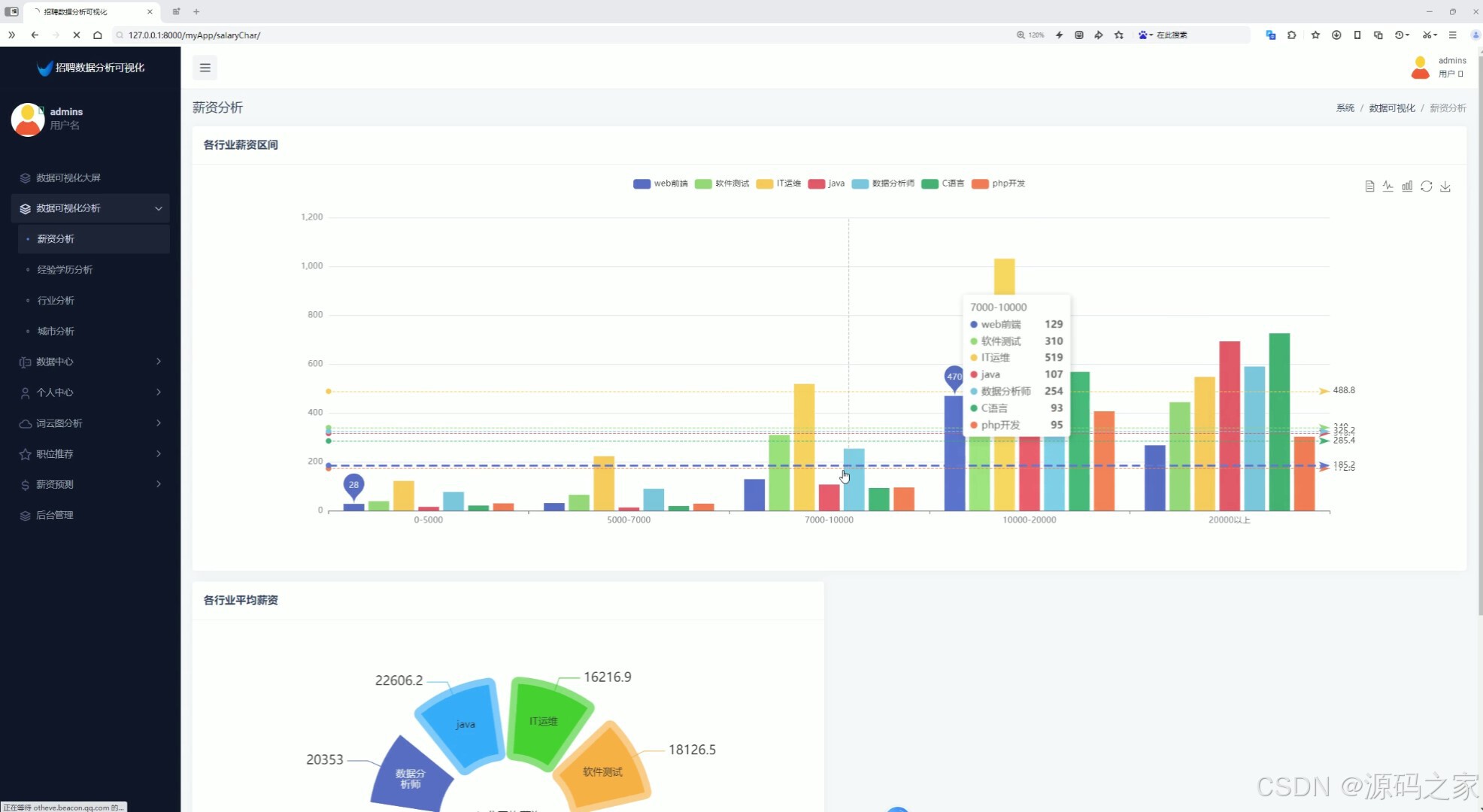
3、经验学历分析(工作经验薪资人数分析、学历招聘人数分析)
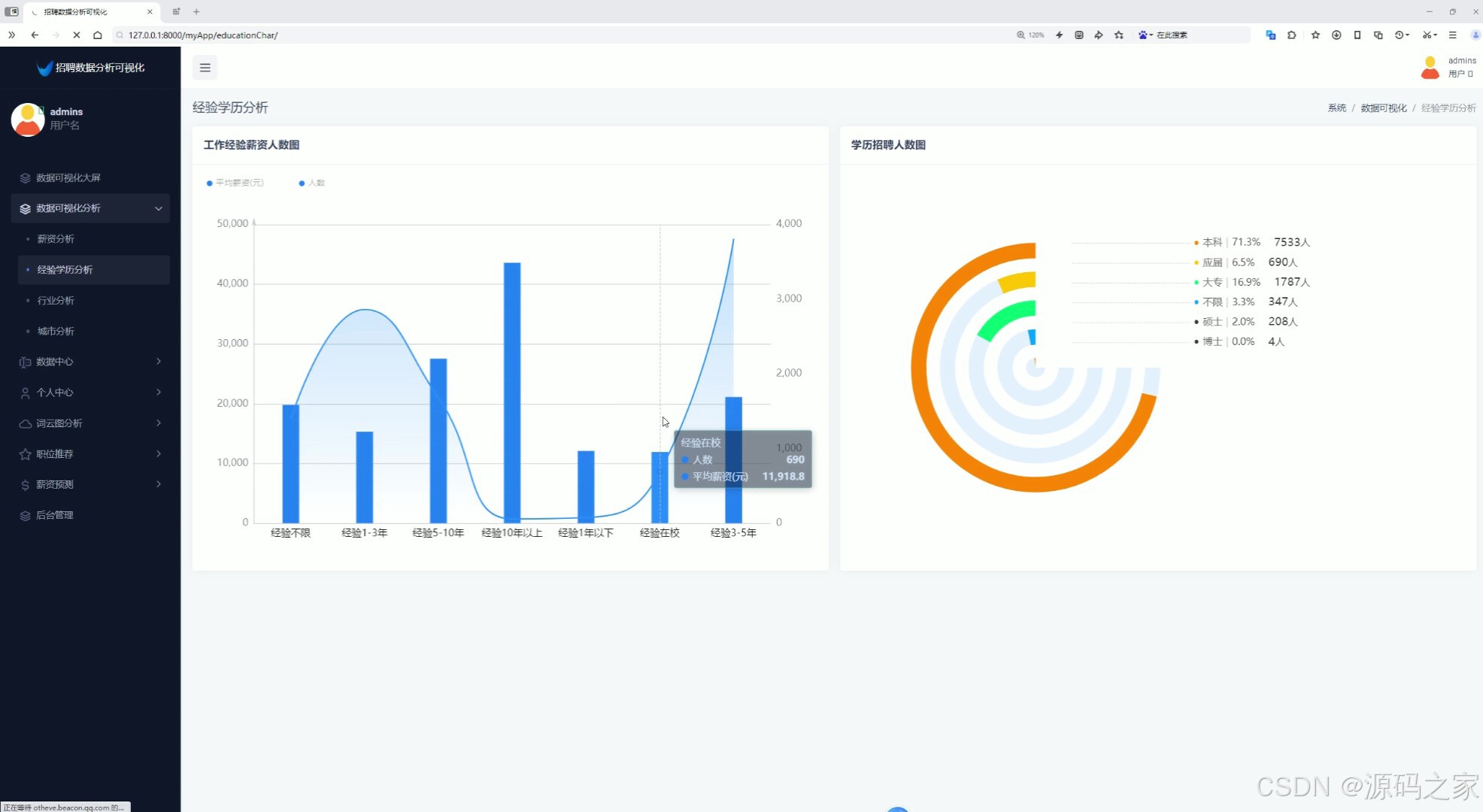
4、行业分析(行业招聘个数柱状图、行业最高薪资玫瑰图)
5、城市分析(城市选择查看薪资分布情况、公司规模分析
6、招聘数据中心(查看招聘数据、搜索、用户可以点击收藏岗位)
7、我的收藏
7、词云图分析(工作词云图分析、工作标签词云图分析)
8、职位推荐(采用基于内容推荐算法为用户推荐岗位)

9、薪资预测(输入特征值,城市、工作经验、学历,预测薪资,根据TensorFlow预测算法)
10、后台数据管理(用户数据管理、用户收藏记录管理)
11、注册登录
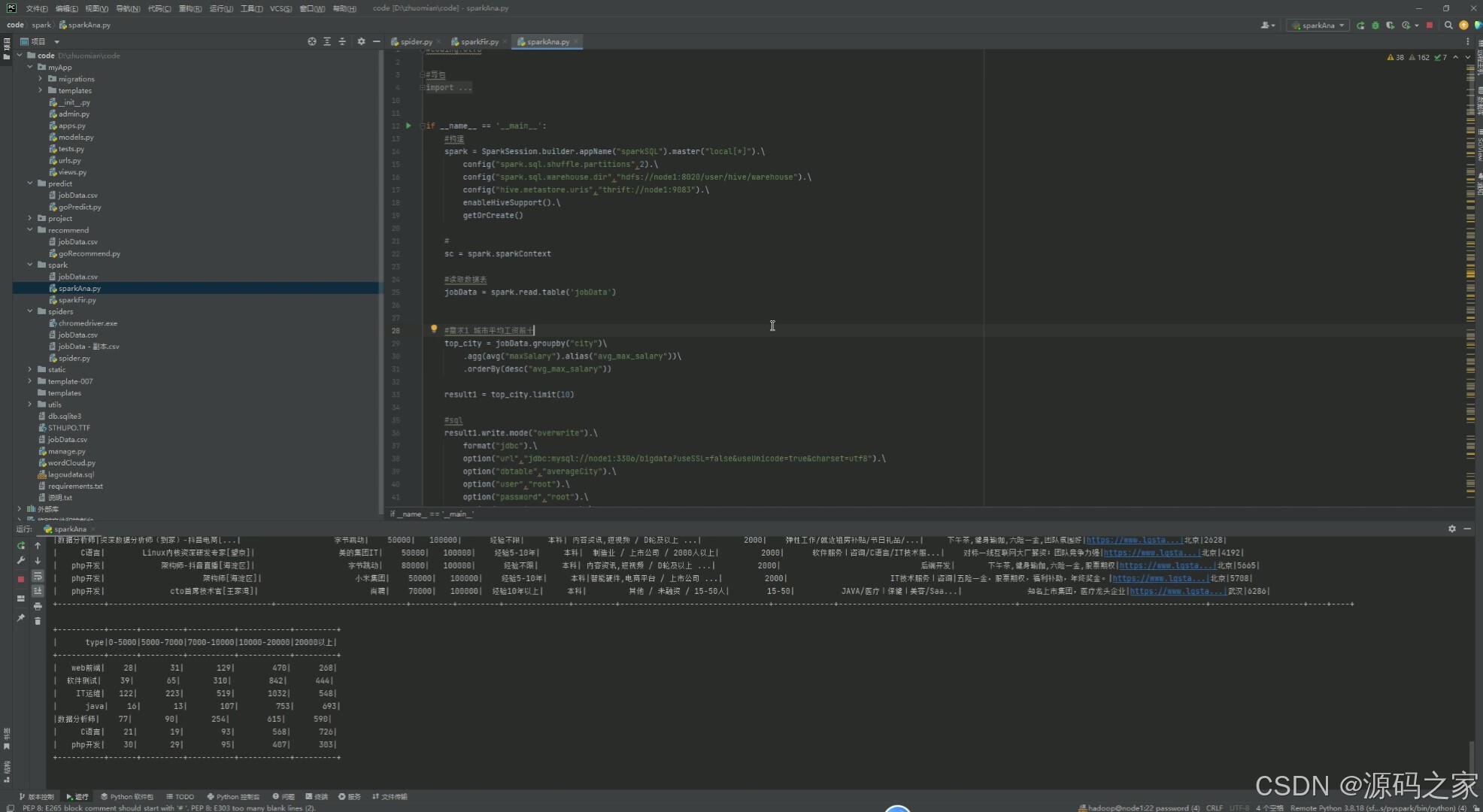
12、Spark数据分析
13、数据采集: selenuim爬虫技术、拉钩招聘网站
3、项目说明
(1)
随着大数据和人工智能技术的迅猛发展,数据分析和信息挖掘在各行各业中扮演着日益重要的角色。特别是在招聘领域,通过对招聘数据的深度挖掘和智能分析,企业和求职者可以更加精准地掌握市场动态和人才需求。本文旨在设计并实现一个基于Python语言、Spark、Hive、Hadoop、Django框架、Echarts可视化、TensorFlow和Selenium爬虫技术的招聘数据分析系统。该系统以拉钩招聘网站为数据源,综合运用了数据采集、数据处理、数据分析和数据可视化等多种技术手段,为求职者、企业和招聘管理人员提供了全面、实时、精准的招聘数据分析服务。
(2)
首先,系统实现了数据采集功能。利用Selenium爬虫技术,系统能够自动化地从拉钩招聘网站上抓取招聘信息,包括职位名称、薪资待遇、工作地点、公司规模、工作经验要求、学历要求等关键信息。同时,系统还具备数据预处理能力,能够对抓取到的数据进行清洗、去重、格式转换等操作,以确保数据的准确性和一致性。
在数据可视化方面,系统采用了Echarts可视化技术,构建了一个功能强大的可视化分析大屏。该大屏展示了城市平均薪资Top10、工资区间分析、工作经验薪资分析、各省市招聘数据分布、公司人数分析、薪资Top10工作、最高薪资岗位等多个维度的可视化图表。这些图表以直观、生动的方式呈现了招聘数据的整体趋势和局部特征,为求职者和招聘管理人员提供了重要的决策支持。
为了满足不同用户的需求,系统还实现了注册登录功能。用户可以通过注册账号,登录系统后享受个性化的数据分析服务。同时,系统还提供了薪资分析、经验学历分析、行业分析、城市分析等多个功能模块。在薪资分析模块中,系统可以展示各行业薪资区间和平均薪资,帮助求职者了解不同行业的薪资水平。在经验学历分析模块中,系统通过展示工作经验薪资人数分析和学历招聘人数分析,帮助求职者评估自己的竞争力。在行业分析模块中,系统通过行业招聘个数柱状图和行业最高薪资玫瑰图,展示了不同行业的招聘情况和薪资水平。在城市分析模块中,系统允许用户选择城市查看薪资分布情况,并对公司规模进行分析。
招聘数据中心是系统的核心功能模块之一。该模块提供了查看招聘数据、搜索和收藏岗位等功能。用户可以通过搜索关键词、筛选条件等方式,快速找到符合自己需求的岗位信息。同时,用户还可以点击收藏按钮,将感兴趣的岗位添加到个人中心的我的收藏中,方便日后查看和申请。
个人中心模块为用户提供了修改密码等个性化服务。用户可以随时登录个人中心,修改自己的密码,确保账号的安全性。此外,个人中心还展示了用户的收藏记录等信息,方便用户管理自己的数据和偏好。
在数据分析方面,系统采用了基于内容推荐算法和TensorFlow预测算法等多种技术手段。基于内容推荐算法可以根据用户的兴趣和行为,为用户推荐符合其需求的岗位信息。这种推荐方式不仅提高了用户的满意度和参与度,还促进了招聘信息的有效传播和利用。TensorFlow预测算法则用于薪资预测功能中。用户输入特征值(如城市、工作经验、学历等),系统即可根据预训练的TensorFlow模型预测出相应的薪资水平。这种预测方式不仅具有高度的准确性和可靠性,还能够帮助求职者更好地评估自己的薪资期望和市场价值。
此外,系统还实现了后台数据管理功能。管理员可以通过后台界面,对用户数据进行管理、对用户收藏记录进行管理等操作。这些功能不仅提高了系统的安全性和稳定性,还为管理员提供了便捷的数据管理工具。
(3)
综上所述,本文设计的招聘数据分析系统综合运用了多种技术手段和算法模型,为求职者、企业和招聘管理人员提供了全面、实时、精准的招聘数据分析服务。该系统不仅提高了招聘效率和质量,还促进了人才市场的健康发展和良性竞争。未来,我们将继续完善和优化系统功能,提高数据分析和预测的准确性,为更多用户提供更好的服务体验。
4、核心代码
#导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructType,StructField,IntegerType,StringType,FloatType
from pyspark.sql.functions import count,avg,regexp_extract,max
from pyspark.sql.functions import col,sum,when
from pyspark.sql.functions import desc,asc
if __name__ == '__main__':
#构建
spark = SparkSession.builder.appName("sparkSQL").master("local[*]").\
config("spark.sql.shuffle.partitions",2).\
config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse").\
config("hive.metastore.uris","thrift://node1:9083").\
enableHiveSupport().\
getOrCreate()
#
sc = spark.sparkContext
#读取数据表
jobData = spark.read.table('jobData')
#需求1 城市平均工资前十
top_city = jobData.groupby("city")\
.agg(avg("maxSalary").alias("avg_max_salary"))\
.orderBy(desc("avg_max_salary"))
result1 = top_city.limit(10)
#sql
result1.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","averageCity").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result1.write.mode("overwrite").saveAsTable("averageCity","parquet")
spark.sql("select * from averageCity").show()
#需求二 工资区间
jobData_classfiy = jobData.withColumn("salary_category",
when(col("maxSalary").between(0,5000),"0-5k")
. when(col("maxSalary").between(5000,7000),"5k-7k")
. when(col("maxSalary").between(7000,10000),"7k-10k")
. when(col("maxSalary").between(10000,20000),"10-20k")
. when(col("maxSalary")>20000,"20k以上")
. otherwise("未分类"))
result2 = jobData_classfiy.groupby("salary_category").agg(count('*').alias("count"))
#sql
result2.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","salarycategory").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result2.write.mode("overwrite").saveAsTable("salarycategory","parquet")
spark.sql("select * from salarycategory").show()
#需求3 工资经验分析
result3 = jobData.groupby("workExperience")\
.agg(avg("maxSalary").alias("avg_max_salary"),
avg("minSalary").alias("avg_min_salary"))\
.orderBy("workExperience")
#sql
result3.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","expSalary").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result3.write.mode("overwrite").saveAsTable("expSalary","parquet")
spark.sql("select * from expSalary").show()
#城市分布
result4 = jobData.groupby("city").count()
#sql
result4.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","addresssum").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result4.write.mode("overwrite").saveAsTable("addresssum","parquet")
spark.sql("select * from addresssum").show()
#需求5 人口区间
job_df = jobData.withColumn("people_num",when(col("companyPeople").rlike(r'-'),
regexp_extract(col("companyPeople"),r'(\d+)-(\d+)',1).cast("int"))
.otherwise(col("companyPeople").cast("int")))
people_classify = job_df.withColumn("people_category",
when(col("people_num").between(0,10),"0-10")
. when(col("people_num").between(10,50),"10-50")
. when(col("people_num").between(50,150),"50-150")
. when(col("people_num").between(150,500),"150-500")
.when(col("people_num").between(500, 1000), "500-1000")
. when(col("people_num")>1000,"1000以上")
. otherwise("未分类"))
result5 = people_classify.groupby("people_category").agg(count('*').alias("count"))
#sql
result5.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","peoplecategory").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result5.write.mode("overwrite").saveAsTable("peoplecategory","parquet")
spark.sql("select * from peoplecategory").show()
#top10
top_10_salary = jobData.orderBy(col("maxSalary").desc()).limit(10)
#sql
top_10_salary.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","salaryTop").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
top_10_salary.write.mode("overwrite").saveAsTable("salaryTop","parquet")
spark.sql("select * from salaryTop").show()
#需求6 薪资分析 行业薪资
result6 = jobData.groupBy("type").agg(
sum(when(col("maxSalary") <= 5000, 1).otherwise(0)).alias("0-5000"),
sum(when((col("maxSalary") > 5000) & (col("maxSalary") <= 7000), 1).otherwise(0)).alias("5000-7000"),
sum(when((col("maxSalary") > 7000) & (col("maxSalary") <= 10000), 1).otherwise(0)).alias("7000-10000"),
sum(when((col("maxSalary") > 10000) & (col("maxSalary") <= 20000), 1).otherwise(0)).alias("10000-20000"),
sum(when(col("maxSalary") > 20000, 1).otherwise(0)).alias("20000以上")
)
#sql
result6.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typeSalary").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result6.write.mode("overwrite").saveAsTable("typeSalary","parquet")
spark.sql("select * from typeSalary").show()
#需求7 行业平均薪资
result7 = jobData.groupby("type").agg(avg(col("maxSalary")).alias("avg_max_salary"))
#sql
result7.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","averageType").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result7.write.mode("overwrite").saveAsTable("averageType","parquet")
spark.sql("select * from averageType").show()
##需求 经验平均薪资和个数
result8 = jobData.groupby("workExperience").agg(
avg(col("maxSalary")).alias("avg_max_salary"),
count('*').alias("count")
)
#sql
result8.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","averageExperience").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result8.write.mode("overwrite").saveAsTable("averageExperience","parquet")
spark.sql("select * from averageExperience").show()
#需求9 学历
result9 = jobData.groupby("education").agg(
count('*').alias("count")
)
#sql
result9.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","educationCount").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result9.write.mode("overwrite").saveAsTable("educationCount","parquet")
spark.sql("select * from educationCount").show()
#行业个数
result10 = jobData.groupby("type").agg(
count('*').alias("count")
)
#sql
result10.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typeCount").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result10.write.mode("overwrite").saveAsTable("typeCount","parquet")
spark.sql("select * from typeCount").show()
#需求11 各类型最大值
result11 = jobData.groupby("type").agg(
max(col("maxSalary")).alias("max_salary")
)
#sql
result11.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typeMax").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result11.write.mode("overwrite").saveAsTable("typeMax","parquet")
spark.sql("select * from typeMax").show()
#各城市薪资情况
conditions = [
(col("maxSalary") <= 5000, '0-5000'),
((col("maxSalary") > 5000) & (col("maxSalary") <= 7000), '5000-7000'),
((col("maxSalary") > 7000) & (col("maxSalary") <= 10000), '7000-10000'),
((col("maxSalary") > 10000) & (col("maxSalary") <= 20000), '10000-20000'),
(col("maxSalary") > 20000, '20000以上')
]
result12 = jobData.groupby("city").agg(
*[count(when(condition,1)).alias(range_name) for condition,range_name in conditions]
)
#sql
result12.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","citySalary").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result12.write.mode("overwrite").saveAsTable("citySalary","parquet")
spark.sql("select * from citySalary").show()
#城市人数
conditionsTwo = [
(col("people_num") <= 10, '0-10'),
((col("people_num") > 10) & (col("people_num") <= 50), '10-50'),
((col("people_num") > 50) & (col("people_num") <= 150), '50-150'),
((col("people_num") > 150) & (col("people_num") <= 500), '150-500'),
((col("people_num") > 500) & (col("people_num") <= 1000), '500-1000'),
(col("people_num") > 1000, '1000以上')
]
result13 = job_df.groupby("city").agg(
*[count(when(condition,1)).alias(range_name) for condition,range_name in conditionsTwo]
)
#sql
result13.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","cityPeople").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result13.write.mode("overwrite").saveAsTable("cityPeople","parquet")
spark.sql("select * from cityPeople").show()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









