







参考视频:源码学院(java架构知识——HashMap底层实现和原理(源码解析)_哔哩哔哩_bilibili)
Java7:数组+链表

在调用put()时,其实执行的是先计算出key的hash值,再根据Hash值计算出Index决定了它存在数组中的哪个位置。
数组中存的是Entry,每个Entry中存的是key,value,hash,next。
上述图中的各个key/value实体的hash值如图:

当key为刘一进来时,存储位置Index为4,那么就放在数组中下标为4的地方。接着陈二存放。到了张三时,存储位置又是4,但是索引为4的地方已经存了刘一,此时如果把张三直接放入索引为4的地方,就会把刘一覆盖掉。于是就出现了链表的方式来解决:将刘一向后移动一个位置,然后把张三放到索引为4的存储空间中,并修改张三的next指向刘一,形成一个单向链表。所以HashMap的底层数据结构是数组+链表。
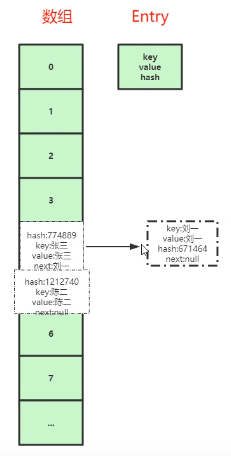
同理,等到key为Monkey的数据来的时候,计算得到的index也是4,此时就需要把原来index为4的张三和刘一都向后移动一个位置,将Monkey放进来,并修改next指向张三。

在执行get()获取元素时,get()中同样会根据key计算hash值,再计算下标。假设现在要获取的是key为刘一的value,计算出来的index是4,就去数组中下标为4的地方寻找,发现索引为4的地方存储的hash与刘一的hash不一致,说明不是当前元素,那么就会看索引为4的这个元素的next是否为空,如果为空,说明不存在要找的元素,如果不为空,那就去看next指向的元素hash值是否一致,如果一致,就获取value,如果不一致,继续看next是否为空,依次类推,直到找到hash一致的key。

链表:查找慢,插入删除快。
红黑树:查找快,插入删除慢。(与链表对比)
Java8:数组+链表+红黑树
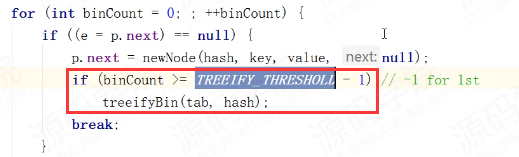
在查找时需要遍历链表逐一对比,时间复杂度为O(n)。当链表越来越长时,查找的速度就会变慢。所以在java8中链表的长度达到阈值(阈值为8)时会变成红黑树。
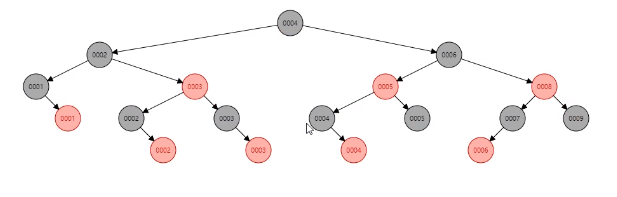
红黑树的结构是根据hash值进行比较的,小于中间节点的在左侧,大于中间节点的在右侧,直到对比出等于某个节点时表明找到该元素。
HashMap线程安全问题:
在调用get()时是线程安全的。
在调用put()发生数组扩容的时候是线程不安全的。分析:假设现在有并发线程A和B,当A线程来get()一个key为刘一的值时,计算出来了一个hash,但此时线程B在执行put()时发生了扩容,就会导致原来的元素位置可能发生变化,比如刘一原来在索引为4的位置,扩容之后被放到了索引为6的位置,而这个时候线程A仍然根据刚才算出来的hash去下标为4的地方获取刘一,显然得到的结果是空。
线程不安全,key/value可为空。

















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











