







白交 发自 凹非寺
量子位 | 公众号 QbitAI
Flash is all you need!
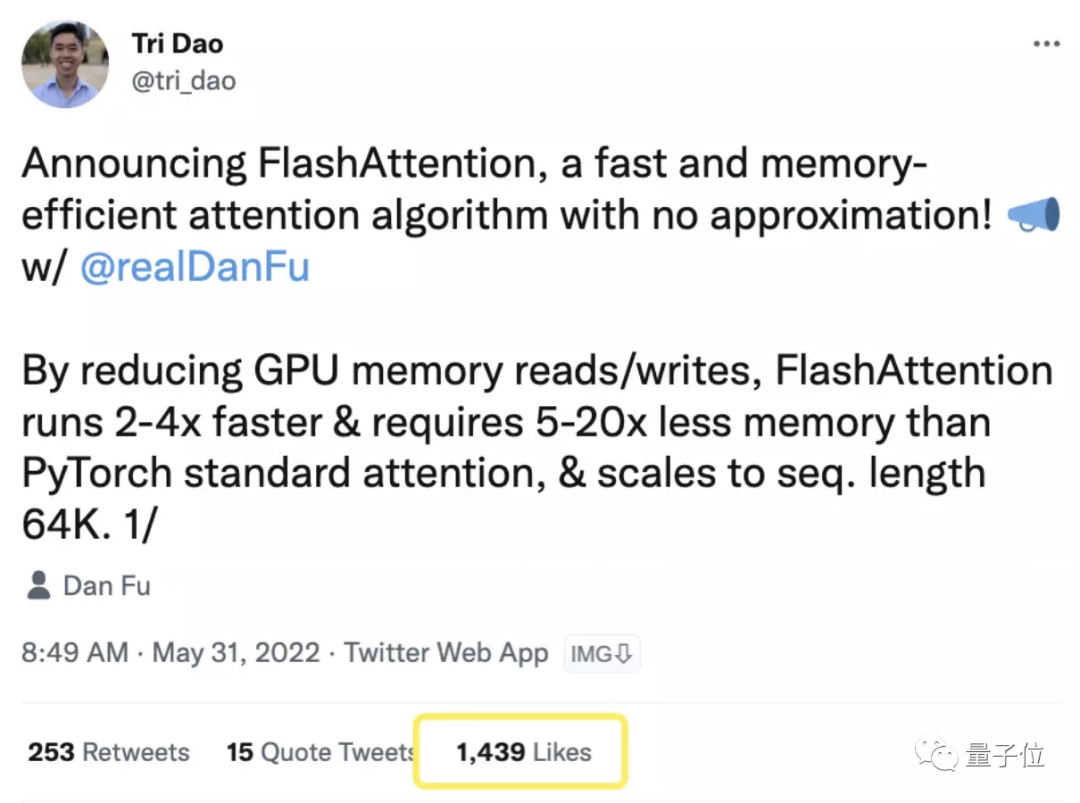
最近,一个超快且省内存的注意力算法FlashAttention火了。
通过感知显存读取/写入,FlashAttention的运行速度比PyTorch标准Attention快了2-4倍,所需内存也仅是其5%-20%。
而它的表现还不止于此。
训练BERT速度相较于MLPerf训练记录提升15%;
训练GPT-2的速度提高3.5倍;
训练Transformer的速度比现有基线快。
网友们纷纷表示惊叹:Great Job!这项工作对我来说很有用。

来看看这是一项什么样的研究~
FlashAttention
本文提出了一种IO感知精确注意力算法。
随着Transformer变得越来越大、越来越深,但它在长序列上仍然处理的很慢、且耗费内存。(自注意力时间和显存复杂度与序列长度成二次方)
现有近似注意力方法,在试图通过去牺牲
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2
2











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









