






明敏 发自 凹非寺
量子位 | 公众号 QbitAI
你敢信?大熊猫都会打牌了!

看这毛茸茸的脑袋、抓牌的动作……
而这其实都是AI生成的,还是零样本那种。
这就是谷歌最新大语言模型VideoPoet。
它不仅没有用视频领域常用的扩散模型,还零样本实现了SOTA。相较于此前一些模型,画面更加稳定、动作更加逼真,清晰度也直线up。

和Bard再合作一下,轻松搞定1分钟长的视频小片,从脚本到画面全部不用人类插手。

这效果,让网友们直呼:视频生成进化速度也太快了吧。

不少人都表示想玩!

有人还说,VideoPoet效果这么好,看来Runway和Pika要加速了!
画面逼真动作稳定
具体来看VideoPoet的能力非常全面。包括:
文本-视频
图像-视频
视频编辑
风格化处理
画面补充
文本到视频任务,视频输出长度可调整,而且可以基于文本内容应用一系列动作和风格。

图像到视频任务,则能让静态图片动起来。比如一些世界名画和照片,都可生成视频。

同时也能调整视频风格,需要额外输入一些文本,然后模型会预测视频的光照和深度信息。
比如输入“铁狮子在熔炉的火光中咆哮”,原本无厘头的太阳花狮子就变得凶猛威严起来。

当然也能进行视频编辑,比如让视频中的机器人随意运动、背景中加上烟雾等,都是输入文字指令即可实现。

或者是输入图像,然后修改它的动作。让蒙娜丽莎转动身体、打哈欠。

以及可调整镜头动作。基本的缩放、弧线、航拍镜头都可搞定。

如果想让扩充视频画面、增加视频元素,VideoPoet也能实现。

值得一提的是,VideoPoet还可以根据视频配乐。
这也是让不少网友感到惊讶的地方。

比如先让VideoPoet生成一段小熊打架子鼓的视频,然后不给它任何文本提示,VideoPoet根据画面内容自己生成了音频。
如果想要生成更长的视频,可以通过输入视频的最后一秒画面让VideoPoet预测下一段视频,反复多次即可实现。
如下案例时长约为10秒。

用LLM零样本生成视频
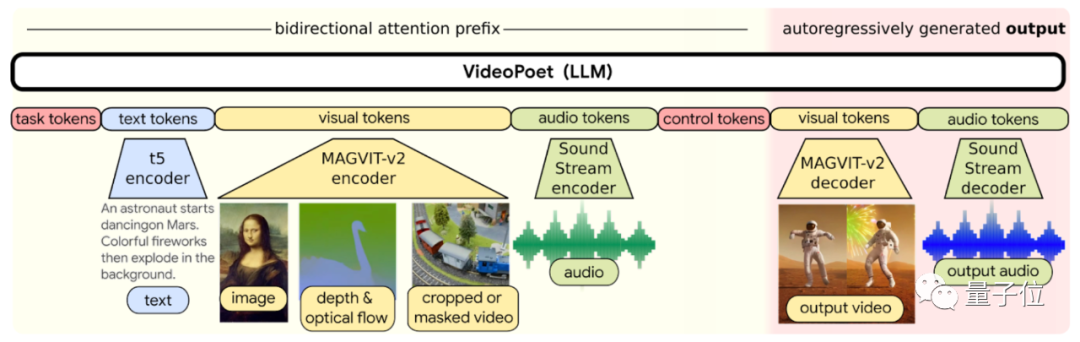
不仅是生成效果好,VideoPoet还有一个优势在于,以LLM为基础,它能更方便利用现有大模型进行改进。
比如VideoPoet就使用了T5的编码器。

不过由于大语言模型使用离散token,使得它生成视频具有一定挑战性。
与自然语言不同,人类对视觉世界尚未演化出最佳的词汇表达。
通过视频/音频tokenizer可以来克服这一问题。
它们能将视频和音频编码为离散token,也可将其转换为原始表示。
VideoPoet正是基于这一原理实现。
它利用MAGVIT V2来搞定视频图像表示,SoundStream搞定音频表示。
前者是谷歌CMU团队在今年10月提出的方法,该方法实现了语言模型首次在ImageNet基准上击败扩散模型。
后者是一个端到端神经音频解码器。
具体来看VideoPoet的框架。它支持文本、视觉、音频输入,分别可利用t5、MAGVIT V2、SoundStream的编码器。
然后再自回归生成输出。
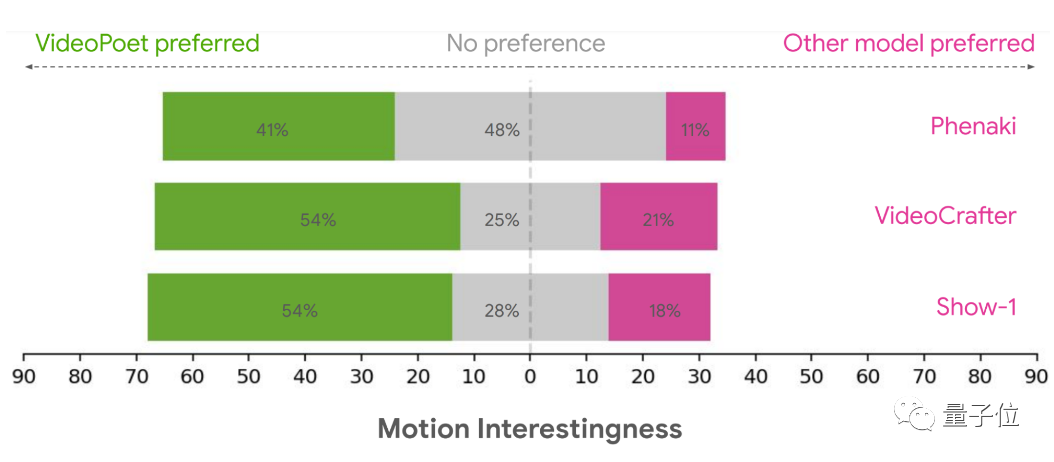
实验结果方面,在提示词与生成结果的吻合度方面,VideoPoet超过多个扩散模型。

生成动作方面的优势更加明显。
这项工作由谷歌研究带来,作者是两位软件工程师Dan Kondratyuk和David Ross。
据Dan透露,VideoPoet的论文也会马上上线。
参考链接:
[1]https://sites.research.google/videopoet/
[2]https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html
— 完 —
点这里👇关注我,记得标星哦~
















 6
6











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









