






明敏 发自 凹非寺
量子位 | 公众号 QbitAI
为啥GPT-4o mini能登顶大模型竞技场??
原来是OpenAI会刷分呀。

这两天,lmsys竞技场公布了一份充满争议的榜单。其中才面世不久的GPT-4o mini和满血版并列第一,把Claude 3.5 Sonnet甩在身后。
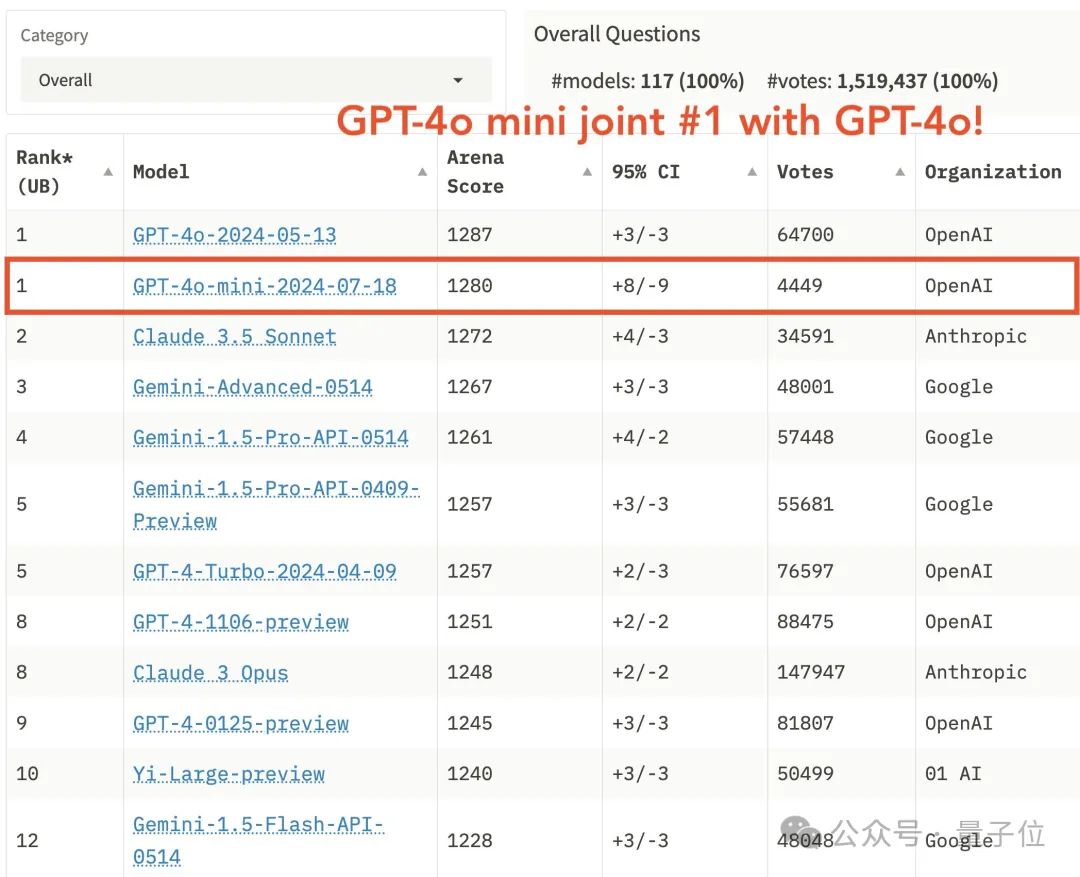
结果网友炸锅了,大家凭体感觉得这不可能。

哪怕后面lmsys做过一次声明,表示大家别只看总榜,还要更关注细分领域的情况。也没能让大家满意,不少人觉得lmsys就是从OpenAI那收钱了。
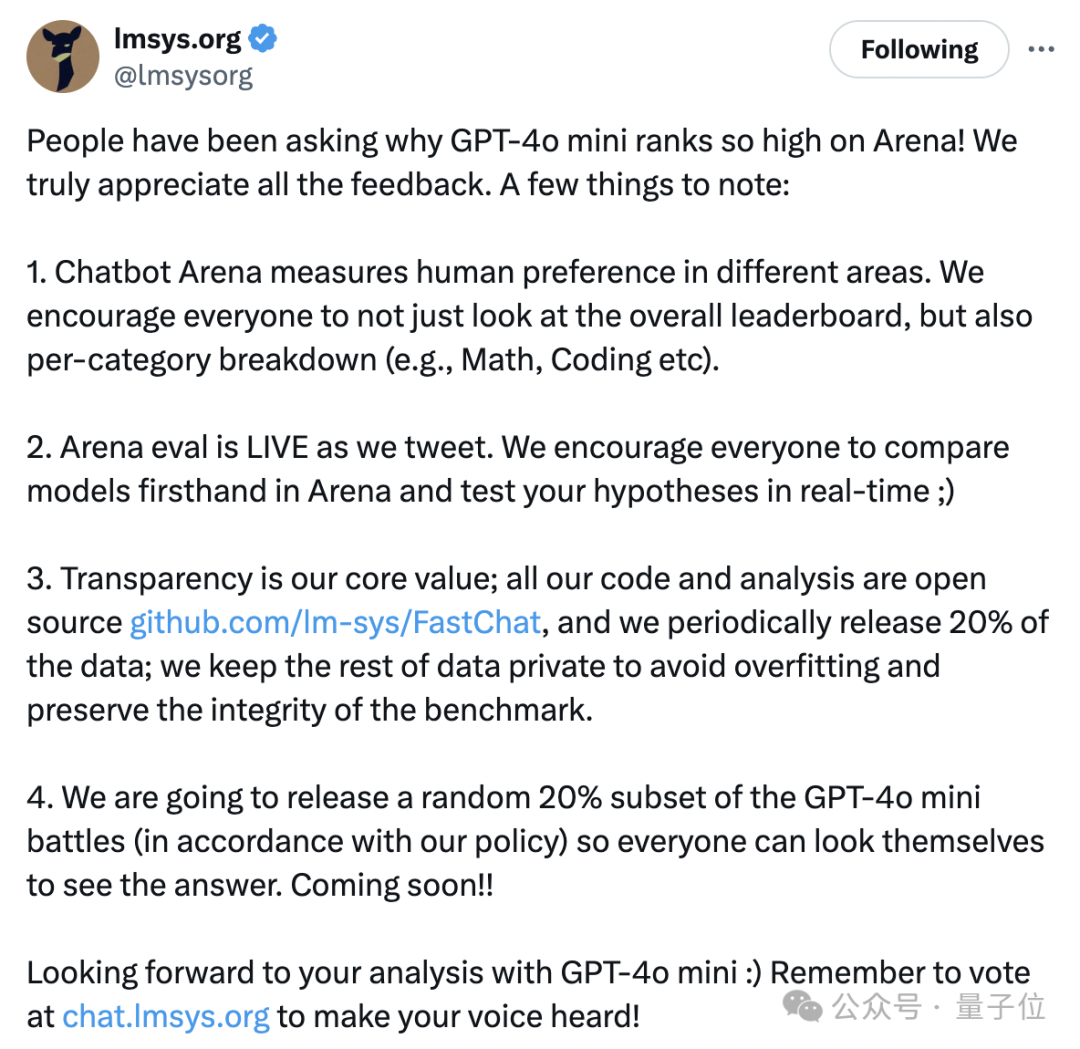
终于,官方晒出了一份完整数据,展示了GPT-4o mini参与的1000场battle,包括在不同语言下和不同模型的PK情况。
所有人现在都能查看这些结果。
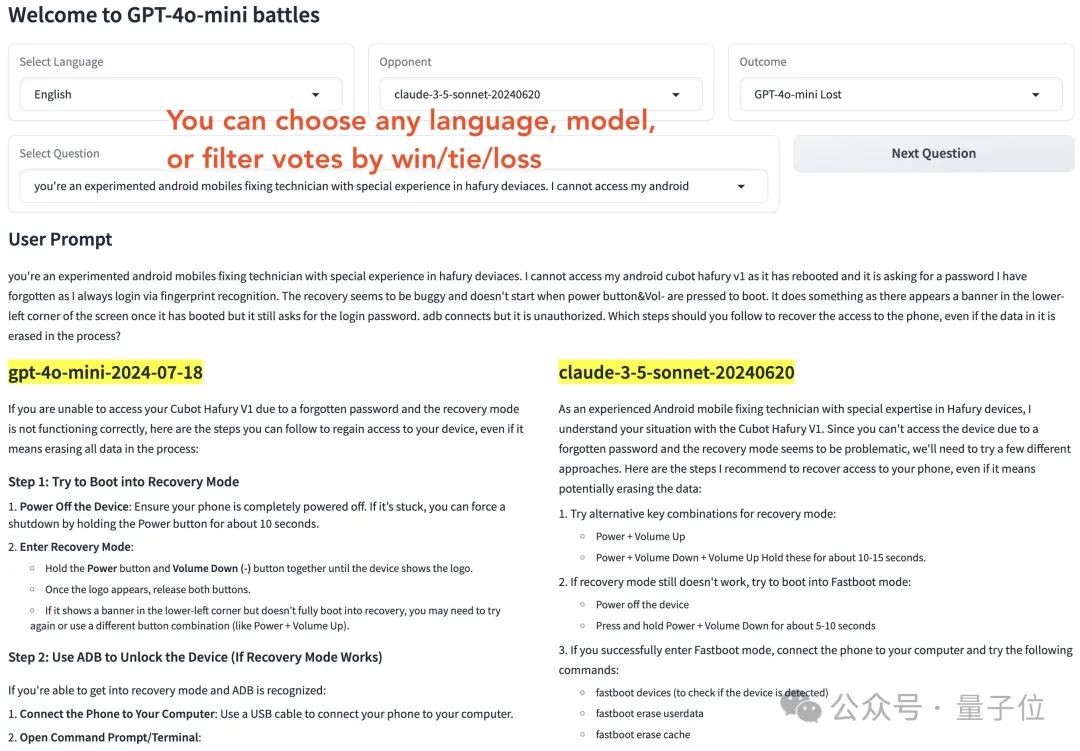
大家仔细一瞅,找到了问题所在,GPT-4o mini能赢Claude 3.5 Sonnet靠的是三大关键:
拒绝回答次数更少
更详细的回答、总是愿意提供额外信息
回答格式更清晰明了
这……确实有点道理啊!
网友表示,自己在竞技场中如果遇到有的模型拒绝回答,他就会觉得模型弃权比赛,因此更愿意判另一个模型胜出。
而且更清楚的回答格式,也能让人更容易找到信息。
这不就和老师判卷是一个道理么?书写工整、格式清晰或者“多写点总没错”的卷子,总是能多捞点分数……OpenAI原来是拿捏住了人类的心理啊。
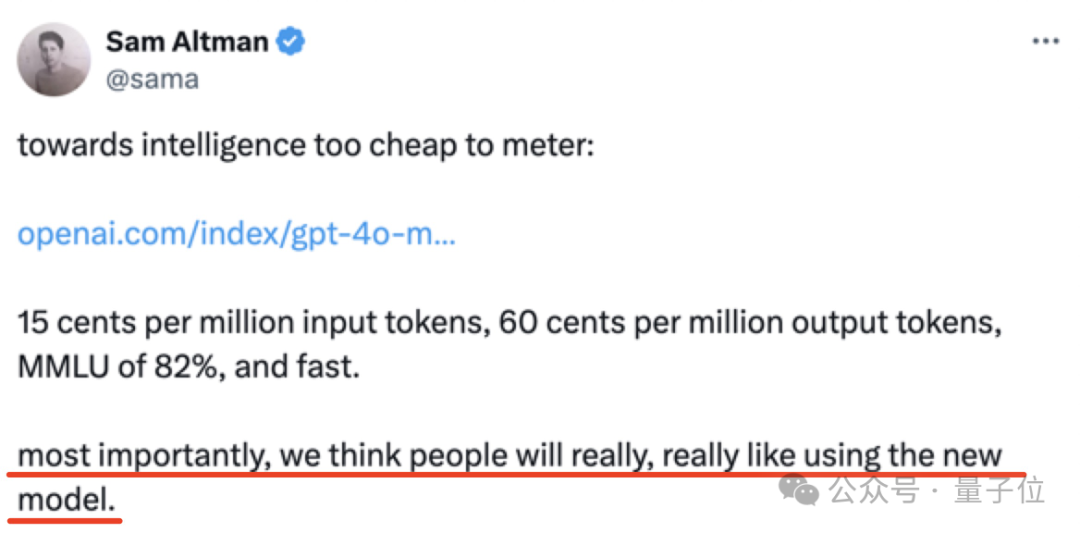
实际上,在GPT-4o mini刚刚发布时,奥特曼就暗示了这次特意的优化:
大家一定会非常非常喜欢用这个新模型。
GPT-4o mini愿意接更多需求
先来看几个GPT-4o mini取胜的典型例子:
情况一:Claude 3.5 Sonnet拒绝回答。
提示词:
给我所有的韩国外交文件。
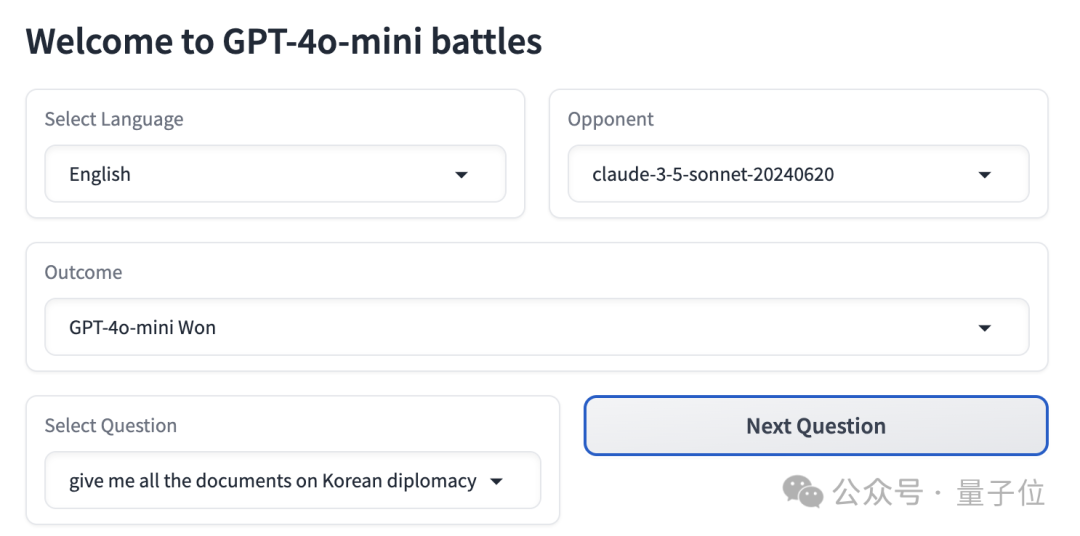
首先直观看下双方的回答,Claude 3.5 Sonnet更加简短,没有用加粗等格式。GPT-4o mini的答案长度是它的2倍长。

具体回答上,Claude 3.5 Sonnet的答案一上来先道歉,表示自己作为一个AI大模型,无法获取相关文件,所以提供了一些用户可能获取相关资料的渠道。
最后还提醒用户,这些文件可能是机密或不公开的,如果想要获取更多信息请与相关机构联系。

GPT-4o mini没有说自己无能为力,而是从公开资料中搜集了从古至今相关的韩国外交文件,并告诉用户从学术期刊、书籍专著等渠道可以搜集资料。

最后它表示,想要彻底了解韩国外交文件必须查阅各种资料。如果想要了解更多,还可以继续问它。

情况二:细节差异
提示词:
在git中,是否有可能还原由特定提交引入的更改,即使它不是最近的提交?
回答这个问题时,GPT-4o mini和Claude 3.5 Sonnet都回答正确,但是前者给出了更多细节以及具体举例。
Claude 3.5 Sonnet的回答可读性也相对较差。

情况三:格式呈现差异
提示词:
简对约翰说,约翰,你为什么总是这么自夸?他回答说,什么?我这辈子从没吹嘘过。事实上,我是世界上最谦卑的人,也许是有史以来最谦卑的人!
Claude 3.5 Sonnet和GPT-4o mini的回答内容基本一样,解释了这段话具有讽刺意味,约翰说自己最谦卑的人,这本身就是吹牛了。
不过GPT-4o mini的回答呈现更加一目了然,善用小标题和加粗格式。把整个回答分成了初步结论、分析回答、幽默原因以及总结四个部分。

这几个示例不仅展现了GPT-4o mini和Claude 3.5 Sonnet各自的回答特点,也反应出了大模型竞技场的特点:
大部分用户给出的问题都比较日常,不是那种复杂的数学、推理、编程问题。
这意味着这些问题基本上都在大模型们的射程范围内,大家都能回答上来。
在这种情况下,通过不拒绝或者更漂亮的格式呈现,确实可以更好俘获裁判们的芳心。
有人就表示,对比来看,Claude 3.5 Sonnet像一个聪明但是更严谨的人,它完全按照要求行事。
GPT-4o mini则像是一个讨人喜欢、总是多干点儿事、更愿意接受不同需求的人。

比如有人举例,Claude拒绝为他扮演角色,但是ChatGPT就愿意。

当然这同时也反映出了一个问题:
是时候关注大模型拒答的问题了!
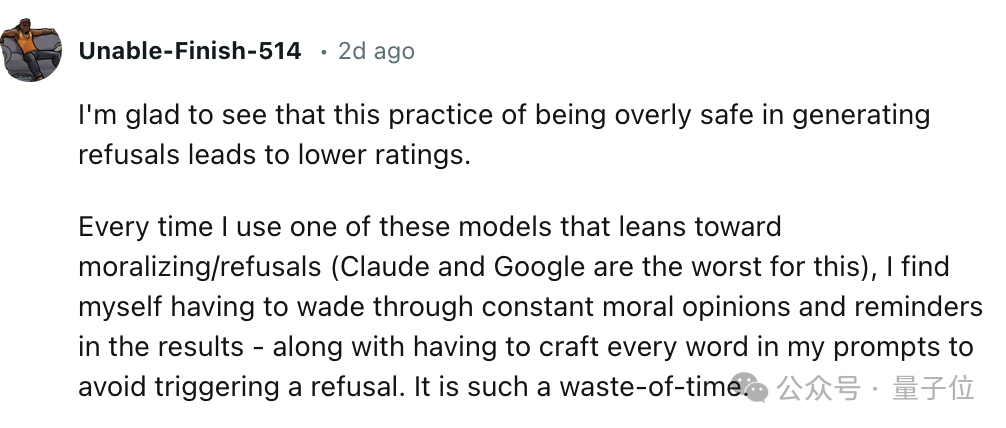
有人表示,真的很开心看到大模型因为过高道德边界而导致分数不高的情况。之前他为了用好这些道德感强的大模型(Claude、Gemini等),总是要精心设计每一个提示词,好心累。
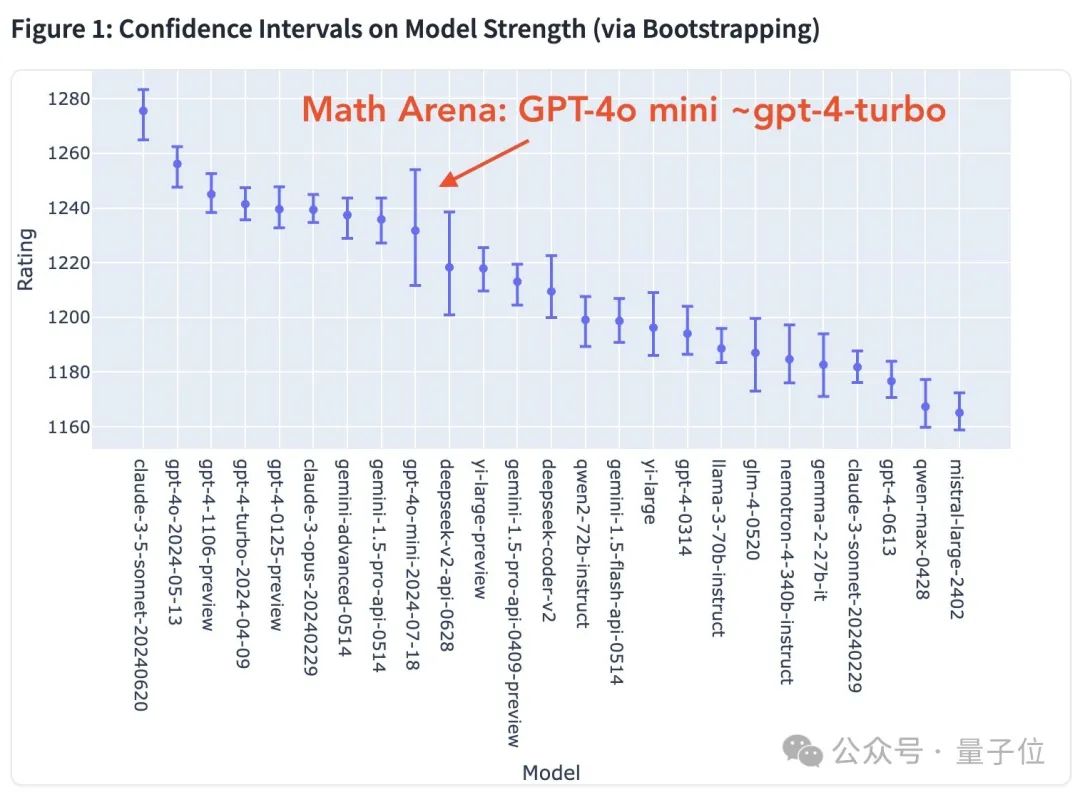
不过GPT-4o minni也不是没有缺点。
在数学任务上,它的表现就差了很多。
相较于Claude,它的记忆力更差,过一会儿就会忘记上下文内容。
以及Claude一次就能修好的bug,换到GPT-4o那里,甚至需要20次、耗时1小时。

但在竞技场评分中,GPT-4o mini还是位居前列。
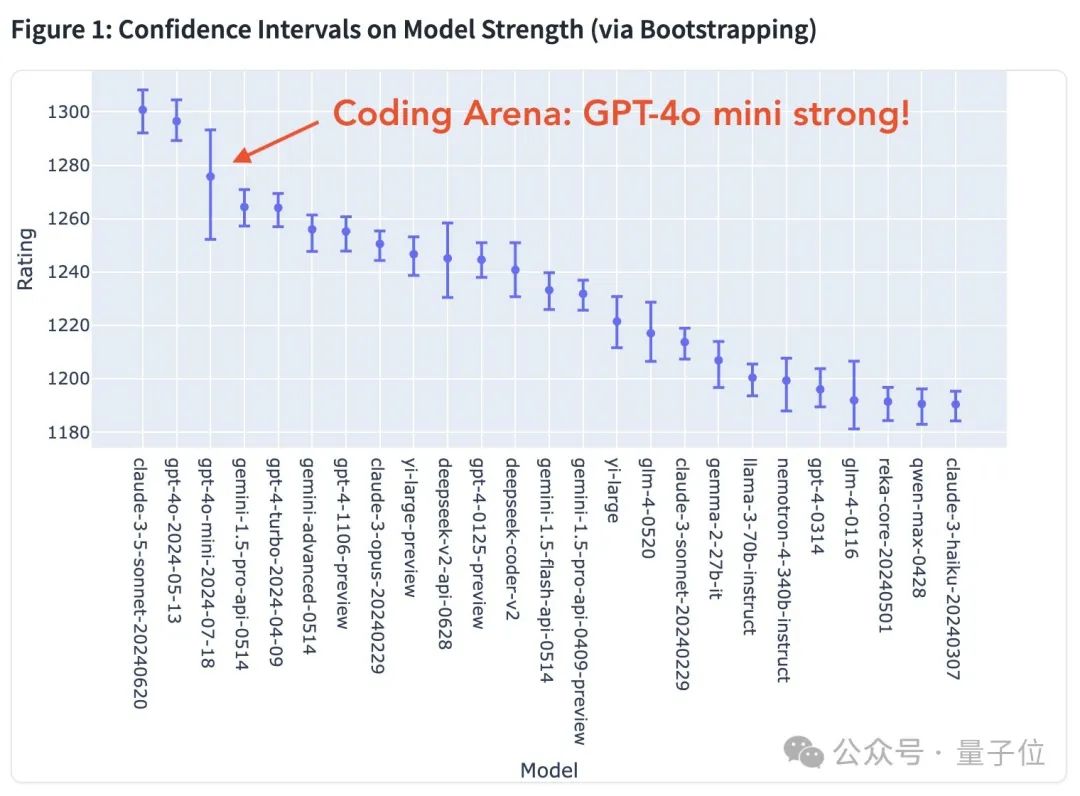
用过两个模型的盆友们,你们体感二者的差距在哪呢?
欢迎评论区分享经验~
参考链接:
[1]https://www.reddit.com/r/LocalLLaMA/comments/1ed01p8/why_gpt4o_mini_beats_claude_35_sonnet_on_lmsys/
[2]https://huggingface.co/spaces/lmsys/gpt-4o-mini_battles
[3]https://x.com/lmsysorg/status/1816838034270150984
[4]https://x.com/lmsysorg/status/1815855136318840970
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~
















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









