






金磊 发自 凹非寺
量子位 | 公众号 QbitAI
英特尔用“光”,突破了大模型时代棘手的算力难题——
推出业界首款全集成OCI(光学计算互连)芯片。

△图源:英特尔
要知道,在AI大模型遵循Scaling Law发展的当下,为了取得更好的效果,要么模型规模、要么数据规模,都在往更大的趋势发展。
这就会导致AI大模型在算力层面上,对整个计算、存储,包括中间I/O通信等提出更高的要求。
而英特尔此次的突破口,正是I/O通信:
在CPU和GPU中,用光学I/O取代电气I/O进行数据传输。
有什么用?
一言蔽之,数据传输距离远多了,量大了,功耗低了——更适合AI大模型的“体质”了。

△图源:英特尔
那么英特尔为什么要用到“光”?具体又是如何实现的?
用上了“光”,从马车变卡车
传统采用电气I/O的方式(铜线连接)固然有它的优势,例如支持高带宽密度和低功耗,但致命的问题就是传输距离比较短(不到1米)。
这要放在一个机架里倒也是没有问题,但AI大模型在算力上往往标配都是服务器集群这个量级。
不仅占地面积大,还跨N多个机架,线都是需要几十米甚至上百米的长度,功耗那是相当的高;它会吃掉所有供给机架的电源,以至于没有足够的电去做计算和存储芯片的读写操作。
除此之外,存算比方面,也正是因为大模型“大”的特点,由原来读取一次做上百次计算的比例,到现在直接变成了接近1:1。

△图源:英特尔
这就需要一种新的办法,可以在提高算力和存储密度的同时降低功耗、缩小体积,从而在一个有限的空间里,放进更多的计算和存储。
而用上了光学I/O,问题便迎刃而解了:
可在最长100米的光纤上,单向支持64个32Gbps通道。
一个形象的比喻就是,就好比从使用马车(容量和距离有限)到使用小汽车和卡车来配送货物(数量更大、距离更远)。
不仅如此,即使是在相对较近的距离去完成一些更高密度、更灵活的数据传输工作,OCI这种方式则可以类比成摩托车,速度更快且更灵活。
值得一提的是,这种OCI的方法不是停留在理论的那种。
据英特尔介绍,他们已经利用了实际验证的硅光子技术,集成了包含片上激光器的硅光子集成电路(PIC)、光放大器和电子集成电路。
并且在此前也展示了与自家CPU封装在一起的OCI芯粒,还能与下一代CPU、GPU、IPU等SOC(系统级芯片)集成。
还没完,英特尔也已经出货了超过800万个硅光子集成电路,其中超过3200万个现已投入使用的激光器。

△图源:英特尔
那么接下来的一个问题是:
英特尔的OCI是如何“炼”成的?
英特尔研究院副总裁、英特尔中国研究院院长宋继强的交流过程中,他对这个问题做了深入的剖析和解读。

△英特尔研究院副总裁、英特尔中国研究院院长,宋继强
硅光子技术集合了20世纪两项最重要的发明:硅集成电路和半导体激光。
与传统电子产品相比,它支持在较远的距离内更快的数据传输速度,同时利用英特尔高容量硅产品制造的效率。

英特尔这一次发布的硅光集成技术,OCI芯粒达到了光电共封装的层面。
这个光电共封装是把一个硅光子集成电路(PIC),和一个电子集成电路(EIC),放在一个基板上组成了一个OCI芯粒,作为一个集成性连接的部件。
这就意味着xPU,包括CPU,未来的GPU都可以和OCI芯片封装在一起。
OCI芯粒就是把数据中心CPU出来的所有的电气I/O信号转成了光,通过光纤,在两个数据中心的节点或者是系统里面去互相传输。
目前的双向数据传输速度达到了4Tbps,它在上层的传输协议兼容到PCIe 5.0,单向支持64个32Gbps通道,这在目前的数据中心当中是足够用的:
它采用8对光纤,功耗仅为每比特5皮焦耳(pJ),即10-12焦耳,这个数据比可插拔光收发器模块的功耗降了3倍(后者是每比特15皮焦耳)。
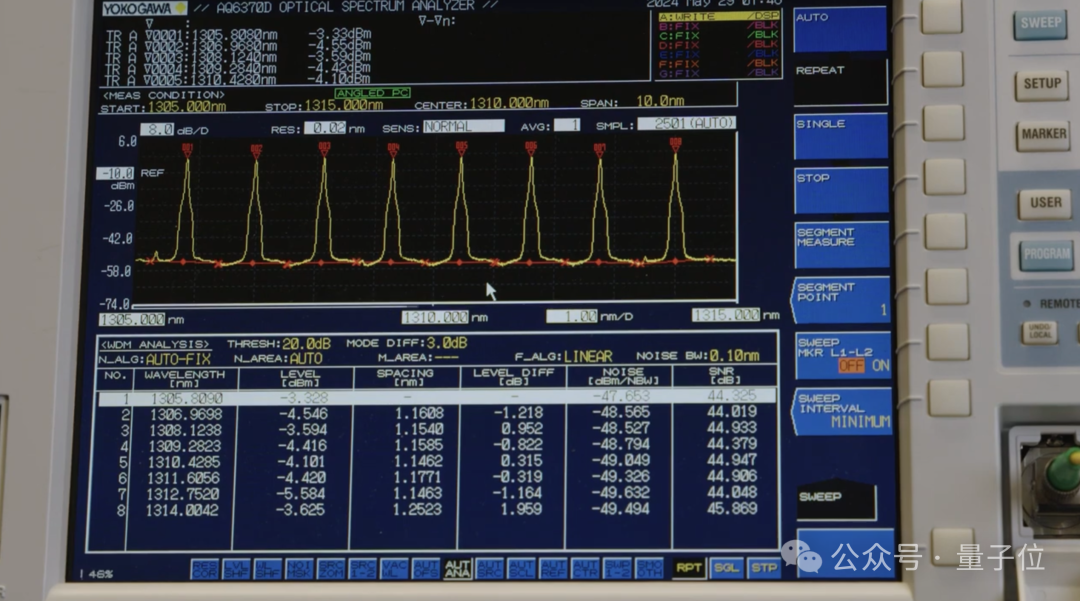
△图源:英特尔
在一个光传输的通道里,它实际上有8个不同的波段,每个波段的频率间隔是200GHz,一共占用了1.6THz光谱的间距用来传输。
光从可见光到不可见光,实际上它的频谱宽度是很宽的,从THz开始就算是接近光通讯了。

那么OCI芯粒未来会用在哪些领域呢?
对此,宋继强表示:
一个是可以用它来实现通信,还可以把它跟CPU、GPU这些计算芯片封装在一起,计算加通信非常紧密地封装在一起。
我们通过硅光集成和先进封装技术,先进封装英特尔也有非常多不同的技术,就可以实现更高密度的I/O芯粒,然后再和其它的xPU结合,未来基于芯粒,形成很多不同种类的计算加互连的芯片种类,会有非常好的应用前景。
就OCI I/O接口芯粒的性能演进路线图来看,它目前可以达到32Tbps传输速度的技术方案,主要靠迭代式的稳步提升三个方面的指标,分别是:
一根光纤里有8段稳定的波段
每一个波段的光数据传输率为32Gbps
可同时拉8对光纤且互不影响
这三个指标乘起来,就是目前单向上有2Tbps的数据传输速度,双向即是4Tbps。未来可以继续向上演进,逐步提升带宽能力。
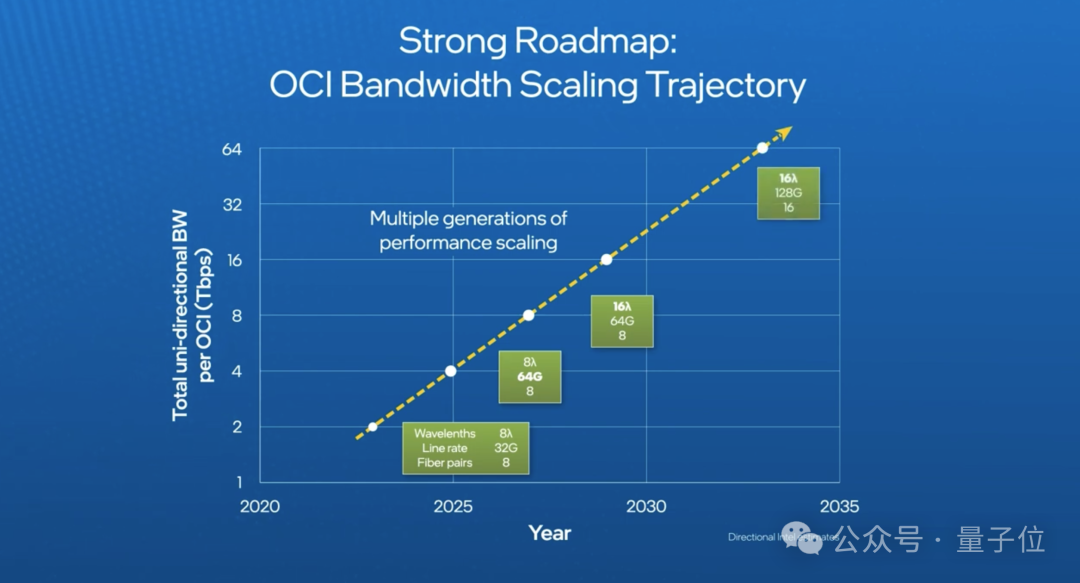
△图源:英特尔
最后,英特尔在硅光集成技术的差异化方面,宋继强也做出了解释:
主要是我们把高频率的激光发射器做在了晶圆上,又把硅的光放大器也集成上去,这是两个比较核心的技术,都是在晶圆级去制造出来的。
接下来,我们可以量产这样的高集成度激光器,因为这种在片上的激光器的好处是用普通的光纤就可以去传输了。
并且在稳定性方面,几乎是100亿小时才有可能发生一次错误。
那么你觉得英特尔pick的“光”如何呢?欢迎在评论区留言讨论。
参考链接:
[1]https://mp.weixin.qq.com/s/ozx_ficqlxjEPKa5AlBdfA
[2]https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/Intel-Shows-OCI-Optical-I-O-Chiplet-Co-packaged-with-CPU-at/post/1582541
[3]https://www.youtube.com/watch?v=Fml3yuPR2AU
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~
















 4
4

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









