






陈林 投稿自 凹非寺
量子位 | 公众号 QbitAI
国产多模态大模型,也开始卷上下文长度。
书生·浦语灵笔(InternLM-XComposer)多模态大模型升级2.5版本——
原生支持24K多模态图文上下文,超过20轮的图文交互,具备图像视频理解、网页创作、图文写作等多项功能。
该开源模型一出,一度在Hugging Face登上热榜第五。
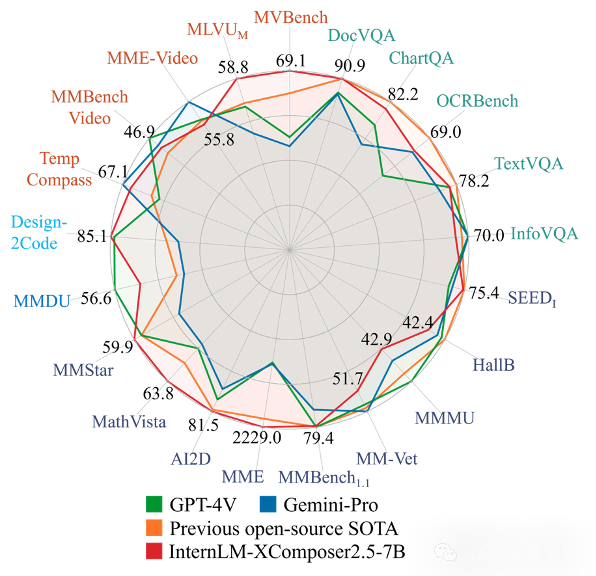
作为8B量级性能最优秀的多模态大模型之一,它在多项评测性能上对标GPT4V和Gemini Pro。
而除了支持长上下文输入,InternLM-XComposer 2.5版本(以下简称IXC 2.5)同时训练了长序列输出能力,模型支持高质量网页创作和文章生成。
兼容三种多模态理解能力
IXC 2.5同时兼顾了多模态模型的理解和内容输出能力,主要包括三种多模态理解能力。
包括超过4K分辨率的图像理解、多轮多图超长对话、精细视频内容分析。
来具体看看大模型实力如何。
高分辨率图像理解,它支持分析文档、网页、图表等信息丰富的超高清图像。
比如扔给它之前的文章,图像分辨率为1312x22619像素,并询问IXC 2.5关于截图内容的问题。
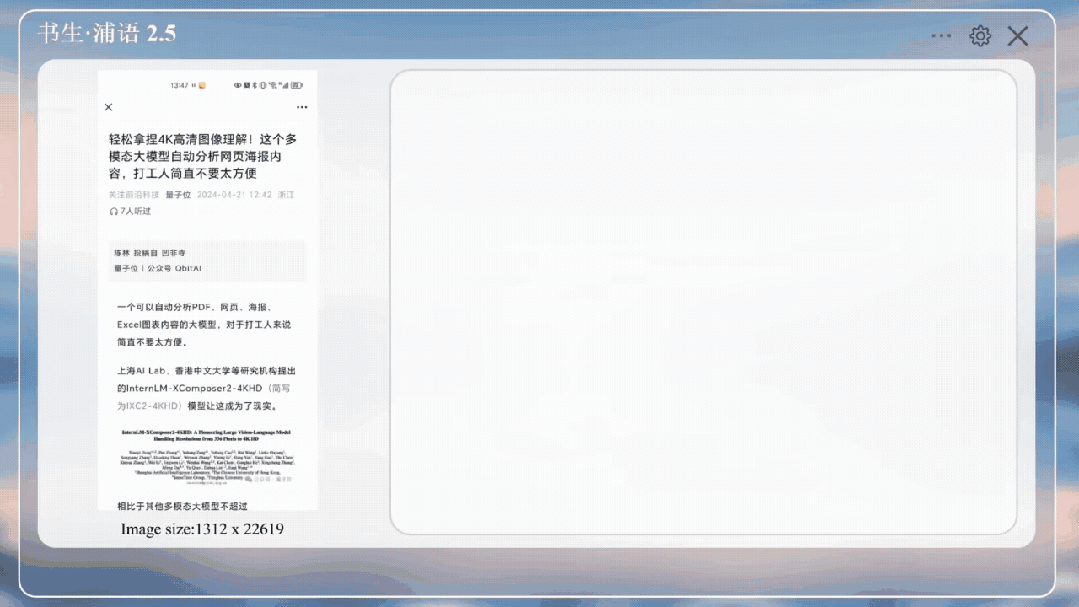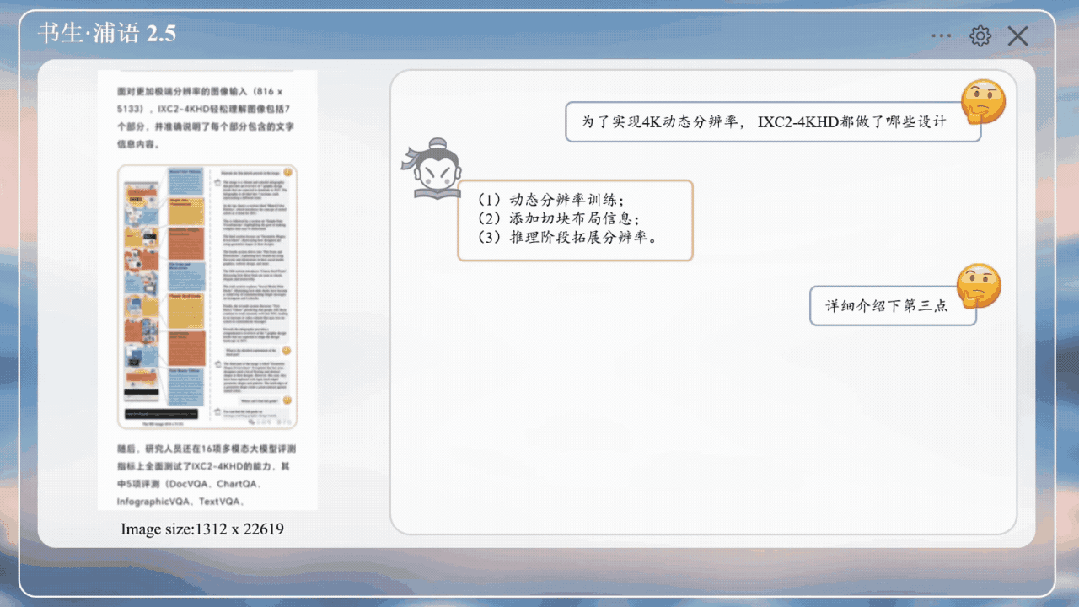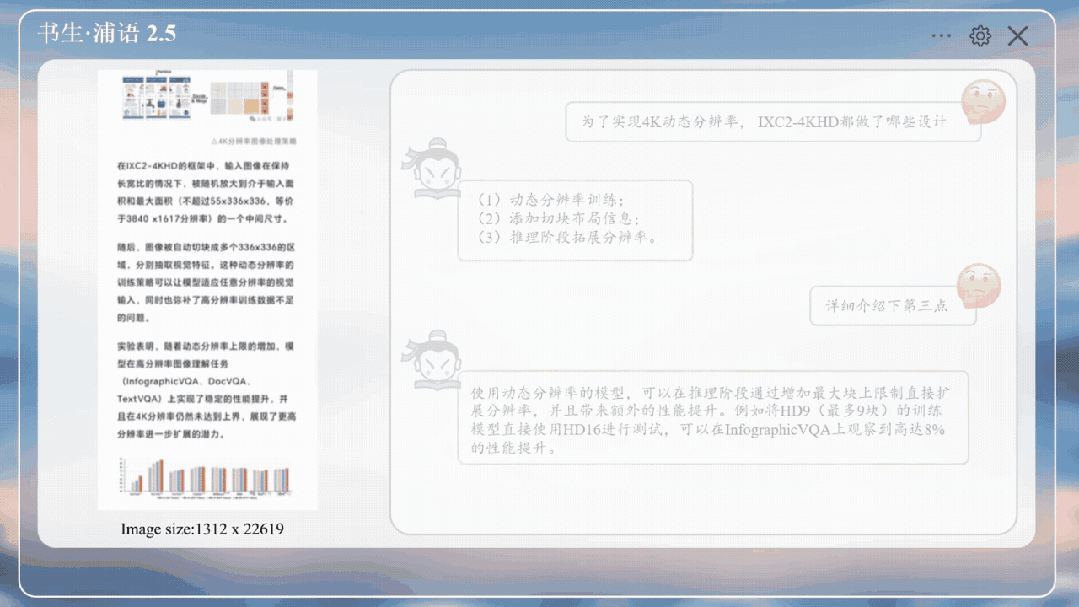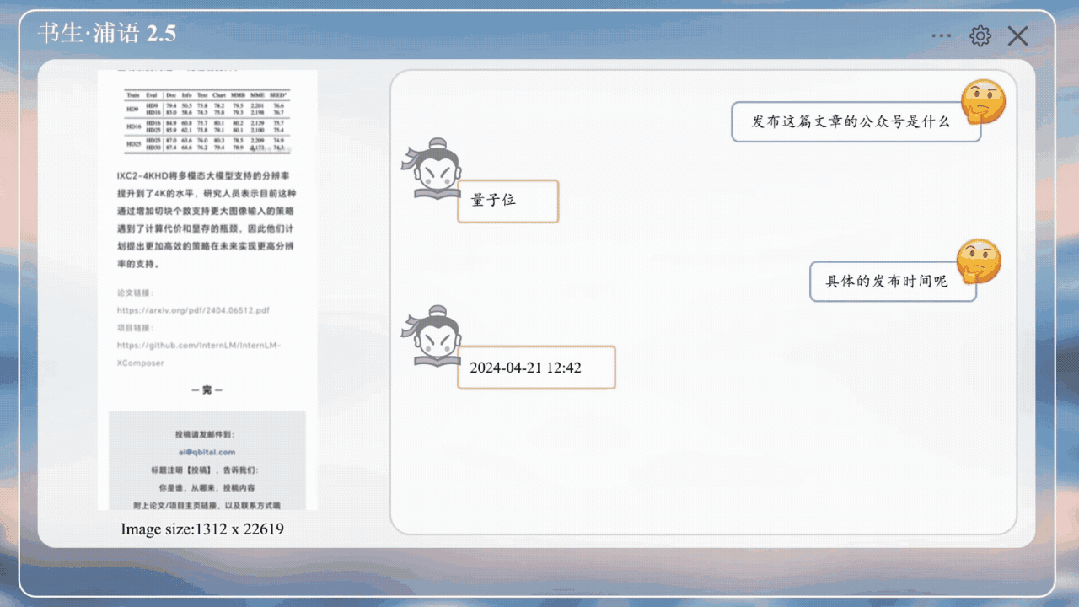
嗯,还能知道是量子位公众号。
就是询问一些图中的论文细节,它也能正确回答。
多轮多图超长对话,支持自由形式的多轮多图对话,进行超过20轮图文交互,提供自然的多模态交互体验。
为了实现这一能力,研究团队构造了第一个多模态长上下文指令数据集MMDU。该数据集包括了平均15轮图文对话,最大20张图像,最多对话轮次可以到27次,数据集现已开源。

精细视频内容分析,在多项视频大模型评测中表现出色。
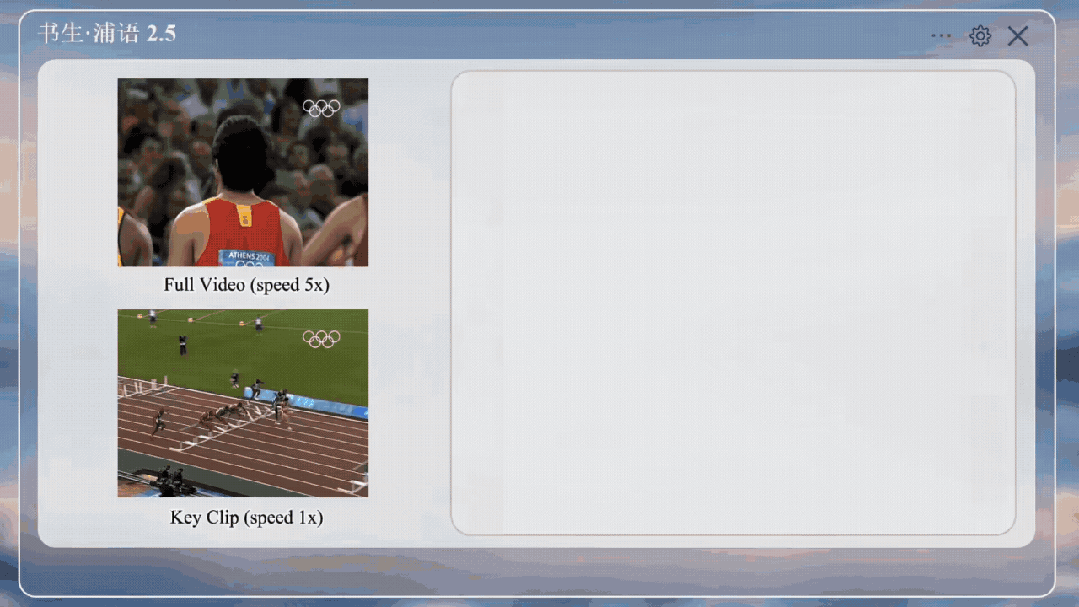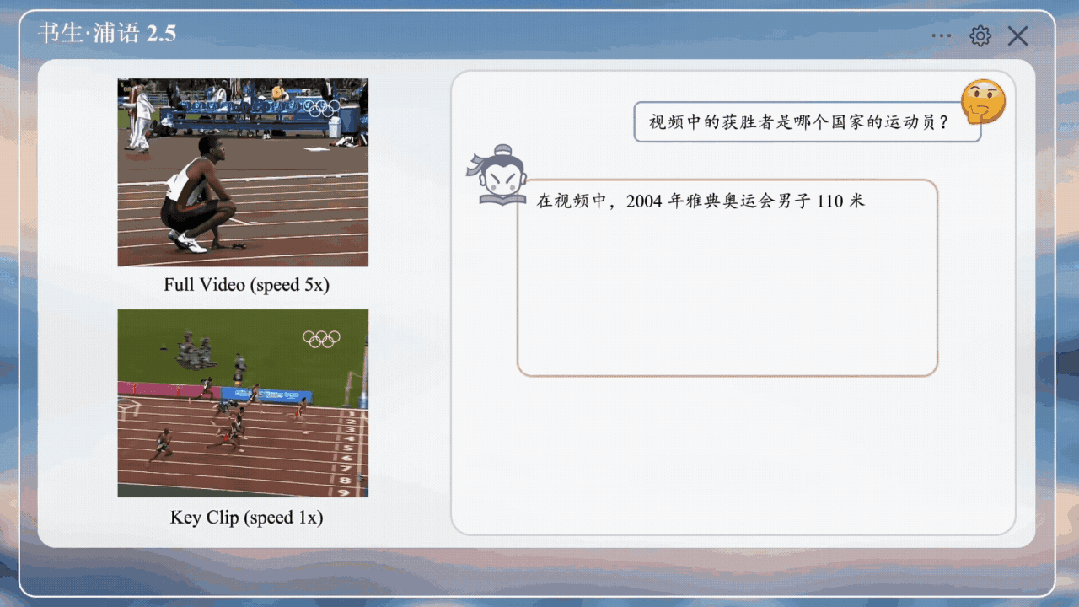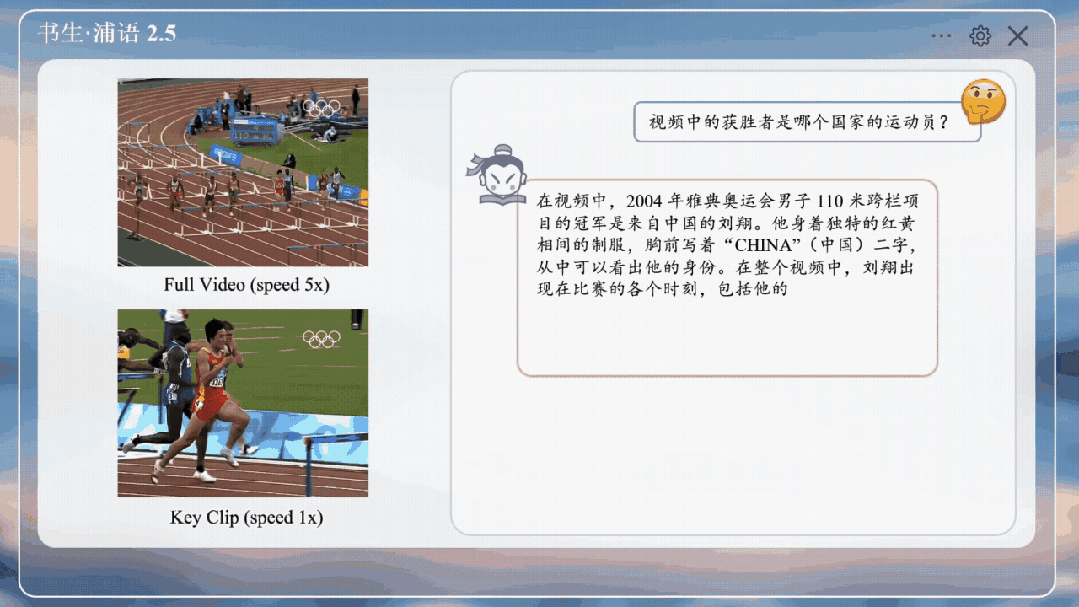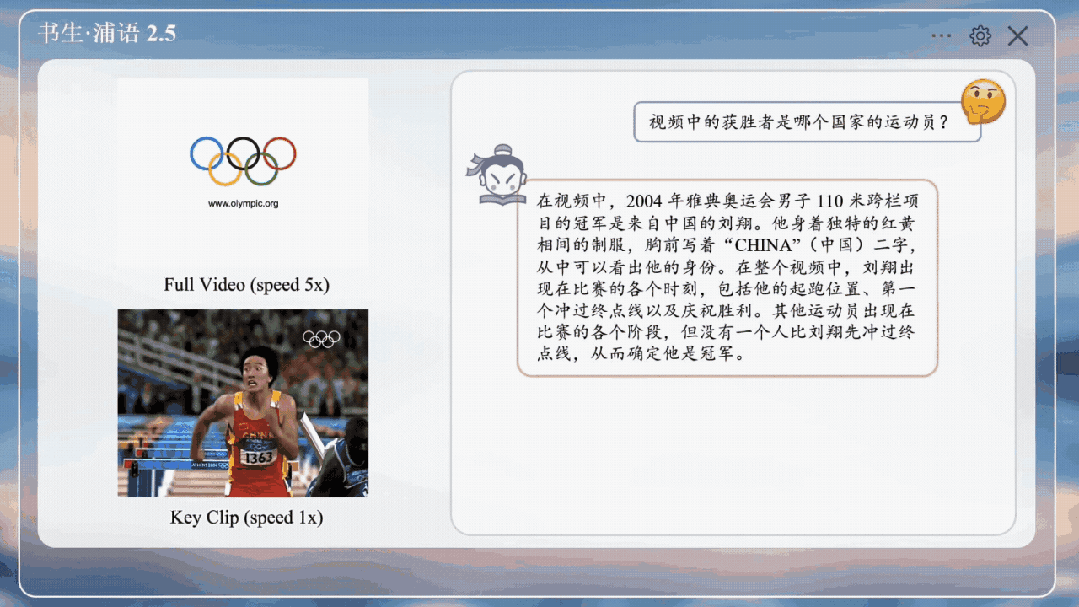
研究团队构造了ShareGPT4Video图像描述数据集,包括了3000个小时的精细视频描述标注。视频数据来源多样,包括Panda,EGO-4D,Pexels,Pixabay等,涵盖丰富的场景,数据集已经开源。

除此之外,内容输出的能力也得到了升级。
网页创作。IXC 2.5扩展了网页代码的编写能力,可以根据图文指令输入,编写对应的网页前端和交互代码(HTML,CSS,JavaScript)。
在该能力的支持下,IXC 2.5实现了三个实用的功能,包括:
(1)网页截图转代码:输入网页截图,输出对应截图的前端代码
(2)语言指令做网页:输入网页制作要求,创作网页代码并渲染
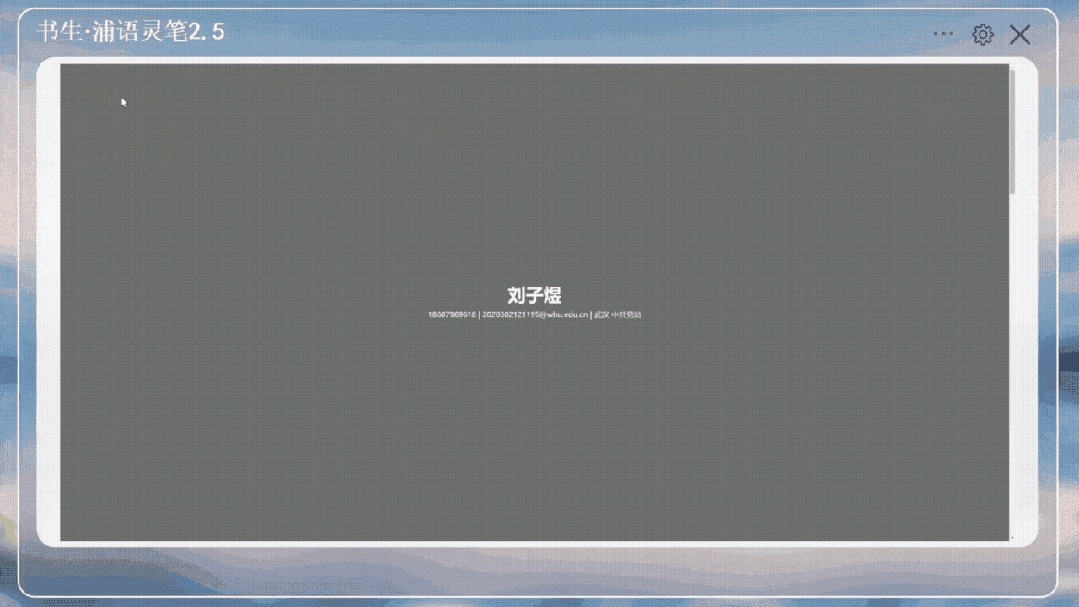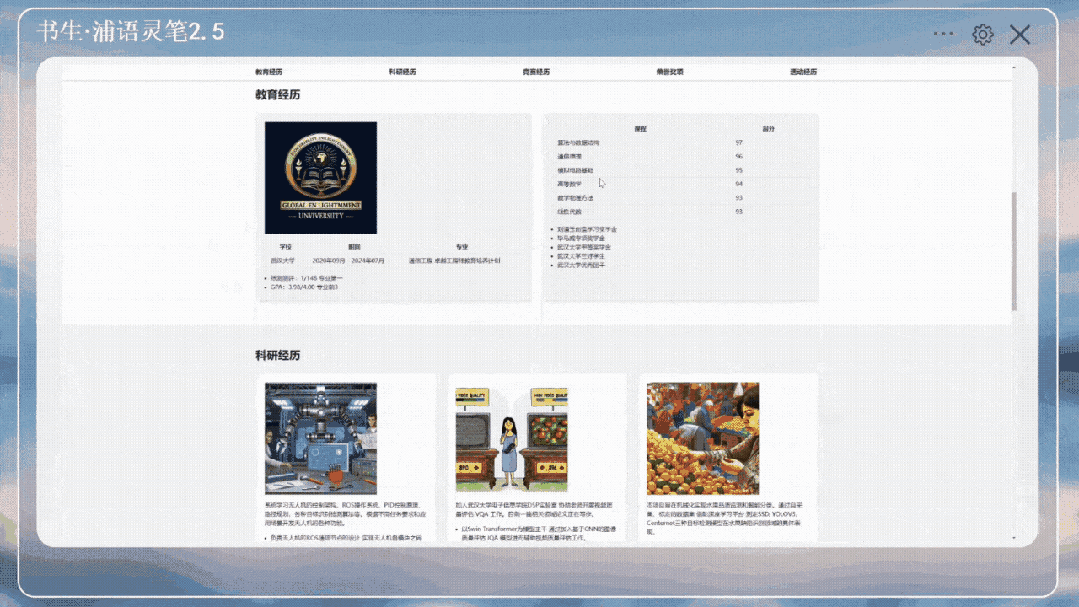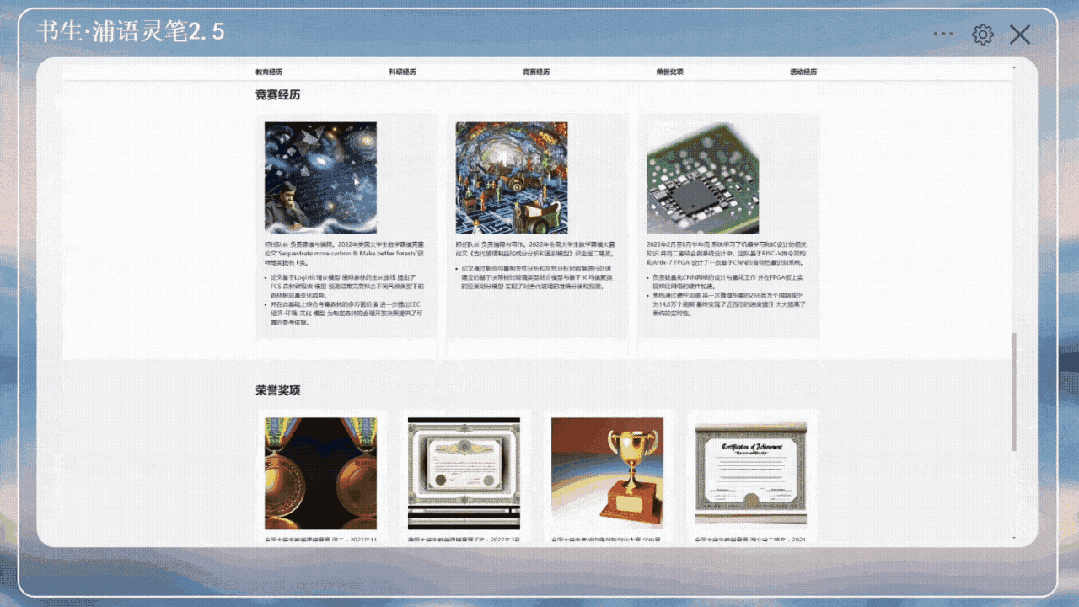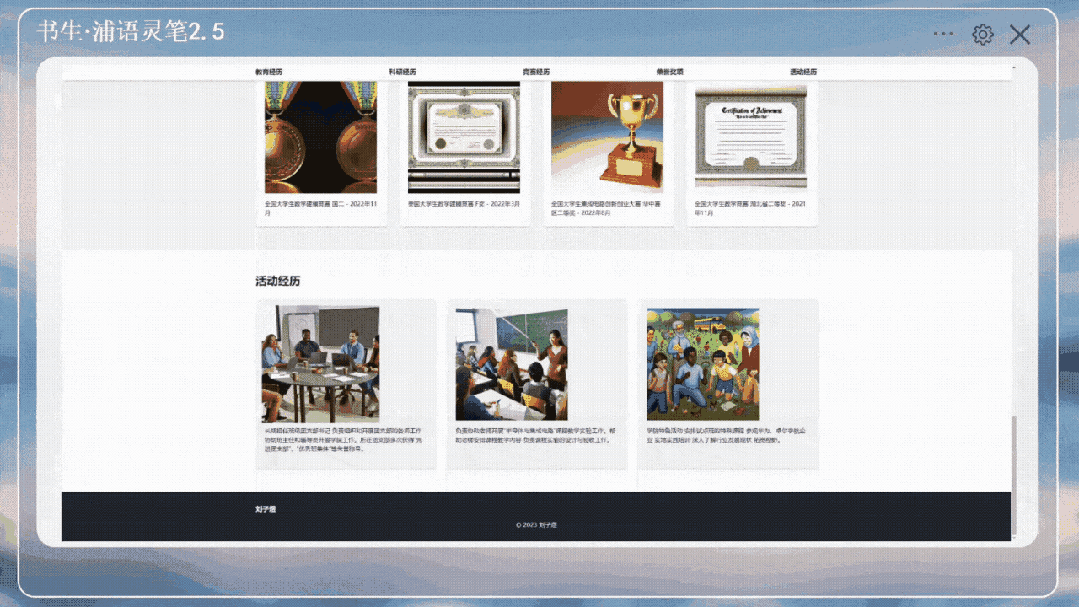
(3)个人简历做网页:输入个人简历PDF,制作对应个人简历的主页
图文写作。本次IXC 2.5构造了2000篇涵盖各种文体,包括:高考作文、散文、小说等不同文风文章的文笔质量打分数据,并使用这些数据训练的一个reward model。
使用该reward model进一步构造了30000篇文章质量偏好数据,用于直接偏好学习(DPO)训练,大幅提升了文章创作的文笔和稳定性。IXC 2.5不仅支持高质量写作,还可以给出文章写作评价。
以2024高考新课标Ⅱ卷为例,IXC 2.5不仅可以写出文笔优秀的高考作文,对于作文的点评也显得非常专业。

图像与视频理解的统一架构
今年4月,IXC团队提出了4K分辨率图像多模态大模型方案IXC2-4KHD,可以处理任意长宽比的高分辨率图像。
IXC 2.5基于4KHD框架进行扩展,实现了一套可以统一处理高分辨率图像和视频的多模态模型架构。
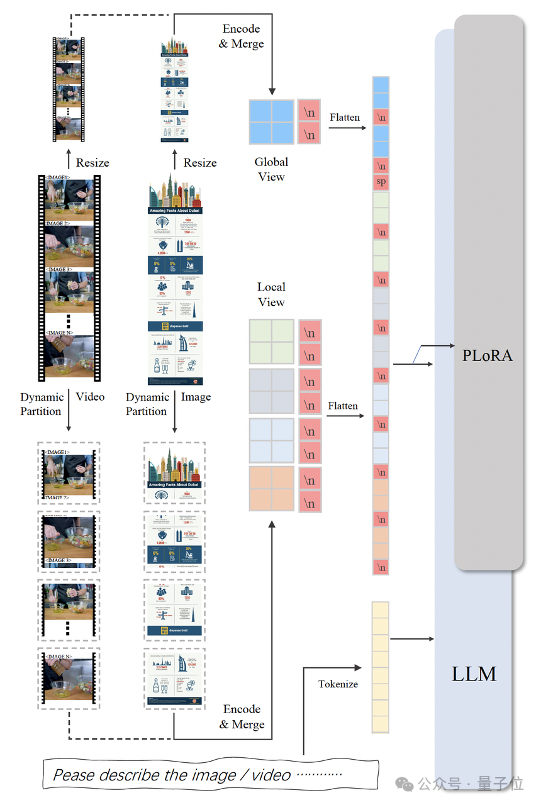
视频帧拼图。
对于视频数据,IXC 2.5会均匀采样视频帧,并将视频帧拼成一个超长的高分辨率图片。每一帧图像上用文字标记视频的时序信息。
全局特征(Global View)。
将整张高分辨率图像整体resize到560x560大小,用ViT抽取全局特征。
局部特征(Local View)。
将高分辨率图像切块,每块560x560分辨率,分别抽取局部特征
特征拼接:将Global View和Local View的特征拼成一个序列,用’\n’ token标记图像长宽比布局,用’sp’ token分隔全局特征和局部特征。
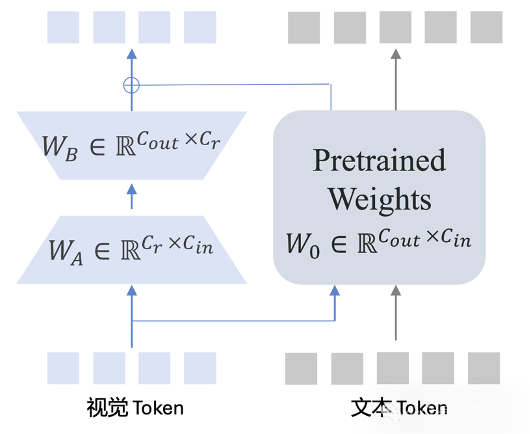
为了兼顾模型对于视觉内容的理解和语言创作能力,IXC2.5采用了一种 PLoRA(局部LoRA)的模型架构,即对于视觉Token单独增加一组LoRA参数进行编码,通过这种方式让新增的LoRA参数只影响视觉Token,一方面可以帮助模型更好的理解视觉信息,同时减少对模型语言能力的影响。
IXC社区提供完善的量化、部署、微调代码支持,提供在线demo和在线demo的本地运行代码,包括:
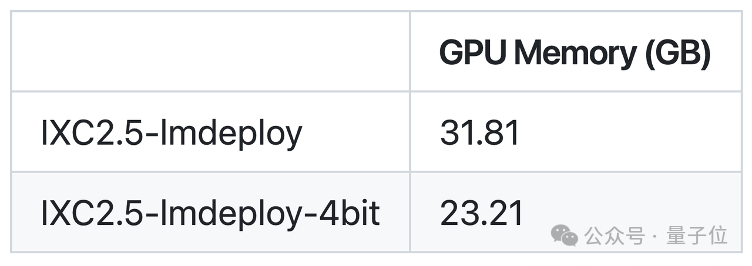
量化和部署(LMDepoly支持):IXC 2.5由LMDeploy项目支持模型部署和量化,只需要不到24GB显存就可以运行,同时支持多卡推理降低单卡显存要求。
微调(原生支持&Modelscope Swift):IXC 2.5支持使用研究团队开源的微调代码,以及Modelscope Swift项目支持的微调代码两种实现,使用LoRA微调最少只需要32GB显存。
Demo代码:IXC 2.5的demo代码使用Whisper和MeloTTS支持了语音输入输出,支持本地部署,代码现已开源。
项目地址:
https://github.com/InternLM/InternLM-XComposer
论文地址:
https://arxiv.org/pdf/2407.03320


















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









