






北京航空航天大学 李红羽 投稿 凹非寺
量子位 | 公众号 QbitAI
免训练多模态分割领域有了新突破!
中科院信工所、北航、合工大、美团等单位联合提出了一种名为AL-Ref-SAM 2的方法。
这种方法利用GPT-4和SAM-2来统一多模态分割,让系统在免训练的情况下,也能拥有不亚于全监督微调的性能!

≥ 全监督方法
多模态分割主要有两种方法:一种是依据文字描述找到视频中特定对象的分割方法(RVOS),另一种是通过声音识别视频中发声对象的方法(AVS)。
免训练的多模态视频指代分割虽然在数据和训练成本上有较大优势,却由于缺乏在特定任务数据上针对性的模型参数调整,导致性能与全监督方法有较大差距。
而研究团队要解决的就是这个问题。
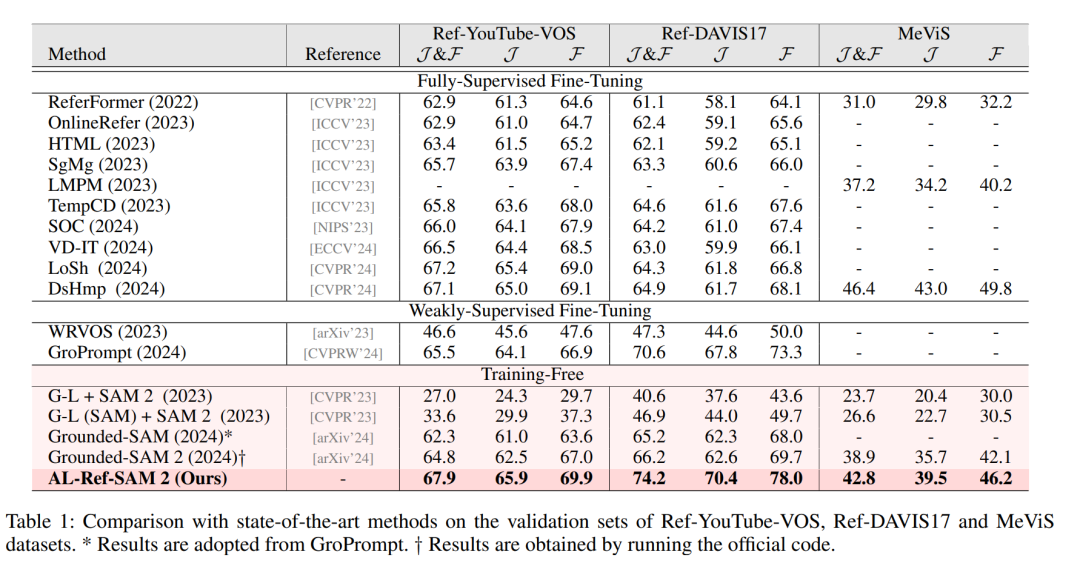
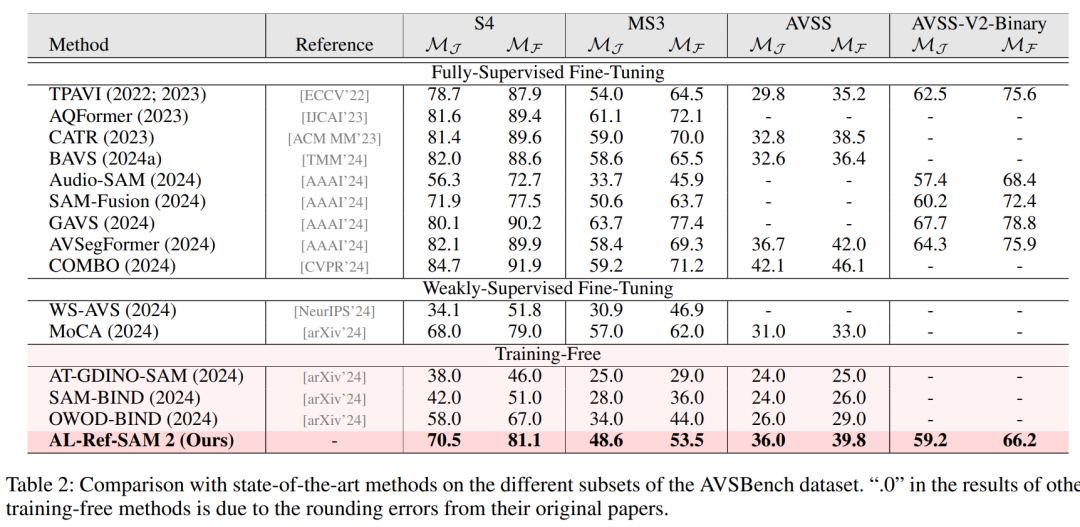
实验中,他们对多个RVOS基准数据集进行了广泛验证,包括Ref-YouTube-VOS、Ref-DAVIS17和MeViS,同时在AVSBench的多个子集上也进行了测试。
最后的实验结果显示,AL-Ref-SAL 2在这些数据集上的表现不仅优于其他无需训练和弱监督的方法,并且甚至在一定情况下,系统的性能可以与全监督方法相媲美。
特别是在Ref-YouTube-VOS和Ref-DAVIS17这两个数据集上,AL-Ref-SAM 2的表现甚至超过了大多数全监督方法。
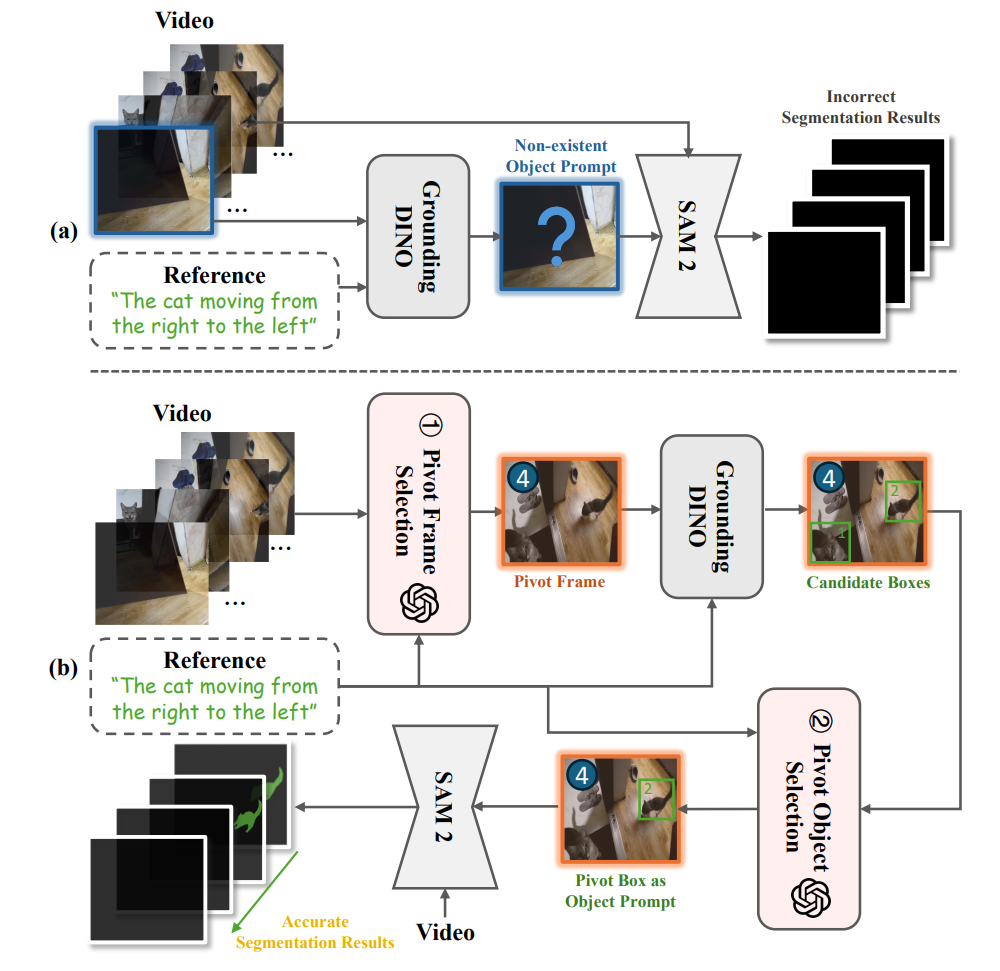
△ 免训练设置下三阶段分割基线方法(a)与本文方法(b)的比较
具体咋实现的?
研究团队把AL-Ref-SAM 2的算法分成了三个阶段:
第一阶段:获取形式统一的指代信息,对于RVOS任务,指代信息是输入的文本描述本身,而对于AVS任务,研究人员们利用LBRU模块将音频转化为对发声对象的语言形式描述。
第二阶段:根据语言指代和视频内容,利用GPT-4进行两阶段时空推理,从视频中逐步选出关键帧和关键框。
第三阶段:以关键帧为分割起点,关键框为初始提示,利用SAM 2获得目标对象在整段视频中的分割掩码序列。
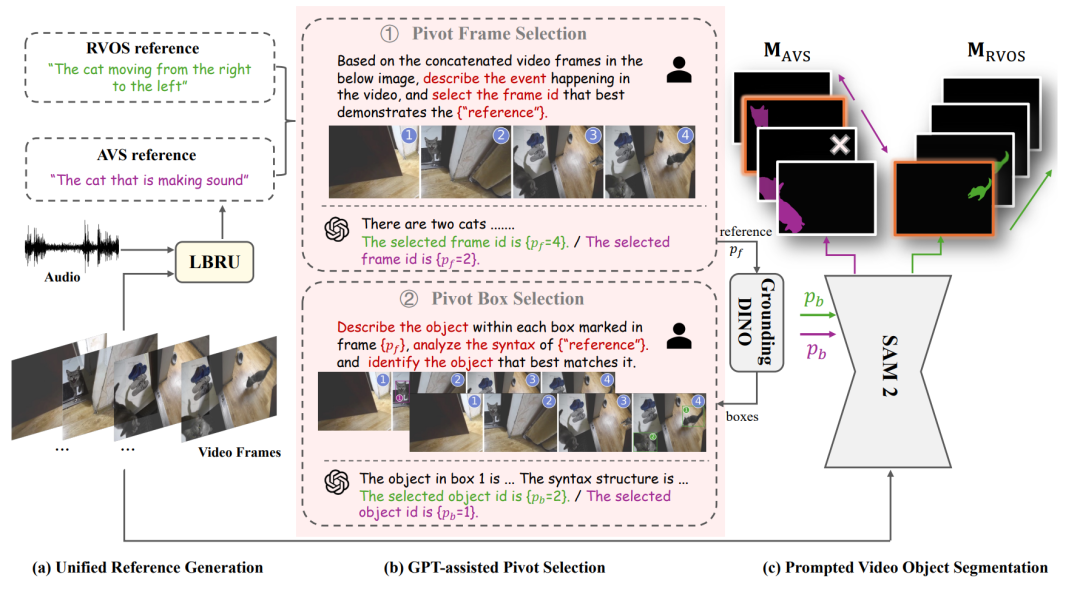
△ AL-Ref-SAM 2的整体流程
具体实验细节,请看下文展开~
语言绑定的音频指代转换(LBRU)
LBRU将音频信号转换为与语言描述统一的格式(例如“[CLS] that is making sound”,其中[CLS]代表了具体的发声对象类别),以减少音频信息中的语义模糊性和冗余性。
为了获取发声对象的准确类别,LBRU利用了一个预训练音频分类器,如BEATs,对音频进行分类,并保留置信度前k高的类别文本。
由于这些类别中可能包含了重复类别或背景声类别,LBRU进一步引入了视频作为视觉上下文,利用GPT-4根据视频内容对音频类别进行过滤、合并,并将保留的音频类别转化为发出该声音的对象类别。
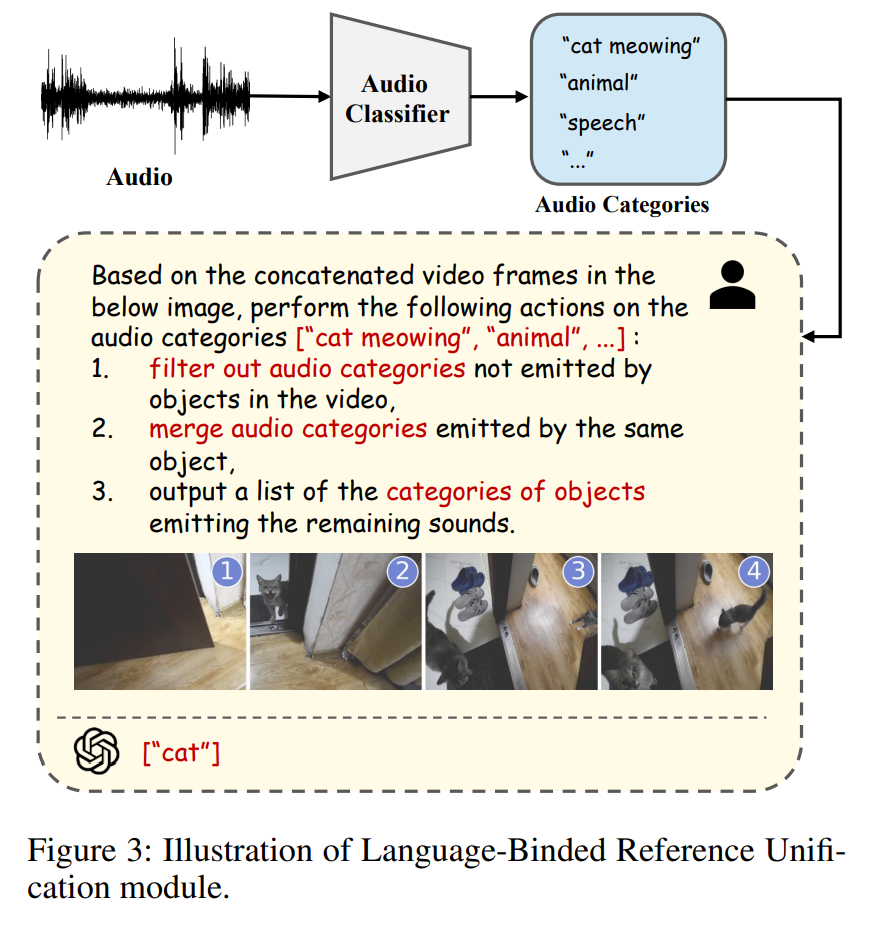
△ 语言绑定的音频指代转换模块
GPT辅助的关键帧/框选择(GPT-PS)
GPT-PS利用GPT-4分别进行时序推理选出关键帧,以及空间推理选出关键框。
在时序推理阶段,为了使GPT可以处理视频格式的内容,研究团队首先对视频帧进行采样,将采样后的若干帧拼接为一张图并在图上标出帧号。
为了显式引导GPT在理解视频内容的基础上选择关键帧,他们还针对性地设计了关键帧思维链提示模板,要求GPT首先描述整段视频的场景,再根据语言指代选出关键帧。
之后,研究人员将语言指代信息和关键帧输入GroundingDINO模型中,获得多个可能的候选框。
在空间推理阶段,首先将候选框画在关键帧上,并且依旧将其与其他采样帧顺序拼接作为视觉信号输入GPT。
类似地,他们也设计了关键框思维链提示模板,要求GPT描述每个候选框中对象的特征和不同对象之间的关系,并对指代信息进行语法分析确定真正的指代主体,最后再根据语言指代选出包含目标对象的候选框作为关键框。

以下是研究团队得出的相关数据:
论文链接:https://arxiv.org/pdf/2408.15876
代码链接:https://github.com/appletea233/AL-Ref-SAM2
— 完 —
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点这里👇关注我,记得标星哦~


















 17
17

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









