






王豪 投稿自 凹非寺
量子位 | 公众号 QbitAI
开放域检测领域,迎来新进展——
中山大学联合美团提出新模型OV-DINO,实现开放域检测开源新SOTA!
比Grounding DINO高12.7% AP,比YOLO-World 高4.7% AP。
目标检测技术一直是研究的热点。但传统的目标检测方法往往受限于预定义的类别集合,难以应对现实世界中种类繁多的物体。
为了突破这一限制,开放词汇检测(Open-Vocabulary Detection, OVD)应运而生。换言之,它能在模型在没有预先定义类别的情况下,通过文本描述来识别和检测物体。
OV-DINO是基于语言感知选择性融合、统一的开放域检测方法。作为最强开放域检测开源模型,目前项目已公开论文和代码,在线Demo也可体验。
什么是OV-DINO?
本文提出了一种名为OV-DINO的开放域检测方法。
整体框架包括一个文本编码器、一个图像编码器和一个检测头。模型接收图像和提示文本作为输入,通过特定模板创建统一的文本嵌入表示。
图像和文本嵌入经过编码器处理后,图像嵌入通过Transformer编码器生成精细化的图像嵌入。
语言感知查询选择模块选择与文本嵌入相关的对象嵌入,并在解码器中与可学习的内容查询融合,最终输出分类分数和回归边界框。
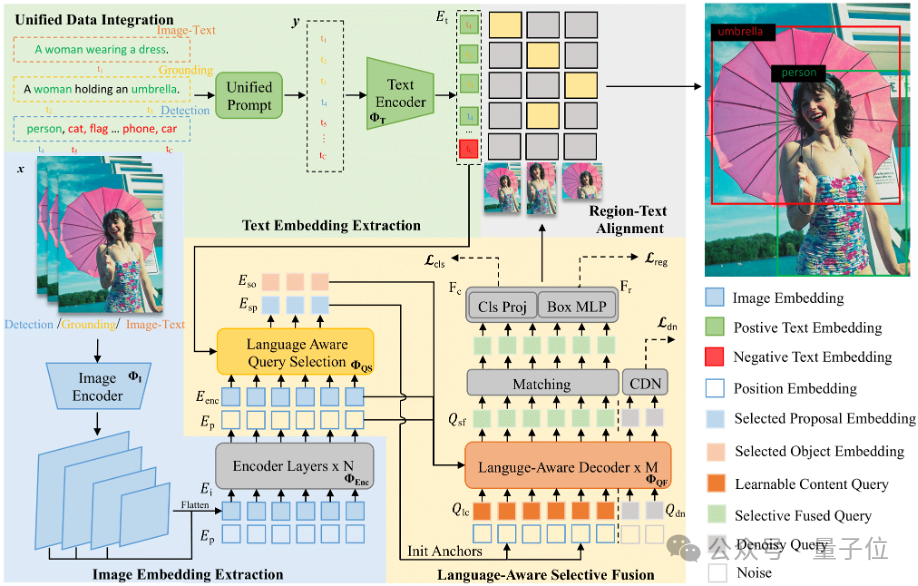
统一数据集成(UniDI)
在预训练阶段,OV-DINO将检测数据、定位数据和图像-文本数据转换为统一的检测数据格式,从而简化模型优化过程并提高性能。检测数据和定位数据的集成相对简单,而图像-文本数据的转换则通过将图像描述视为图像的唯一类别来实现。所有文本输入都通过简单模板进行统一处理,确保一致的文本嵌入表示。
语言感知选择性融合(LASF)
该模块包括语言感知查询选择和语言感知查询融合两个关键组件。查询选择组件通过评估图像嵌入和文本嵌入的相似性来选择对象嵌入。查询融合组件逐步融合语言感知对象嵌入,同时保留内容查询的原始语义。语言感知查询选择通过计算图像嵌入和文本嵌入的相似性矩阵,并选择最相关的嵌入。查询融合则在解码器层中动态更新内容查询,逐步引入语言感知上下文。
预训练
OV-DINO采用检测中心的数据格式,将不同类型的数据(检测数据、定位数据和图像-文本数据)转化为适合检测的格式,允许在统一的框架内进行预训练。模型的前向传播过程包括图像编码器提取图像嵌入、文本编码器提取文本嵌入、Transformer编码器生成精细化图像嵌入、语言感知查询选择模块选择对象嵌入,以及Transformer解码器通过选择性融合模块进行查询分类和边界框回归。模型通过统一的分类损失函数和目标框损失函数进行优化。
通过上述设计,OV-DINO实现了开放域检测的高效预训练和性能提升。
实验结果
OV-DINO使用Swin Transformer作为图像编码器和BERT-base作为文本编码器的模型架构,通过统一数据集成(UniDI)流程整合了多样化的数据源,如Objects365、GoldG grounding和Conceptual Captions图像-文本数据集,进行端到端的预训练。在此基础上,引入了语言感知选择性融合(LASF)模块来优化跨模态的语义对齐。在预训练阶段,批量大小为128,训练周期为24个epoch,使用了AdamW优化器,学习率调度采用多步衰减策略。在COCO数据集进行了额外的微调,批量大小为32,设置了更小的学习率。在COCO和LVIS基准数据集上进行评估,采用平均精度(AP)和固定平均精度(Fixed AP)作为主要指标。
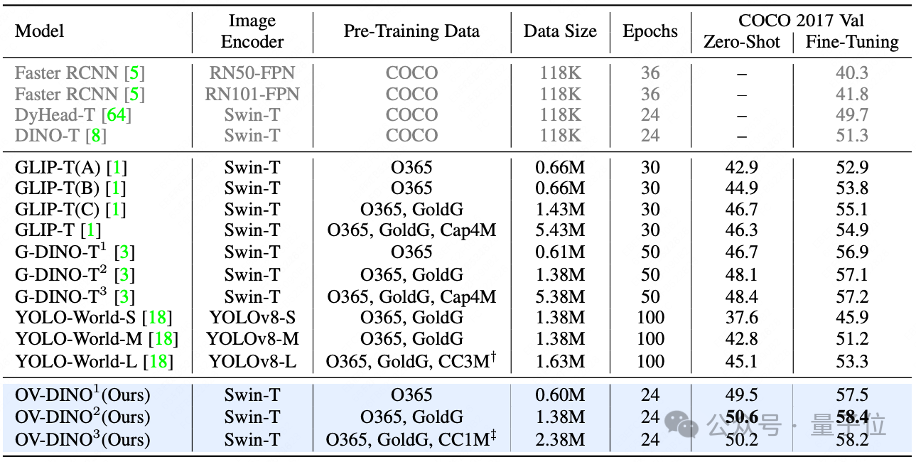
COCO Benchmark
在零样本评估设置中,OV-DINO在COCO 2017验证集上取得了50.6%的平均精度(AP),这在同类方法中表现突出。该结果显著优于先前的方法,GLIP和G-DINO,显示了OV-DINO在处理未见类别时的强大泛化能力。在COCO数据集上进行微调后,OV-DINO进一步提升了性能,达到了58.4%的AP,刷新了该领域的记录。这一结果证明了OV-DINO不仅在零样本情况下表现出色,通过进一步的微调也能在封闭词汇集上实现卓越的检测性能。
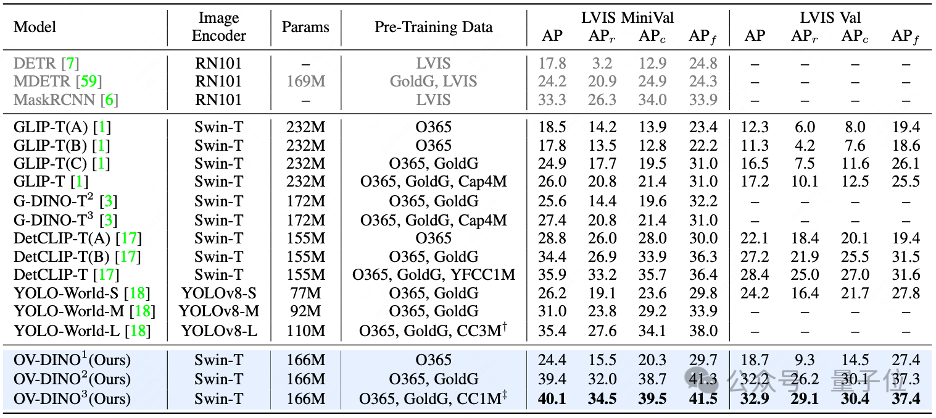
LVIS Benchmark
在零样本评估设置中,OV-DINO在LVIS MiniVal数据集上取得了40.1%的AP,显著优于其他现有方法,如GLIP和G-DINO。在LVIS Val数据集上,OV-DINO也展现了强大的性能,取得了32.9%的AP。OV-DINO在处理LVIS数据集中的长尾类别时表现出色,能够检测到稀有(rare)、常见(common)和频繁(frequent)类别的物体。在LVIS MiniVal数据集上,OV-DINO在稀有类别上取得了34.5%的AP,在常见类别上取得了39.5%的AP,在频繁类别上取得了41.5%的AP。
可视化结果
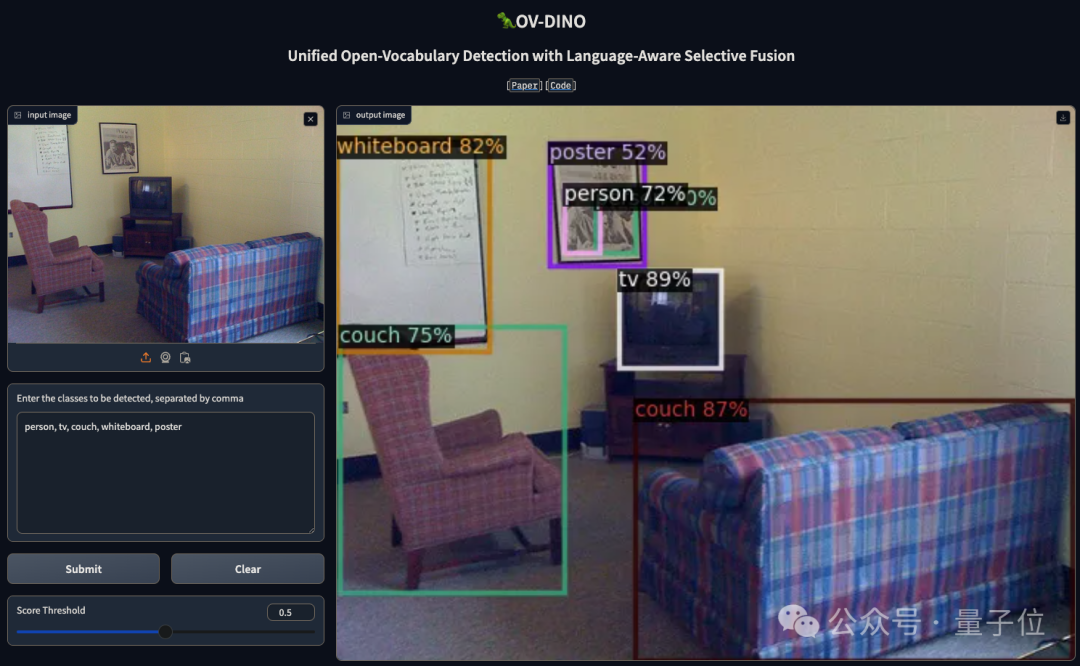
可视化结果显示,OV-DINO能够准确地检测出图像中定义的所有对象,并且置信度分数较高。与GLIP和G-DINO等其他方法相比,OV-DINO的预测更加精确,并且能够检测到标签中未标记的额外对象。

LVIS数据集包含超过1000个类别,OV-DINO在零样本推断中展现了其检测多样化实例的能力。可视化结果突出了OV-DINO在长尾类别上的性能,显示出在图像中检测到丰富多样的物体类别,并且预测结果具有高准确性。

通过在COCO和LVIS数据集上的可视化结果,OV-DINO证明了其强大的零样本泛化能力,即使是在面对训练期间未遇到的类别时也能进行有效的检测。
最后小小总结一下,OV-DINO是一个统一的开放域检测方法,通过语言感知的选择性融合和统一数据集成(UniDI)显著提高了检测性能。在COCO和LVIS基准测试中,OV-DINO实现了超越现有最先进方法的性能,在零样本和微调评估中均展现出卓越的结果。通过引入语言感知的跨模态融合和对齐,OV-DINO为开放域检测(OVD)提供了一种新颖的视角,与传统的区域-概念对齐方法不同。尽管OV-DINO在性能上取得了显著成果,但仍存在一些挑战和局限性,如模型扩展性、计算资源需求等。
论文地址:
https://arxiv.org/abs/2407.07844
代码地址:
https://github.com/wanghao9610/OV-DINO
Demo:
http://47.115.200.157:7860/


















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









