






梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
跨GPU的注意力并行,最高提速8倍,支持512万序列长度推理。
环注意力(Ring Attention)后继者——树注意力(Tree Attention)来了。
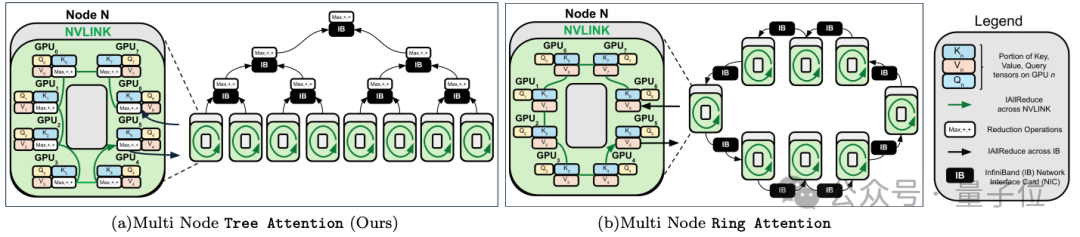
最关键之处在于,通信步数随设备数量成对数增长,而不是线性增长。
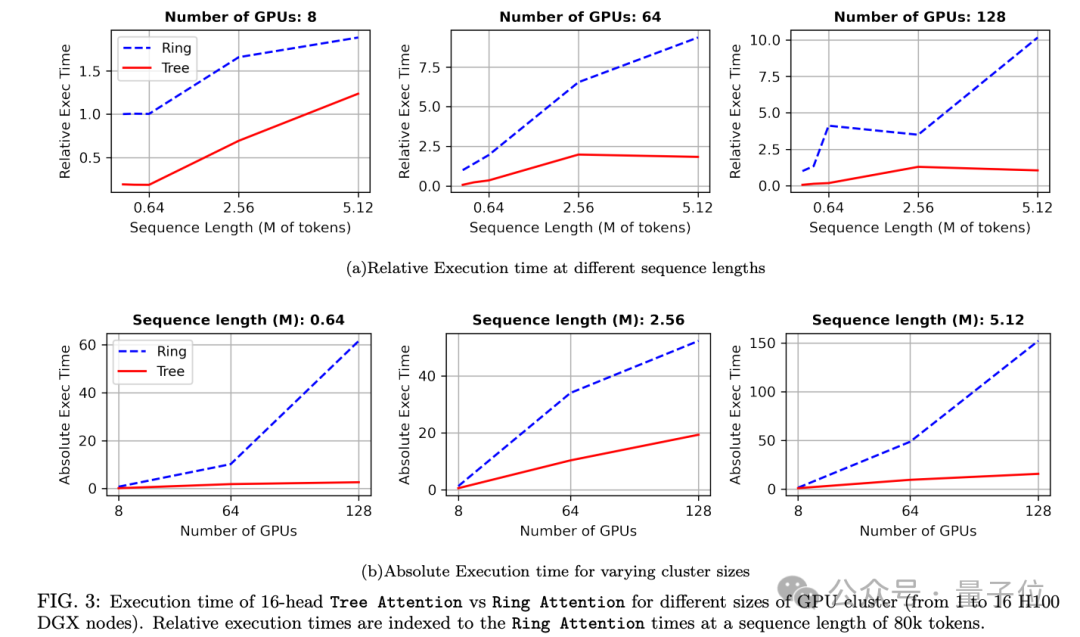
换句话说,树注意力的优势随着设备数量增大会更加明显。实验中,在128卡、512万序列长度设置时达到最高8倍加速。
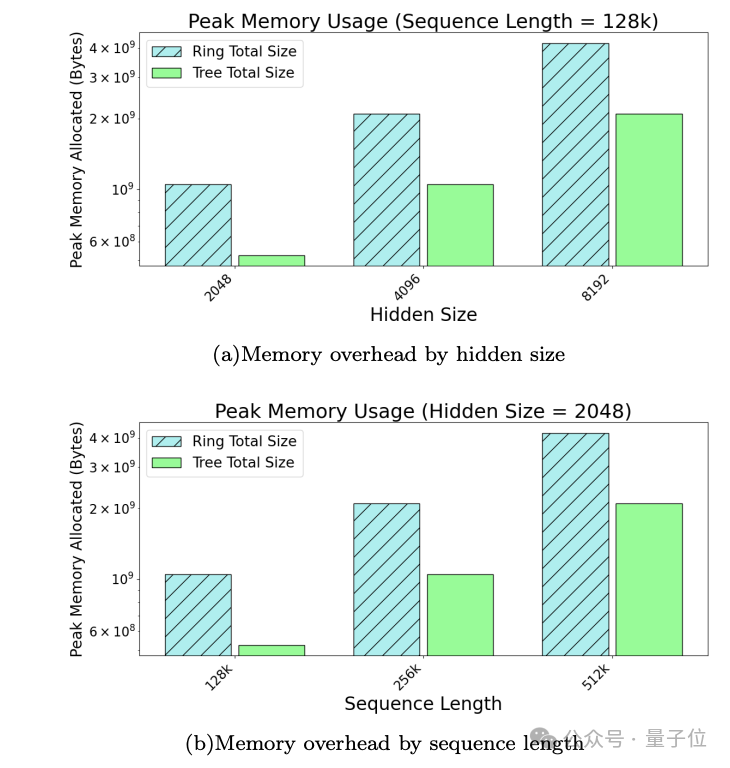
与环注意力相比,峰值内存占用也能节省不少。
相关代码已经开源,基于谷歌jax框架,已和Flash Attention整合,实现起来只需要30行代码。

论文一公布,就被业界评价为“对高推理需求的大型公司很重要”。

这下和黄仁勋的GPU“买的越多,省的越多”论对上了,英伟达再次赢麻。

注意力机制的能量视角
首先简单回顾一下这次被拿来对比的环注意力,由UC伯克利大牛Pieter Abeel团队提出。
环注意力被认为是让上一波大模型纷纷扩展到百万上下文的关键,从谷歌Gemini 1.5到后来的Llama 3.1系列都用了它的某种变体。

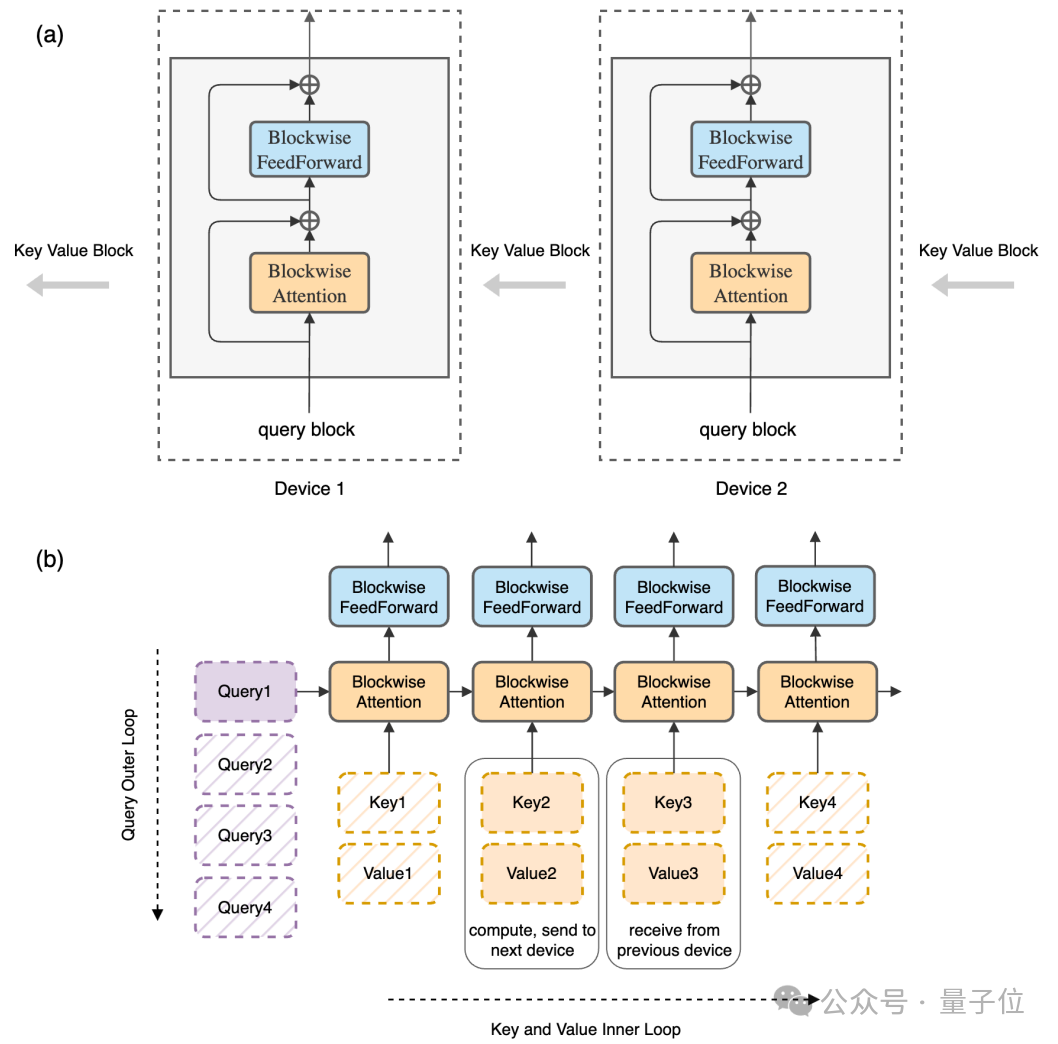
简单来说,环注意力的核心思想是将长序列分成多个Block,每个GPU处理一个。在拓扑意义上相当于所有GPU排成一个圆环,将Key-Value信息传下去,同时从上一个GPU接收信息。
只要保证计算时间比数据传输时间长,这个过程就不会造成额外开销。
同时与之前的近似方法不同,环注意力不会损失精度,保持了完整的注意力计算。
最新的树注意力,在分块计算、跨设备并行、保持精度特性的基础上,提出了一种自注意力的能量函数,通过计算梯度利用树形拓扑优化多GPU间的通信。
传统上,人们把注意力看作Query向量与Key向量的相似度匹配,再对Value向量做加权求和。
树注意力团队在Hopfield网络等基于能量的模型相关研究基础上,将注意力解释为一个能量函数对某变量的梯度。
存在一个标量能量函数F,它依赖于Key、Query、Value以及一个辅助变量ζ,而注意力的结果恰好等于F对ζ的梯度在ζ=0处的值。
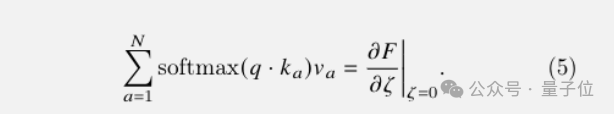
结合自动微分等技术,从能量和梯度的视角看待自注意力,暗示了只要能高效计算F就能高效计算自注意力。
具体到语言模型中基于KV缓存的解码,能量函数可以表示成:
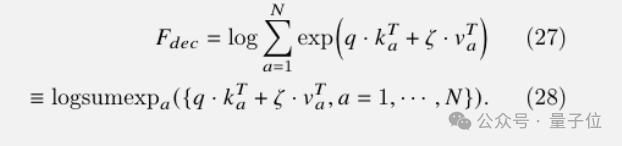
由于logsumexp和max运算操作都满足结合律,可以按任意顺序进行,而不会影响最终结果。
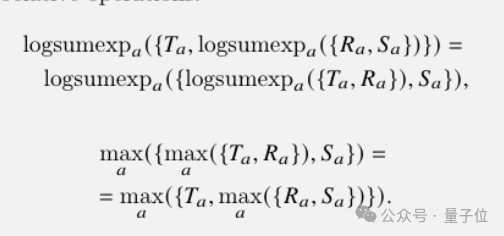
在此前提下,团队设计了新的并行化算法,先在各GPU上并行计算局部能量函数,再通过树状的Allreduce汇总各处结果,最后用自动微分取梯度,即可得到注意力的输出。
全过程仅需与计算能量函数相同的时间开销,而显存占用也几乎没有额外负担。
树注意力在设计上还充分利用了GPU集群的两级拓扑特点——即同节点内使用高速NVLink,而节点间则依赖IB或以太网等。
相比之下,环形注意力天然不适应这种拓扑,难以将通信与计算很好地重叠,终会被最慢的互联带宽所制约。
最后值得一提的是,虽然理论上单GPU内部也可用类似策略提速,但当前硬件的流式处理器(SM)间通信还是共享内存,优势并不明显。
不过,英伟达在H100上实验性地支持了SM间点对点的指令,这为未来单卡注意力优化带来了新的想象空间。
最被低估的AI实验室之一
树注意力团队主要成员来自Zyphra,一家新兴的AI创业公司,被评价为“当前最被低估的AI实验室之一”。

Zyphra重点关注边缘AI、端侧AI,曾发布基于Mamba架构的基础模型Zamba。
创始人Krithik Puthalath以及树注意力共同一作Vasudev Shyam、Jonathan Pilault都有数学和理论物理学术背景。

论文地址:
https://arxiv.org/abs/2408.04093
参考链接:
[1]https://x.com/ryu0000000001/status/1822043300682985642
[2]https://www.zyphra.com/post/tree-attention-topology-aware-decoding-for-long-context-attention-on-gpu-clusters
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~
















 20
20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









