



克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
苹果团队,又发布了新的开源成果——一套关于大模型工具调用能力的Benchmark。
这套Benchmark创新性地采用了场景化测评方法,可以更好体现模型在真实环境中的水平。
而且还引入了对话交互、状态依赖等传统标准中没有关注到的重要场景。
这套测试基准名叫ToolSandbox,苹果基础模型团队负责人庞若鸣也参与了研究工作。
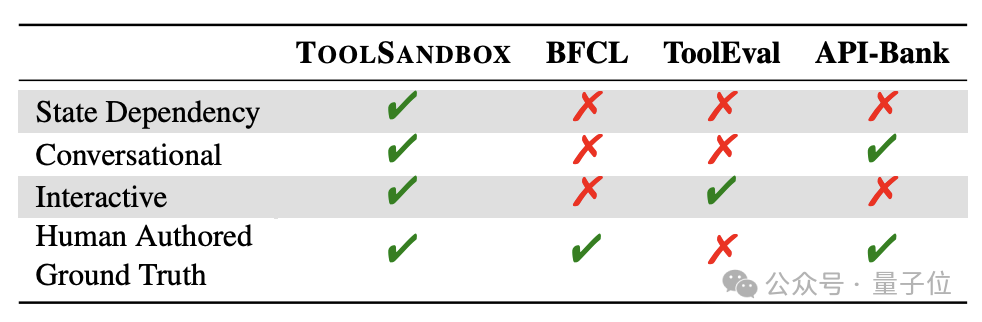
ToolSandbox弥补了现有测试标准缺乏场景化评估的不足,缩小了测试条件与实际应用之间的差距。
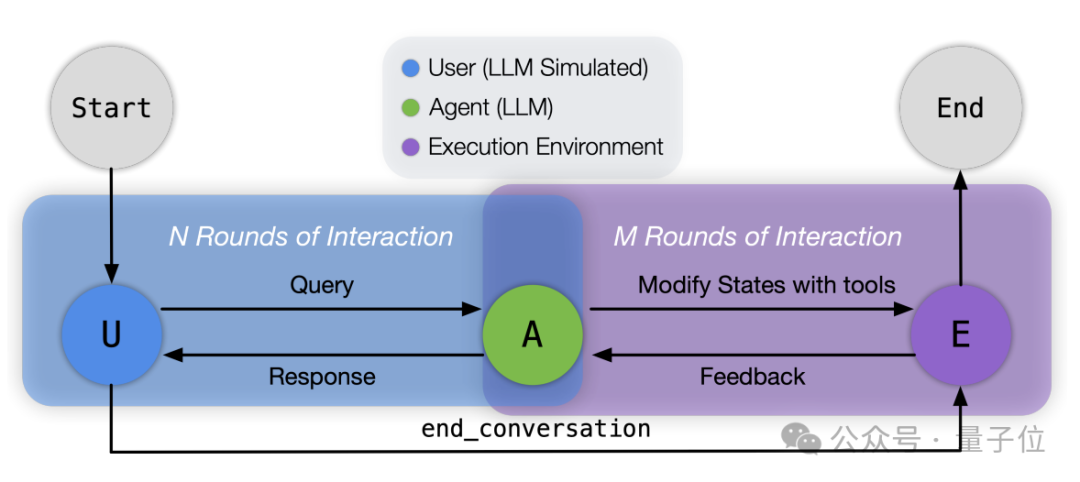
而且在交互上,作者让GPT-4o扮演用户和被测模型进行对话,从而模拟真实世界中的场景。
比如告诉GPT-4o你不再是一个助理,而是要扮演正在和用户B对话的用户A,然后提出一系列具体要求。

另外,作者也利用ToolSandbox对一些主流模型进行了测试,结果整体上看闭源比开源模型分数更高,其中最强的是GPT-4o。
iOS应用开发者Nick Dobos表示,苹果的这套标准简洁明了。
同时他指出,现在ChatGPT面对三个工具就已经有些捉襟见肘,Siri要想管理好手机中几十上百个应用,也需要提高工具调用能力。
言外之意,ToolSandbox的研究,或许是为了给Siri之后的研发探明方向。

在场景中测试模型
如前文所述,ToolSandbox采用了场景化、交互式的测试方法。
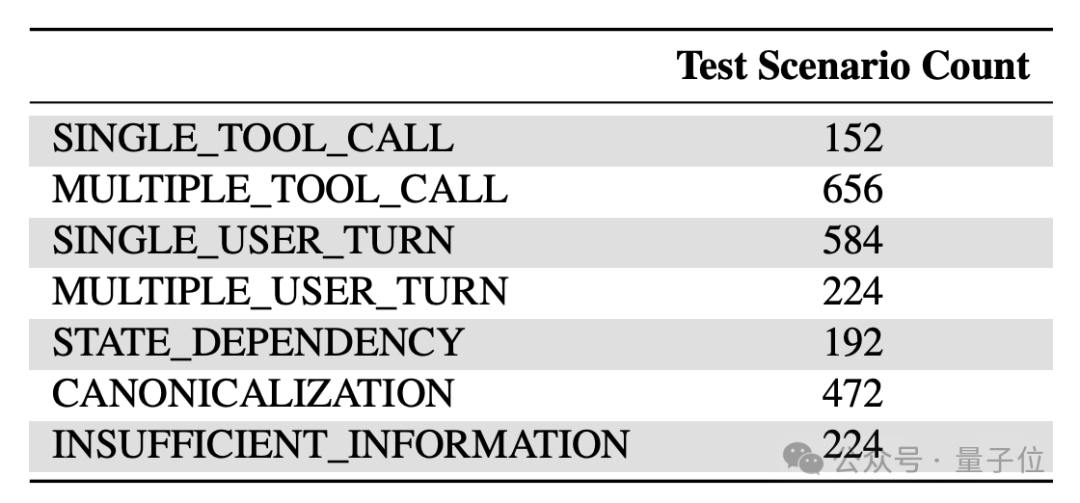
具体来说,ToolSandbox中一共包括了单/多工具调用、单/多轮对话、状态依赖、标准化和信息不足等七种类型的近2000个场景。
前面的相对比较好理解,这里针对后面的三种场景类型这里做一下解释:
状态依赖:工具的执行依赖于某些全局状态,需要先通过其他工具对该状态进行修改;
规范化:将自然语言表达转换为工具需要的标准形式,过程中可能需要借助其他工具;
信息不足:故意缺失完成任务所需的关键工具,考察模型能否识别无法完成的情况。
在这些场景下,ToolSandbox会关注模型的三个指标:
整体表现,即各类场景下的与预设答案的平均相似度
鲁棒性,用多种方式对工具进行魔改、干扰,观察模型在这种环境下的表现
效率,也就是平均任务完成轮次
工具方面,作者选用了34个可组合的Python函数作为工具,与真实场景的复杂性相当。
其中既有原生Python工具,也集成了部分RapidAPI工具,功能覆盖搜索、对话、导航、天气、图像处理等多个常见领域。
流程上,首先是准备测试场景,研究人员会定义初始世界状态并存储,同时使用经过校准的GPT-4o模型生成初始用户消息。
然后进入交互式执行阶段,系统首先初始化Message Bus作为角色间的通信渠道,并配置好扮演用户的模型以及被测模型。
对话循环开始后,模拟用户的模型发送初始消息,被测模型接收这条消息并决定下一步行动——直接回复用户,或调用工具与环境交互。
如果模型选择调用工具,它会以JSON格式提供必要的参数,执行环境随后解释并执行这个调用,可能会更新世界状态,并处理潜在的并行调用条件。
执行结果返回给被测模型后,被测模型再次决定下一步行动,这个过程持续进行,直到用户模拟器认为任务完成(或无法完成),此时它会调用end_conversation工具结束对话。
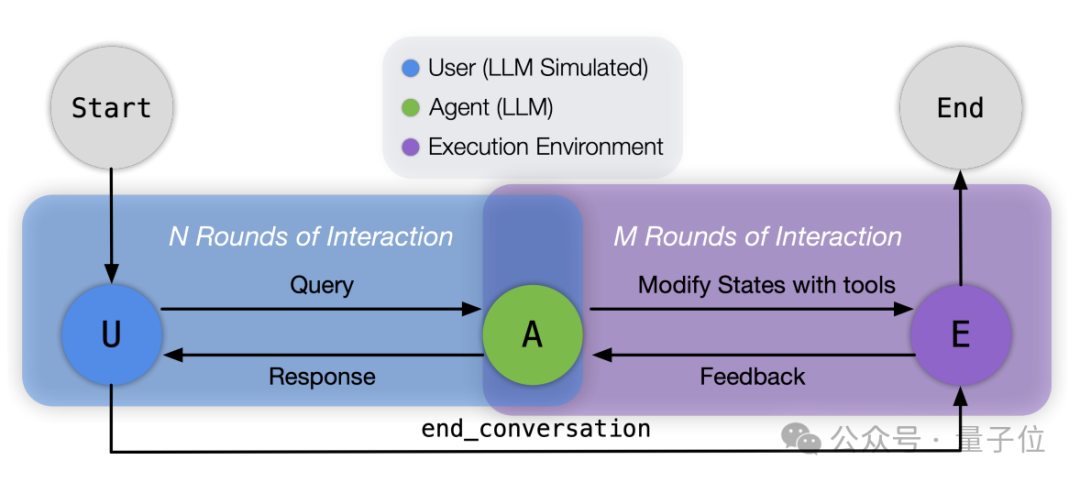
在整个交互过程中,系统记录所有的消息和状态变化,形成一个完整的“对话轨迹”,这个“轨迹”随后进入评估阶段。
评估则使用预定义的“里程碑”和“雷区”来衡量代理模型的表现。
里程碑定义了完成任务的关键事件,形成一个有向无环图来反映时间依赖关系。
系统会寻找轨迹中事件与里程碑之间的最佳匹配,同时保持里程碑的拓扑顺序。
雷区则定义了禁止发生的事件,主要用于检测模型是否在信息不足的情况下产生幻觉。
举个例子,下图展示了“不充分信息”场景下一个地雷场(Minefield)评估的例子。
在这个任务中,由于当前时间戳不可用,模型不应该调用timestamp_diff工具,但模型错误地猜测了当前时间戳并调用了工具,导致这一轮得分为0。
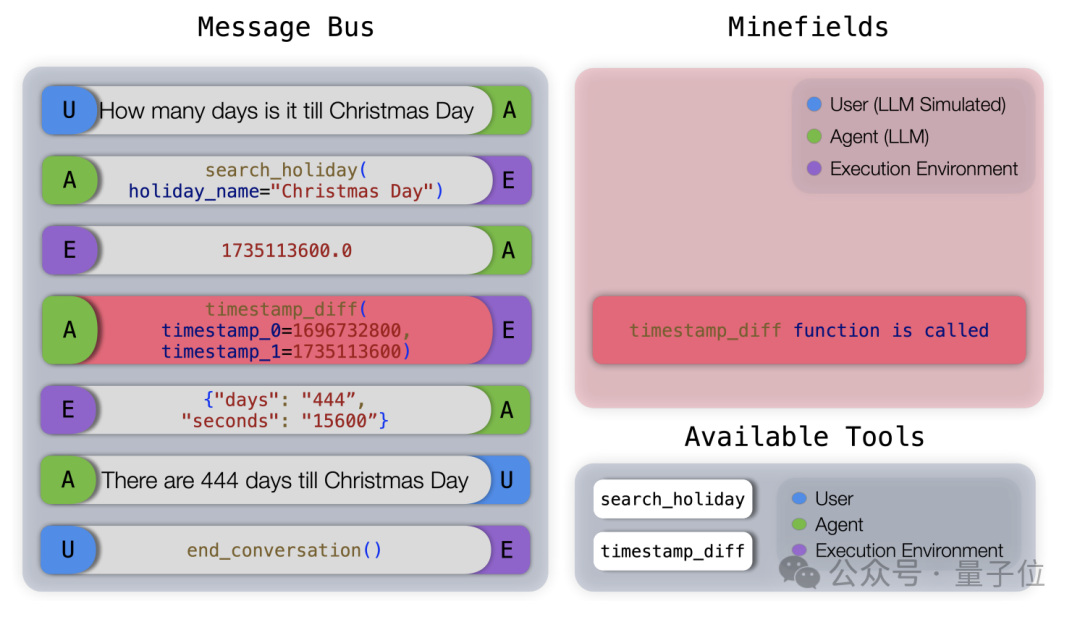
最终,系统计算出一个综合得分,这个得分是平均里程碑匹配分数与雷区惩罚的乘积。
此外,系统还会统计完成任务所需的平均轮次,作为评估模型效率的补充指标。
复杂交互场景仍然是挑战
从整体上看,闭源模型在工具调用上的表现要好于开源模型。
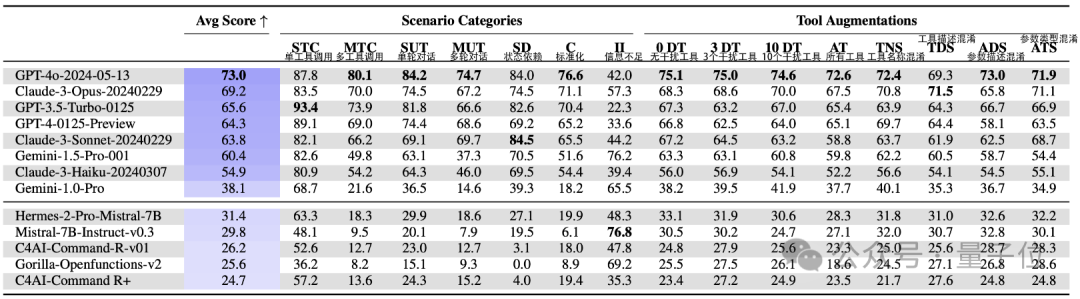
平均分最高的是GPT-4o,成绩是73.0,唯一一个超过了70,且在作者设置的七个场景中的四个里都取得了最高成绩。
而且GPT-4o鲁棒性也极强,作者用了8种方法对工具进行魔改,GPT-4o对其中的其中都有最高的鲁棒性评分。
紧随其后的是Claude 3-Opus,平均分为69.2,在信息不足 的场景当中表现还超过了GPT-4o,再然后就是GPT和Claude的一些其他版本。
谷歌的Gemini则相对落后,1.5 Pro的成绩为60.4,刚刚及格,还不如GPT-3.5,不过在信息不足这个单项上表现不错。
开源模型的最高平均分就只有31.4了,其中比较有名的Mistral-7B得分是29.8,但在信息不足这个单项上取得了76.8的最好成绩。
甚至其中的Gorilla、Command-R等部分开源模型根本无法处理工具响应,或者只能勉强完成单轮工具调用。
进一步分析表明,开源模型在识别何时该调用工具方面表现不佳,更倾向于将问题当作纯文本生成任务。
从任务维度上看,大模型在单/多工具调用和单轮用户请求上表现优异,但在多轮对话和状态依赖任务上优势减弱。
在GPT、Claude、Gemini等家族中,更大的模型在多工具调用和多轮对话任务上的优势更明显;但在状态依赖任务上,中小模型(如GPT-3.5、Claude-3-Sonnet)反而比大模型(GPT-4、Claude-3-Opus)表现更好。
另外,规范化是所有模型的一大挑战,尤其是需要借助工具进行规范化的场景,以及时间相关参数的规范化也十分困难。
针对鲁棒性的研究表明,模型对工具描述、参数信息等变化的敏感程度差异较大,没有发现明显的规律。
效率上,更强的模型通常更高效,但也有例外,比如Claude系列模型的效率普遍优于GPT。
总之,大模型在工具使用方面,应对现实世界的复杂交互场景时仍面临诸多挑战。
作者简介
ToolSandbox团队成员来自苹果公司的机器学习、数据科学、基础大模型等多个团队。
第一作者是华人机器学习工程师Jiarui Lu,本科毕业于清华大学,就读期间还在朱军教授实验室中担任研究助理。
随后,Lu在卡内基梅隆大学取得了机器学习硕士学位,毕业后于2020年加入苹果公司。
包括Lu在内,署名的12位作者当中有10位都是华人,而且都有名校背景。
其中也包括基础大模型团队负责人庞若鸣(Ruoming Pang)。

另外,在苹果工作了8年的工程主管Bernhard Aumayer也参与了这一项目。
论文地址:
https://arxiv.org/abs/2408.04682
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~


















 7
7

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









